The data contains parents and children. A child can turn up anywhere in the file as shown above. It may not necessarily come exactly after its parent. Also a child relates to its parent through the prefix_id (i.e. ‘AZ’ in this case). So in this case I know that James and Alex are both Jim’s children based on their common prefix_id.
If I need to process a parent with their children and keep a “state” of how many of a parent’s children I have processed, what can I do? So when a parent is encountered in the workflow, can zeebe some how keep track or “state” of how many of that parent’s children have been processed. When I encounter a parent, I want to be able to wait for their children to be processed with them.
Is message correlation the thing that I am after or it will not help me?
cheers
Hi all. Is the scenario not clear? I just want to know if Zeebe is capable of this or not.
Currently, because for every parent and child file a new instance is created, I do not believe I can use message correlation between them as they are separate instances.
So I think I need to send each file as a message like attached photo and do aggregation that way.
I am struggling to find documentation on how to start with a start message in java. Any help would be appreciated. In the meantime, if anyone has any comments on whether I am missing something or any help, please let me know.
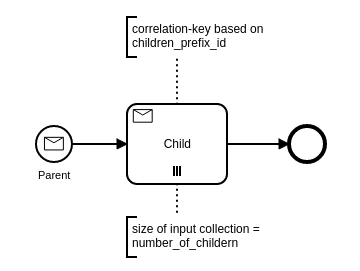
I think that you could use some kind of message aggregation pattern. For example, like the following process:
The process instance is started for every parent. It collects all children based on the number_of_childern and children_prefix_id of the parent message.
As suggested by Josh, the parent and the children can have different message names to have a clear correlation.
If the child messages are published with a TTL then they can be published before the parent message is correlated.
Does this work for you?
Do you have a different solution?