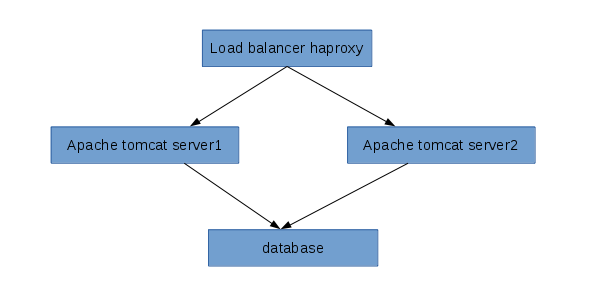
I am trying to apply load balancer concept in camunda server, I found this link but I need some implementation example like how to create shared database, I mean what are the place I need to change database configuration (e.g $TOMCAT_HOME/conf/server.xml). how to maintain the session?
you don’t need to share the session in the tomcat servers. Every command like startProcessInstanceByKey() or complete() will change the database before it replys to the caller. So you can start the process instance on tomcat1 and complete the first task on tomcat2.