Hi Team,
We are using Zeebe 1.3.4 on self managed mode with below configurations:
Cluster size: 3
Partitions count: 12
Replication factor: 3
Gateway version: 1.3.4
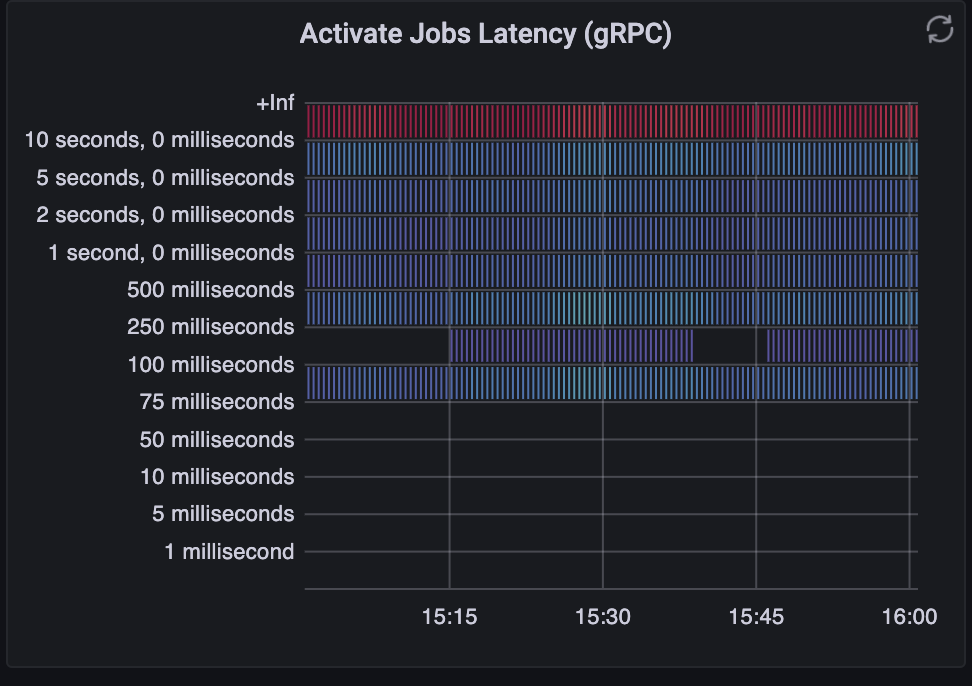
We are observing high latency in ActivateJob requests as can be seen in below screenshot
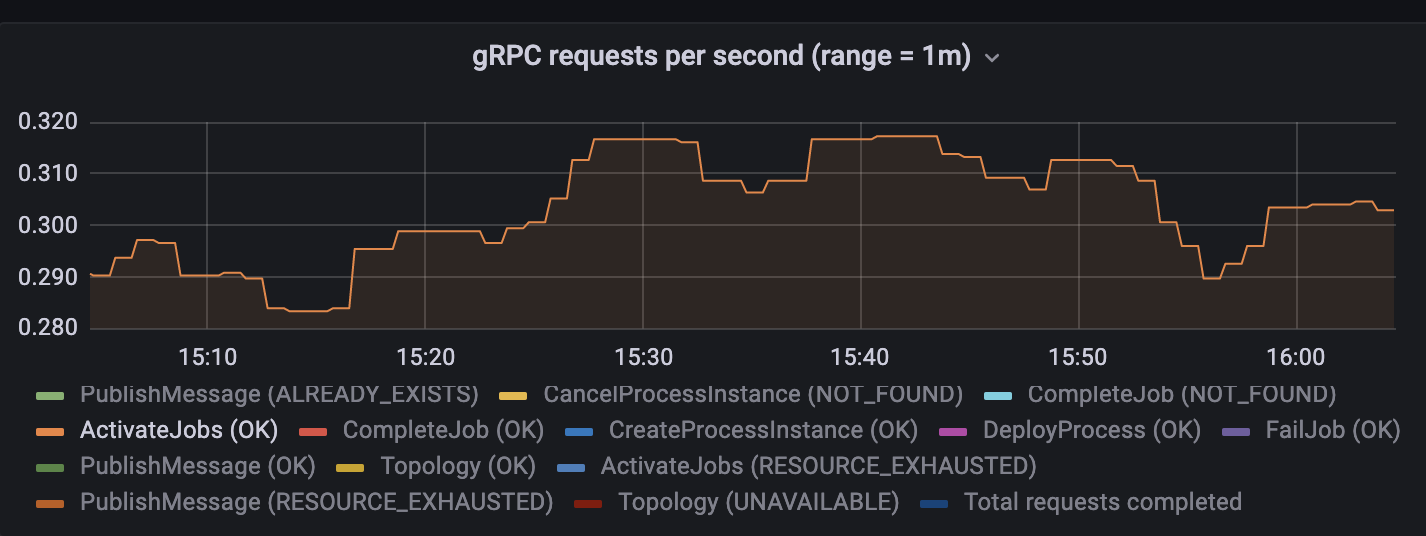
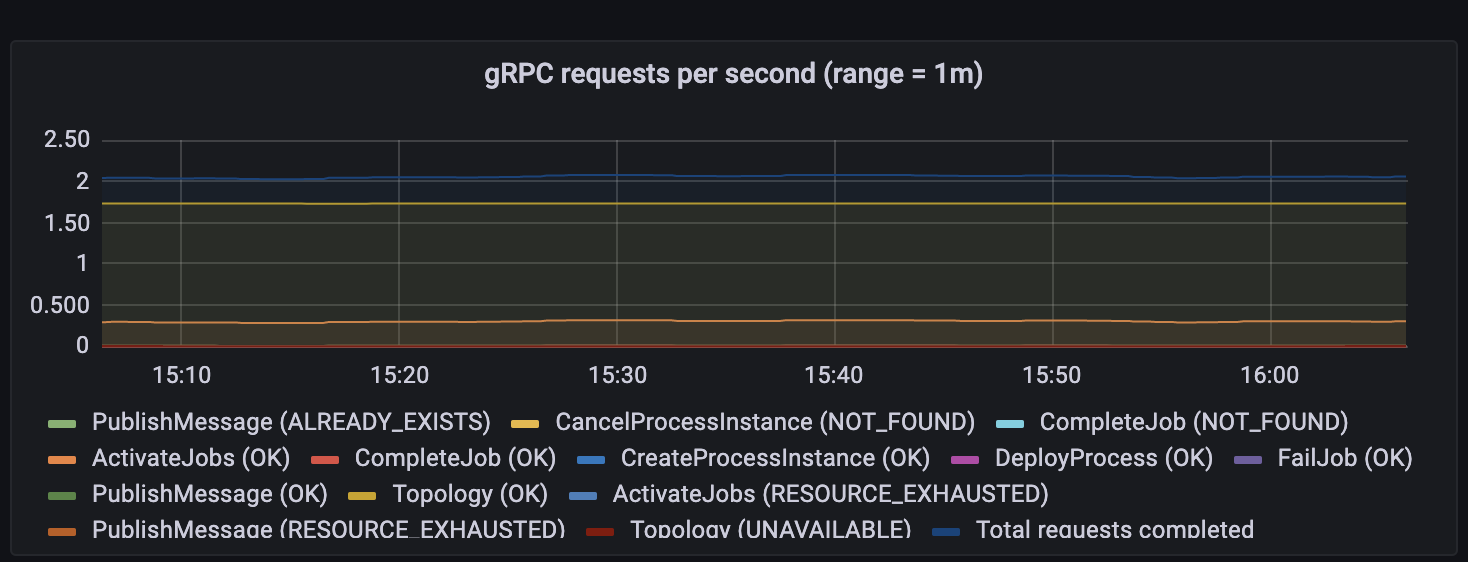
The request rate is very low - less than 1 gRPC request per second for activate job
Total gRPC requests to gateway are less than 2 per second
Appreciate some help on fixing it.
Hey @ankit_joinwal
the high job activation latency could be because of long polling and timeouts. If you create a worker which should request jobs at the gateway it will keep the connection open if there are not enough jobs on the zeebe side. Per default, the connection (long-polling) timeout is 10s, after that the connection is closed and the worker (client) retries after the poll interval and sends another activation request. If still there a no jobs then it waits again until the timeout.
Based on this may I ask do you have enough jobs to activate and complete? What is the configurations of your job workers?
Greets
Chris
Hi @Zelldon
Thank you for the response. We currently have very low process instances as you can see because we haven’t launched the product feature on prod which will create more process instances.
Speaking of the workers, the workers are actually a couple of Zeebe Kafka connectors, below are the configurations
{
"name": "source-connector",
"config": {
"connector.class": "com.chegg.kafka.connector.zeebe.ZeebeSourceConnector",
"job.kafka.topic": "<<replaced>>",
"job.variable.correlation.key": "subject",
"errors.log.include.messages": "true",
"tasks.max": "1",
