Hello guys, i missing Cancel End Event on my Camunda BPMN Modeler, my camunda modeler version is 1.5.0, how about u guys?
1 Like
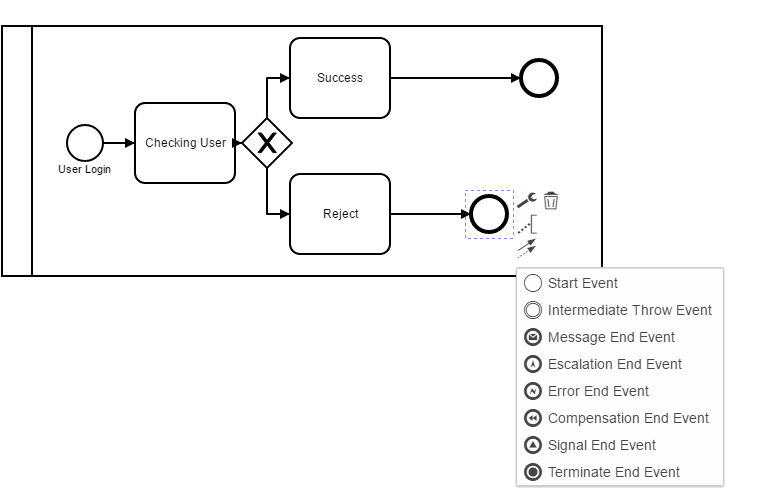
Help me guys how to make cancel end event and use intermediate event on boundary task? when i try to use intermediate on boundary task it was disable on camunda, please help
The Cancel end event is only valid within a Transaction so will not appear otherwise:
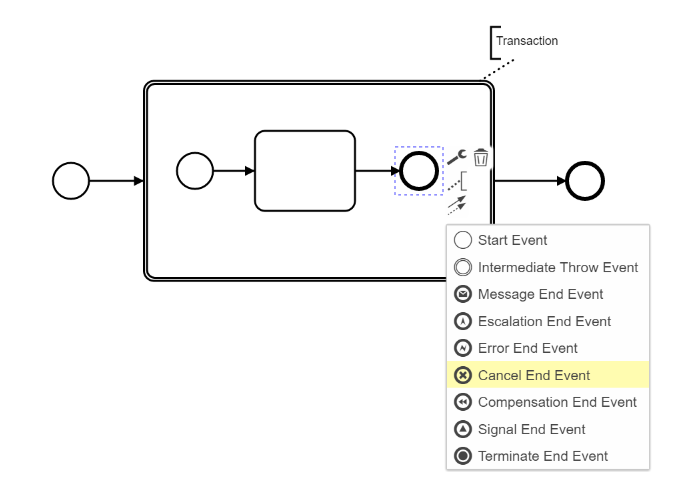
1 Like
Thank you sir, how about Cancel Intermediate Event ? i try to find on transaction subprocess but i cant find it ? i see on bpmn reference on camunda cancel event function : You can use the cancel event only in the context of the transactions.
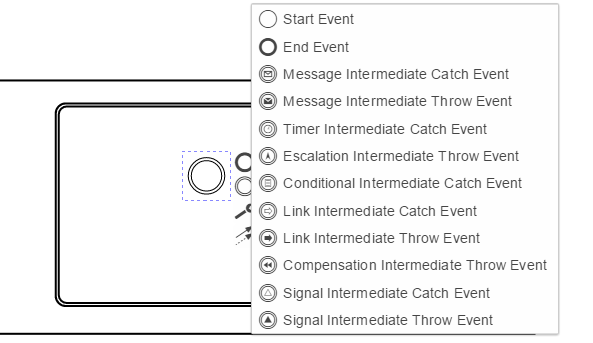
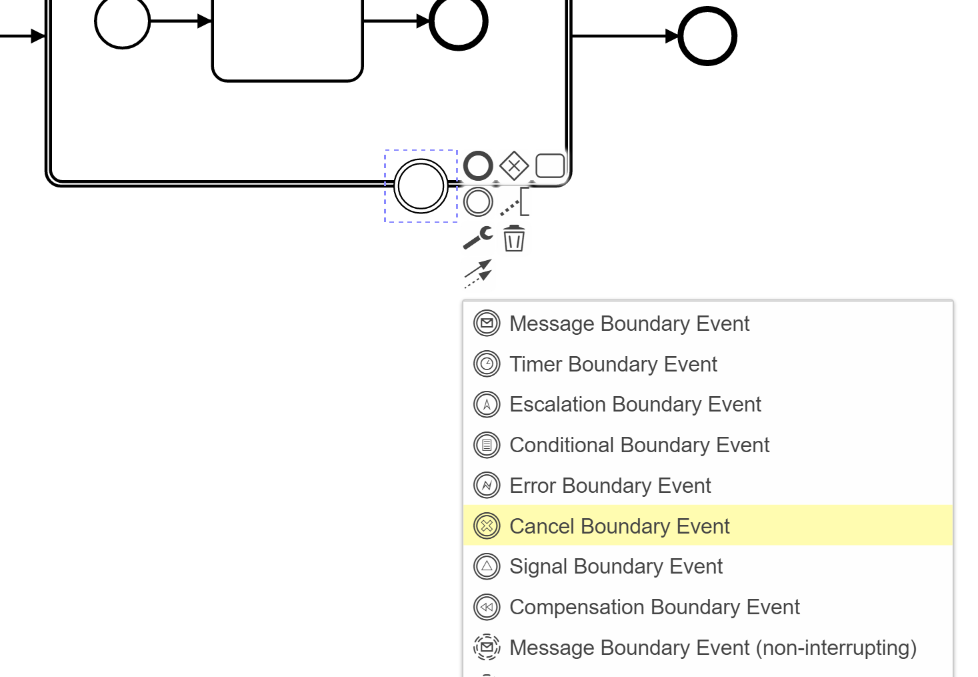
The Cancel catch event is always a boundary event and so must exist on the boundary of the transaction.
Because of the way which a Cancel event is thrown it doesn’t exist as a standalone intermediate event.
