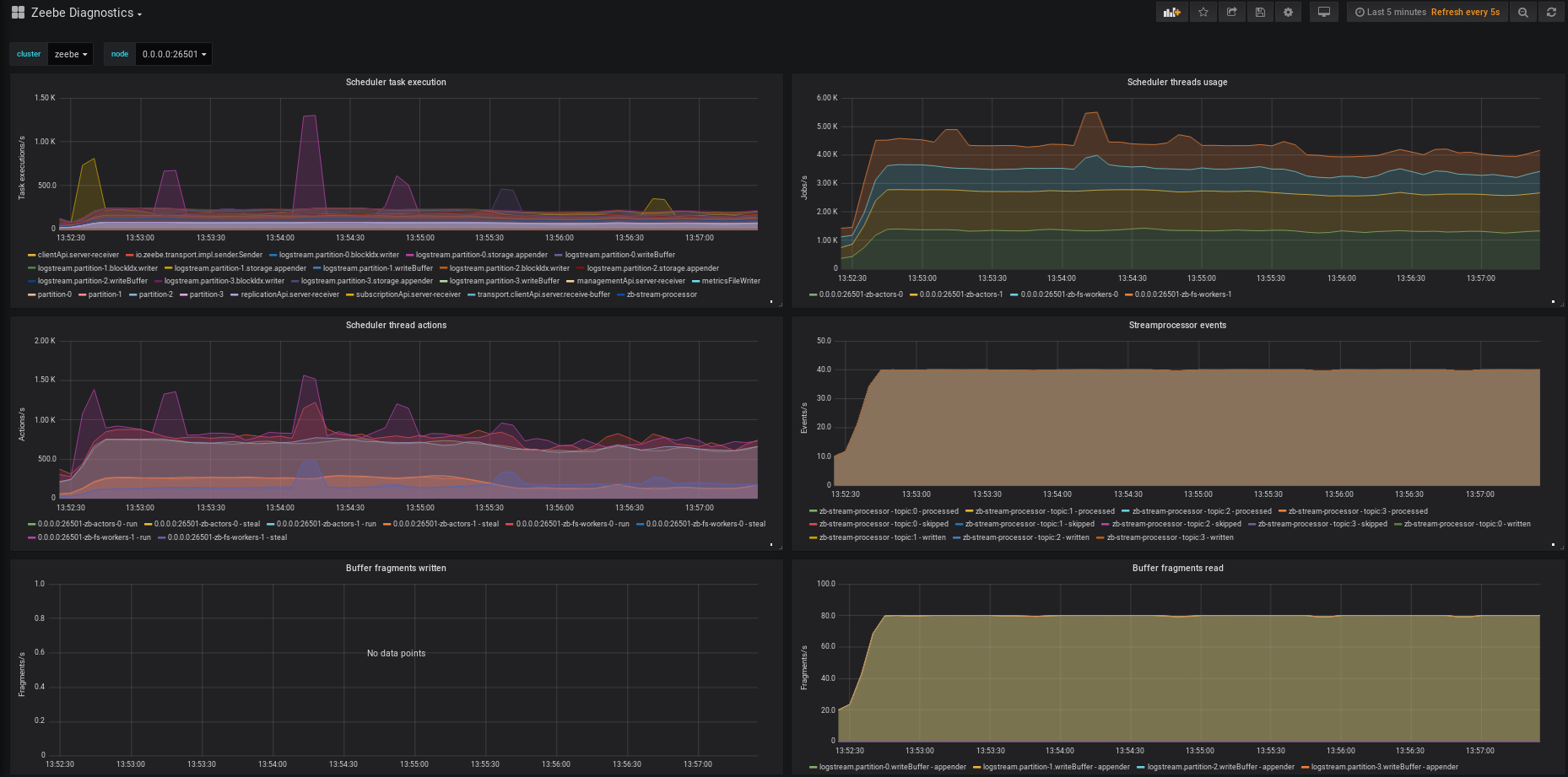
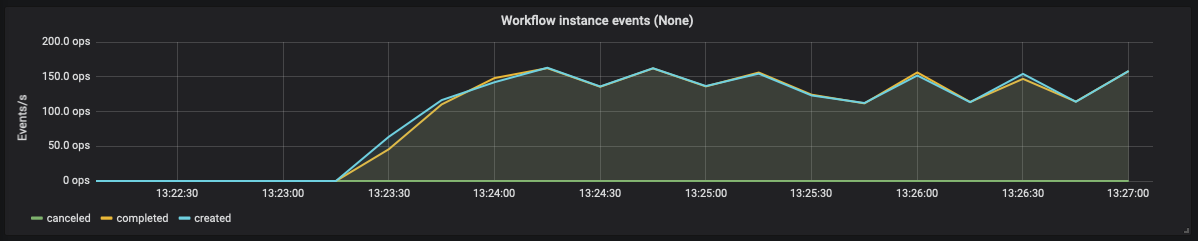
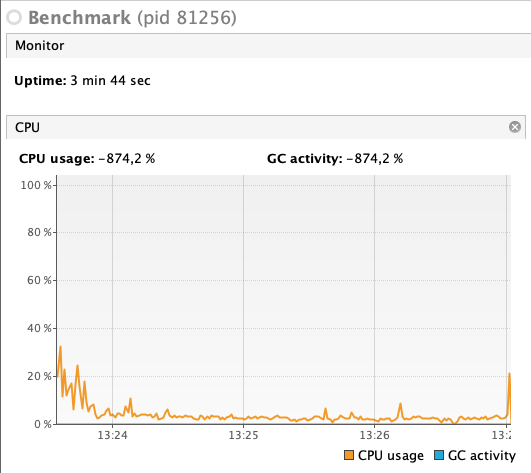
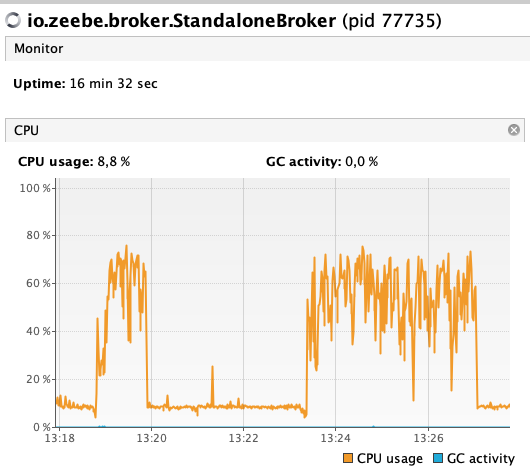
while I tried some things with Zeebe (single broker and few worker on my notebook), I noticed that a broker with no active instances produces quite a high cpu load at around 5-20% (probably depending on my zeebe.cfg). When I start many parallel workflow instances, the load of the worker nodes is very low but the broker produces all the load. And I can see only around 200 workflows instances per second on my i7, which is less than I expected.
I can confirm your observation. 200 completed workflow instances per second on a single broker is similar to our performance tests with Zeebe 0.17.0 . You could tune your benchmark a bit (e.g. partition count, CPU threads, job polling, etc.) but you can’t increase the throughput significantly (e.g. of a factor of 10). However, you can build a cluster of brokers to balance the load. This is how Zeebe can scale
Regarding the const CPU load, this is caused by the job workers. We are aware of the problem and want to work on it in the feature.
Do you have any specific throughput you need to reach?
Can you use a cluster to reach your goals?
Do you have any specific throughput you need to reach?