"zeebe.client.requestTimeout": "10000",
"zeebe.client.job.worker": "jobA",
"zeebe.client.job.pollinterval": "2000",
"zeebe.client.worker.maxJobsActive": "100",
"key.converter.schemas.enable": "false",
"cloud.event.format.enable": "true",
"zeebe.client.job.timeout": "5000",
"value.converter.schemas.enable": "false",
"zeebe.client.gateway.address": "<<replaced>>",
"name": "source-connector",
"errors.tolerance": "all",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"errors.log.enable": "true",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"job.types": "sendMessageJob",
"zeebe.client.security.plaintext": "true"
},
"tasks": [
{
"connector": "source-connector",
"task": 0
}
],
"type": "source"
}
I can see the timeout as 10 seconds. Can you suggest some best practice to keep for these configurations?
Hey @ankit_joinwal
makes sense.
Why you would do this, I mean adjust the configuration now? I would suggest you do it if you face any issues. I don’t see that this has currently an impact on your system execution or? It is just that the metrics show that.
Greets
Chris
Our workflow has 2 tasks currently . And the 10 second timeout is adding to the overall process completion time. We are seeing an average process execution time ~ 20 seconds. The workflow task itself takes ~ 4 seconds.
Hey @ankit_joinwal
thanks for your response, so you see an impact.
I would suggest first to upgrade to a more recent version, ideally 8.x. If this is not possible than at least to a higher patch version. We fixed certain bugs related to job activation, see for example Make activated jobs which were not send to clients re-activatable · Issue #3631 · camunda/zeebe · GitHub This might be related to your issue as well.
Greets
Chris