Hi @DanielMeyer
I want currently logged in camunda userid in my own ejb. How can I get this?
Hi Anik,
Therefor you can use “IdentityService#getCurrentAuthentication()”. This returns an authentication object, where you can call “getUserId()” which returns the currently logged in user. You should be able to inject the “IdentityService” in you own ejb.
Does it help you?
Cheers,
Roman
Edited:
Hi @roman.smirnov
We have already used this. Here is the code snippet:
When we run it, we are getting a NullPointerException!!
Hi,
you must null-check the current authentication - the process can be run without any authenticated user, for example, if you are running unit-tests. We are seeing the authenticated user when a process is started through tasklist.
Best regards,
Thomas
In addition to the answer given by @skjolber:
The method will only return a not-null value if IdentityService#setAuthenticatedUserId (or similar methods) was called before. This is implemented in the Camunda web application via a servlet filter (see AuthenticationFilter and the code it calls). That means whenever your code is triggered within a request made by the Camunda web application, you should be fine.
If you use the REST API directly or use a custom application to invoke the process engine API, this is not the case by default. Then you’ll have to call the identity service method yourself. In this case, make sure to ALWAYS call IdentityService#clearAuthentication after the API invocation.
Cheers,
Thorben
Hi there,
I’ve been facing the following issue,
In my process, an array of 6 users has to select products from a list.
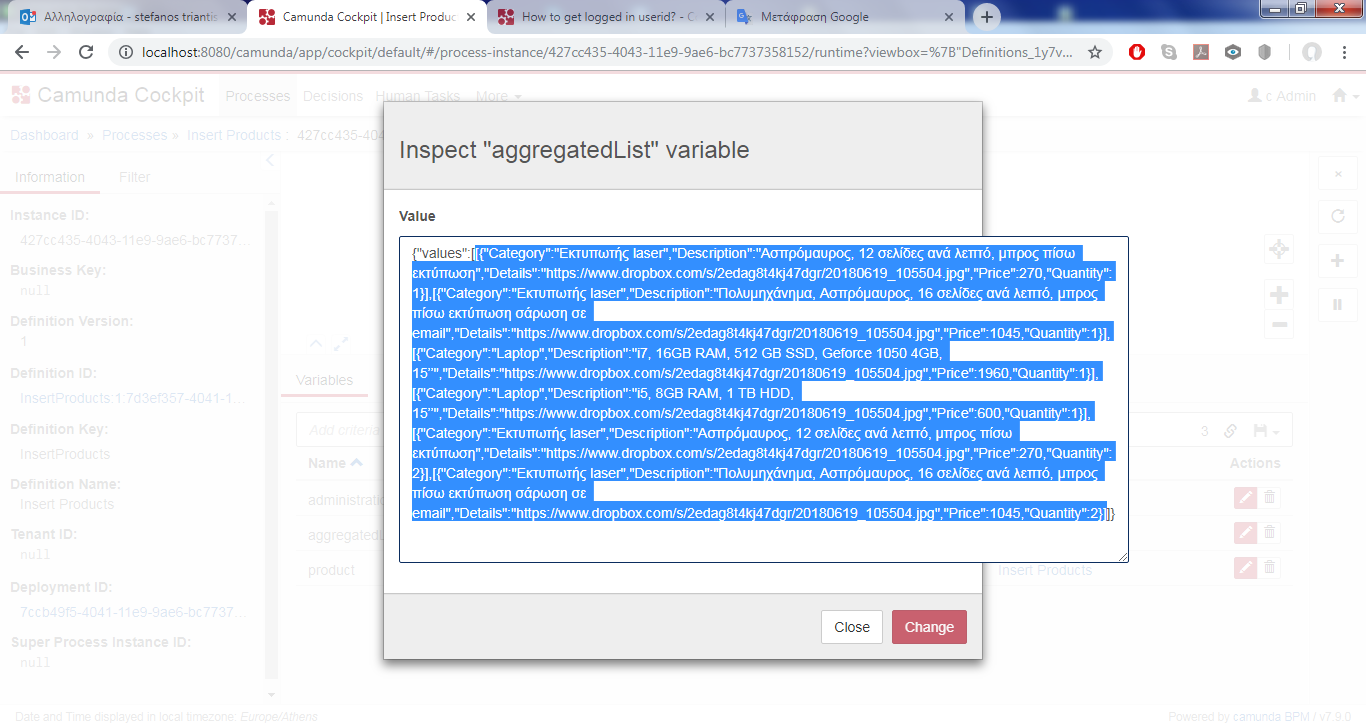
Each user appends his selected products to the same json array (I’ve named it as “aggregatedList”) and finally this variable contains the products from all of those users.
My issue is that in the inspection of this json variable (“aggregatedList”) in Cockpit I would like to keep also the information what products each user selected and not only the selected products.
I could attach here my stuff if necessary for anyone interested.
Thank you in advance,
Steven
Hi Steven,
As I understand your question, you want a way to link the choices to the user. The community version does not contain the history of the processes.