Thanks Niall, can i ask u again something about this ? 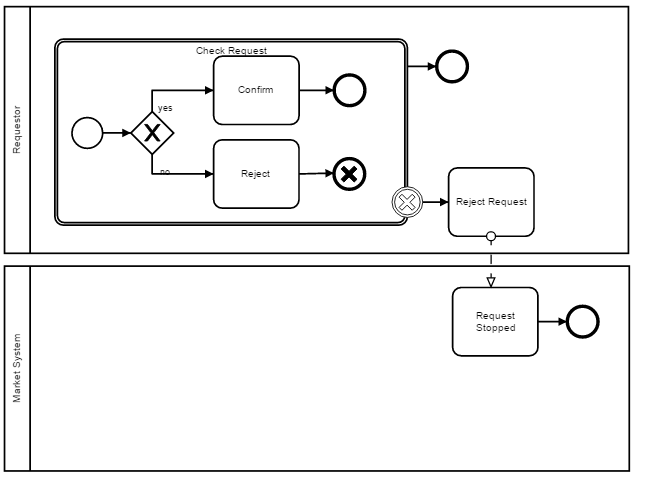
First Question : can i draw sub proces after event/task?
Second Question : after sub process should i continue with sequence flow to event/task ?
Third Question : is it right about draw Cancel intermediate event on transaction like that? the scenario is :i want the request reject and sistem stop the request from requestor.
Hi Matchalattea,
I don’t think you’re use case requires the cancel event - the cancel event is used in conjunction with the compensation event. youre case does not require any kind of roll back.
I think all you would need is to use a message event like this:

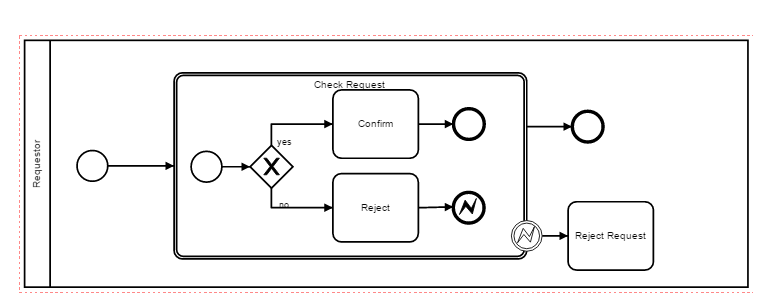
Just one small change - change the subprocess from a transaction to a regular sub process
Thanks again Niall, i already finish my model and then i check it on businessprocessincubator, then i got message “BPMNShape coordinates are required to be positive.
Reference: Participant_0tap0wn”
what’s mean ? and how to fix it?
its done thanks 