In the documentation there exists the following paragraph:
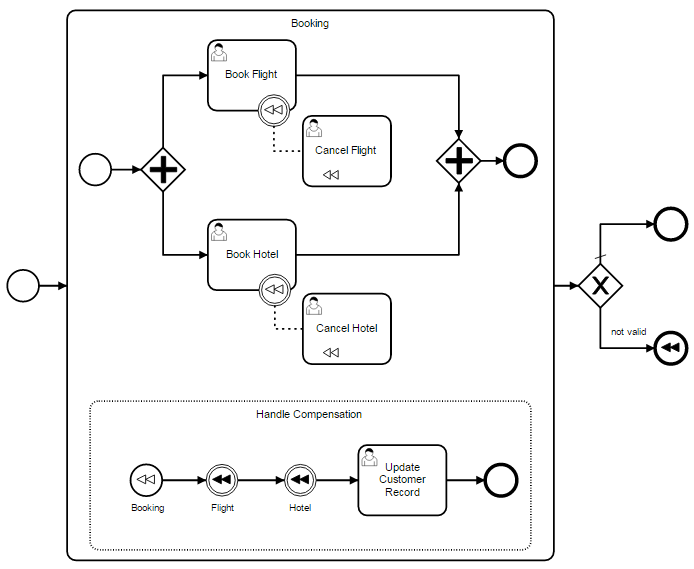
Contrary to a compensation boundary event attached to a subprocess, a compensation event subprocess consumes a thrown compensation event. That means, activities contained in the subprocess are not compensated by default. Instead, the compensation event subprocess can recursively trigger compensation for activities contained in its parent.
Below is the following process definition, which indicates that in the event subprocess, first it triggers compensation for the Flight task and then for the Hotel task.
My question is, how does the Intermediate Throwing Compensation Event references the task to compensate? It seems that the activityRef property of the Intermediate Throwing Compensation Event can be used for such case. But if I reference the tasks, I get an error from the process machine during deployment.
ENGINE-09005 Could not parse BPMN process. Errors: ↵* Invalid attribute value for ‘activityRef’: no activity with id ‘compensation1’ in scope ‘SubProcess_0v1tsrc’ | process.bpmn | line 31 | column 72↵* Invalid attribute value for ‘activityRef’: no activity with id ‘compensation2’ in scope ‘SubProcess_0v1tsrc’ | process.bpmn | line 37 | column 72
In my case, there exists activities with the IDs compensation1 and compensation2. The Activity Ref dropdown in the properties panel of the Intermediate Throwing Compensation Event lists also the ID’s available in my subprocess.
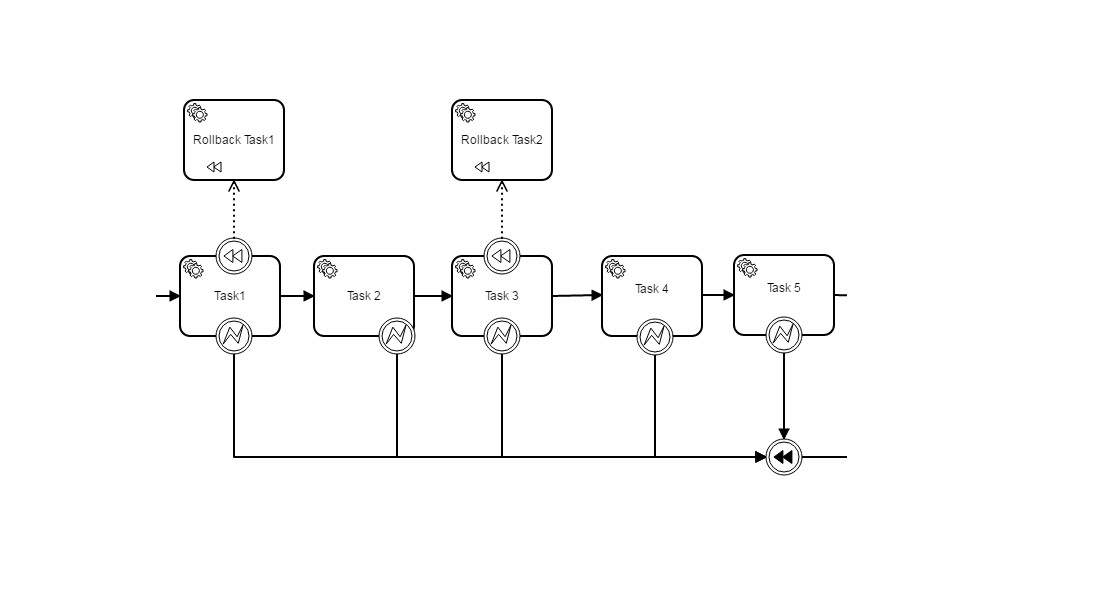
I am trying to do the following flow, but every time I get an exception it rollsback to the first task, it does not rollback in opposite order. Does anybody know how to implement this?