However, you could store the userId and their selected products as a key-value pair in your JSON.
Does this help with your problem?
Best Regards
Martin
Hi @martin.stamm,
Yes, exactly!
I want to link usernames with their respective choices 
I can’t exactly understand what you mean by saying “does not contain the history of the processes”.
Could you please explain a bit (or by an example maybe) how could I apply your suggested way (of the storage as a key-value pair in my JSON variable) ?
Thanks a lot,
Steven
Hi Steven,
thanks for clearing that up. In general, the username is also the UserId. To get First- and Last Names from an ID, you can use the REST API or the IdentityService
That’s a reference to features we offer in our enterprise product.
Instead of a simple array, you could create a JSON which looks like this:
{
"user1": ["item1",
"item2"],
"user2": ["item1"],
...
}
Could you provide more information about your process? How do you currently create the JSON?
Best Regards
Martin
Hi again @martin.stamm and thanks a lot for your interest ![]()
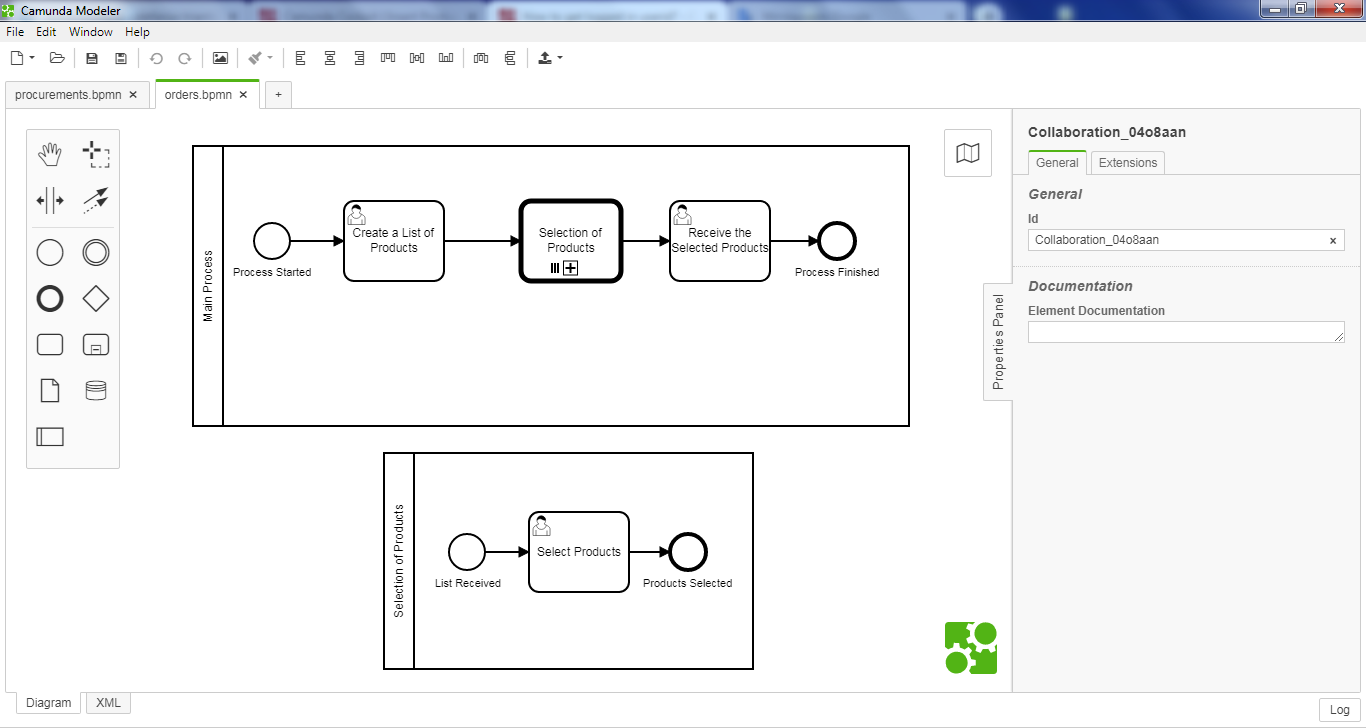
My process is the following one:
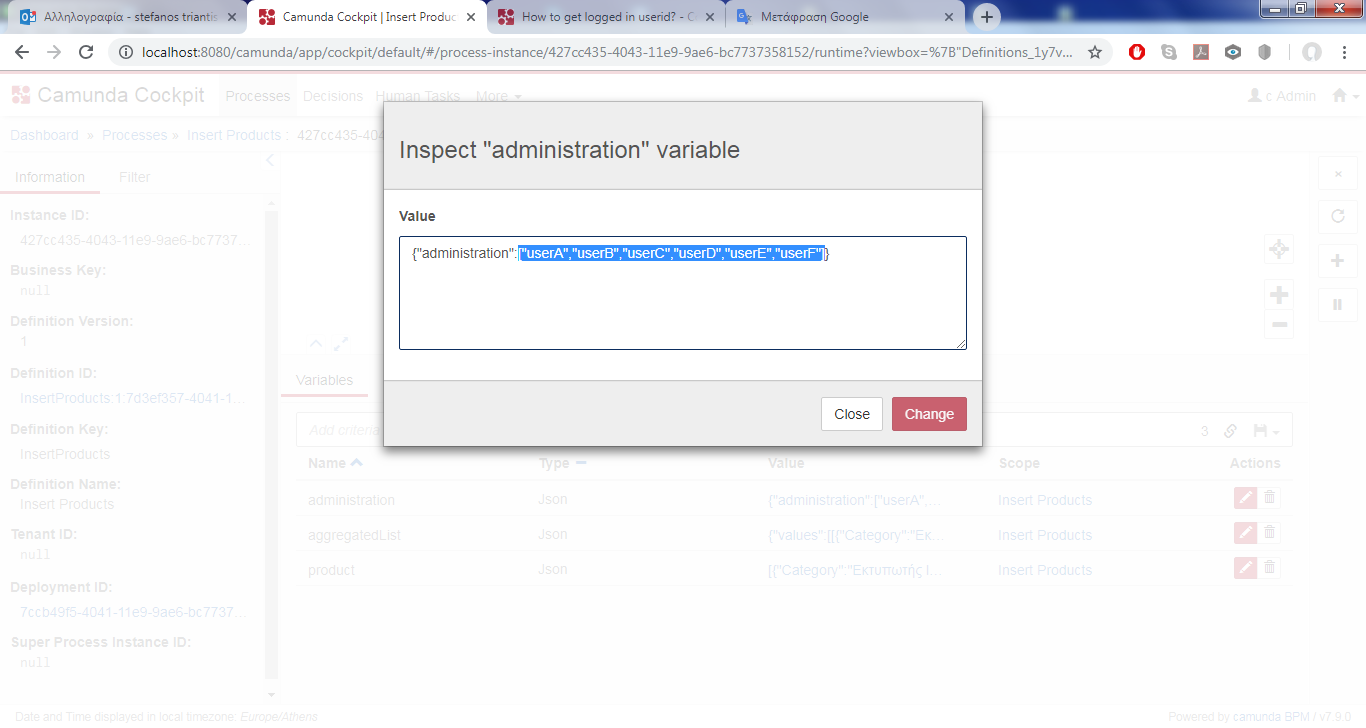
If you take a look in the Script of the End Execution Listener at the 1st task (“Create a List of Products”), you can see that I’ve set an array of 6 users (with the name “administration”) and a variable (with the name “aggregatedList”) which is going to include the appended choices from these 6 users.
Both of these 2 variables are set as SPIN JSON.
Each one of these 6 users appends his selected products into the “aggregatedList” during the Subprocess (“Selection of Products”). If you take a look in the Script of the End Execution Listener at the task (“Select Products”), you can see that.
In Cockpit, I can see all the selected products which are appended in the “aggregatedList” but not also which products each user selected.
I also uploaded here my bpmn file in case you want to check sth in my relative Scripts.
orders.bpmn (8.0 KB)
