Hi all,
let’s assume we have two process applications deployed as two war-files on a jboss server.
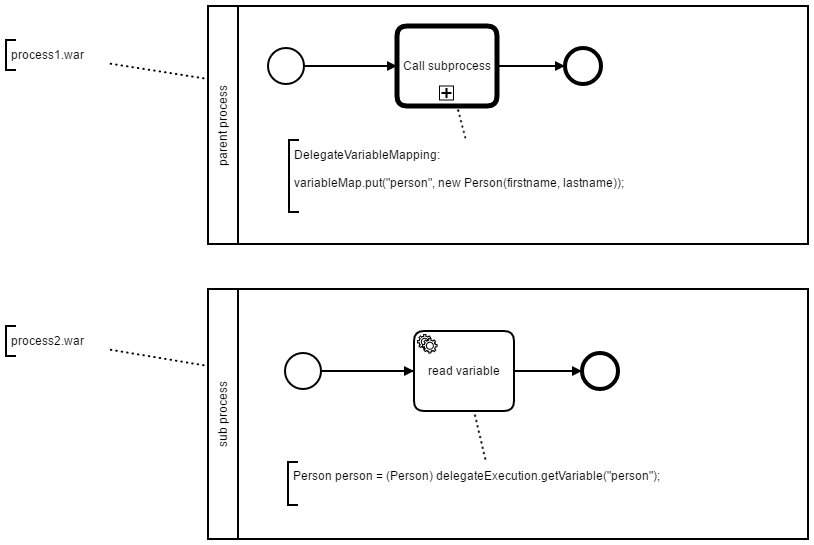
The parent process has a call activity to start the subprocess. But we want to hand over some (structured) data to the subprocess, so we implement the DelegateVariableMapping interface and add an object of type “Person” (just as an example). The domain class “Person” is located in a common jar file which both applications have in the compile scope (as maven dependency).
The subprocess has a service task where this variable is read. Here we will get a ClassCastException because the “Person” class of the variable instance handed over by the parent process is loaded by a different class loader as the “Person” class of the subprocess. Hence the clash…
Well, the most obious approach is to serialize the variable and hand it over as JSON/XML.
This can be done manually but then we need a deserialize-task/listener at the beginning of the subprocess. But maybe this subprocess is also started via a webservice interface. In this case, we would not get a JSON string but the ready to use java object…
We can also insert some wait-state (asyncBefore=true) before the variable is read for the first time - then the persistence layer of the engine will serialize the object, write it to the DB, read it from the DB and deserialize it with the class of the subprocess. This would fix the exception but maybe we need a synchronous feedback of the subprocess and cannot add this wait state…
So I am looking for a platform-wide solution to not have to deal with this problem in each process application. Any suggestions?
Thanks!
Sebastian