Hello,
We want to setup Camunda in order to process our computation tasks using workers that are notified through messaging (JMS or similar).
We see two choices:
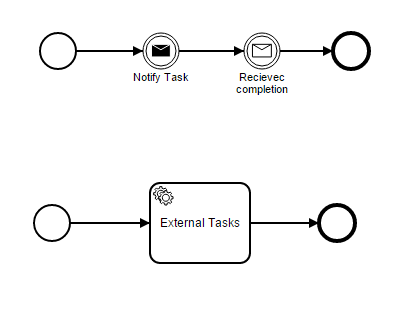
The first using a classic BPMN style with send and receive messages.
It has various flaws:
- Business work is not explicit
- Could not leverage on Camunda retry/incidents facilities to handle worker runtime failures
- Could not leverage on BPMN Error to handle business errors
So we are seduced by the second option: the External Tasks Pattern.
All the benefits described in the documentation of the External Tasks Pattern are exactly what we try to reach.
But it seems that External Tasks Pattern is made for: HTTP + Polling.
If we want to use it with messaging the API has some flaws:
-
Our “new task” message is send in the start listener of the external task.
There the External Task object is not yet created so we can’t notify the External Task Id. We have to use the Execution Id (which can be linked to multiple External Tasks??).
We could not find any better hook for the “new task” notification. -
The API does not allow to complete the task without locking it first.
In our case, we rely on the messaging middleware to handle the lock/unicity.
There is also no way to explicitly lock a task given its external id (or execution id).
We manage to find a way through those issues writing an extended ExternalTaskService, but it feels like we are missing something.
This blog post says that External Tasks Pattern is a good option to “replace JMS queue between the Service Task and the Service Implementation”.
Great news! But what is a good implementation if I like the pain of the messaging architecture?