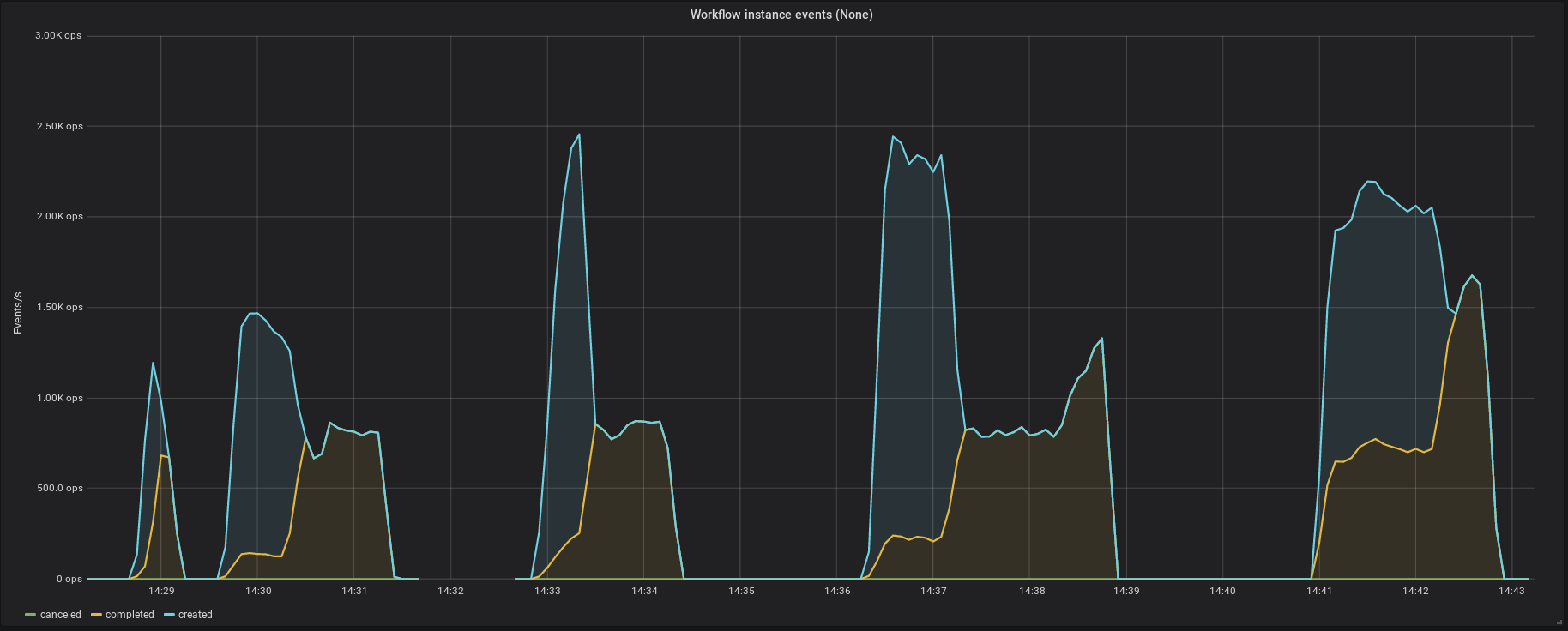
No, not a very specific right now. I was hoping to reach the 32.000 workflows per second like you did in the Benchmark last year. To be fair: Even with 200 “transitions” per second Zeebe would be ~100x cheaper than AWS Step Functions. But 32.000/s would be very tempting.
Can you use a cluster to reach your goals?
Do you have any recommendations for a cluster? Many very small instances, like t3.small or a few larger, like t3.xlarge?
In the benchmark, it measures only the created workflow instance. You can create more instance than completing it. To complete instances, you need to poll jobs, complete jobs and process until the end event. So, it is a lot more to do
I don’t have any experience. I would assume that it also works on a smaller machine. However, if you have more power then you can do more
Yes, the load is related to the (gPRC) job polling. Currently, the worker poll jobs constantly, even if there are no jobs. This could be improved, for example, using long-polling, back off, or job subscriptions.