Could you please guide me a bit towards this direction ?
Thanks a lot,
Steven
Hi Steven,
If you don’t mind changing the structure of you JSON, you can recreate my proposed data structure.
Simply change what you append in Select Process > End Listener accordingly. If you use a Task Complete listener, the task.assignee variable will be set.
Let me know if this helps and if you need further advice.
Best Regards
Martin
Hi again @martin.stamm,
Could you please explain a bit how could I change my following Script (in the End Execution Listener of the “Create a List of Products” task) with your proposed (above) JSON data structure in order to get in the “aggregatedList” variable the usernames with their selected values ?
var administration = S('{ "administration" : ["userA", "userB", "userC", "userD", "userE", "userF"] }');
execution.setVariable("administration", administration)
var jsonValue = S('{ "values" : [] }')
execution.setVariable("aggregatedList", jsonValue)
Thanks a lot,
Steven
Hi Steven,
this is how I would approach this issue:
create a List of Products TaskSelect Products like this: aggregatedList.prop(task.assignee, selectedProducts)
let me know if this works for you.
Best Regards
Martin
Hi @martin.stamm,
If I’m not mistaken, in my following script here, the JSON “aggregatedList” is empty.
var jsonValue = S('{ "values" : [] }')
execution.setVariable("aggregatedList", jsonValue)
Could you please confirm that?
Many thanks,
Steve
Hi Steven,
in your script, the JSON will have the prop "values": []. Change jsonValue to S('{}') for an empty JSON.
I think we are drifting a bit from the original topic. If you want to discuss implementation details further, I suggest you shoot me a private message.
Best Regards
Martin
Dear @martin.stamm,
I’ve sent you a private message as I ran again my process model (with your proposed changes above) but for some reason, I’m taking a server error. 
Please let me know in case you manage to check something in my attached files there.
Many thanks for your time,
Steven