You are right. Reverse order is implemented based on timestamps. It may happen that tasks are executed in the same recorded time instant (due to timestamp precision being to coarse). In that case, reverse order is not guaranteed. I created a bug ticket: https://app.camunda.com/jira/browse/CAM-7461. To verify this, you could artificially slow down your service tasks and check if reverse order works then.
Hi Thorben, I have put breakpoints in my tasks and waiting at least one minute in each task and in the same way the reverse order for compensation activities not works correctly. Do you have any other suggestion? I´m concluding that for this type of activity the compensation mechanism will not work adequately. Thanks for your help!
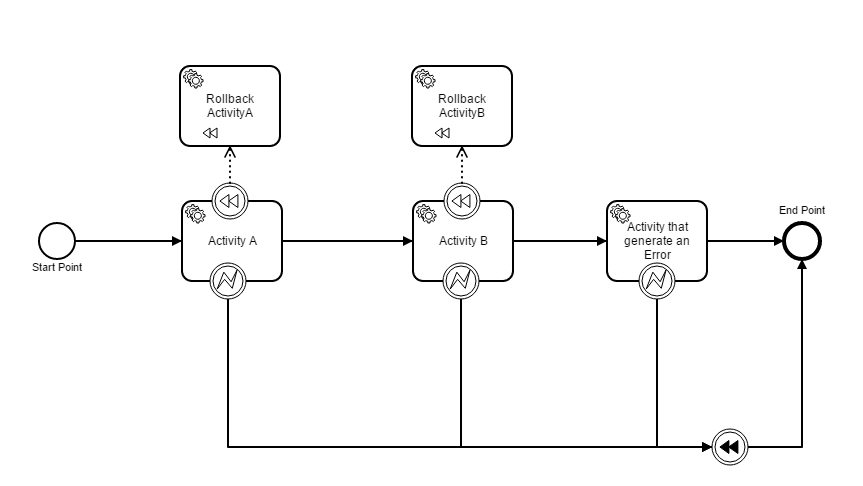
Hi Thorben! I have got to reproduce the problem in my local machine. I have created a simple BPMN like showed below and the compensation activity continues not executing in reverse order. I have add a ten second sleep thread inside each activities in order to try to mitigate timestamp problem but not successful, same incorrect execution compensation order, first Rollback ActivityA followed by Rollback AcivityB.
You can follow inside Tomcat console that the order is incorrect. I could not put the image here because the Forum restrict me to make this like new user :-(.
Follow the complete project to you verify and try to help me:
Hi Thorben, thank you so much for your response. I debugged the above scenario and slowed down the execution, and Task1 executes lineal before Task2, and Task3, so timestamps are different, and when there is an exception at Task5 Camunda always executes ‘Rollback Task1’ first and after '‘Rollback Task2’. So, I am guessing the bug in Camunda is not only about timestamp. Thank you so much for opening a bug ticket. I will share with you the xml file, so you can take a look and let me know if I am missing anything in the flow. I am using Camunda Modeler 1.6.0. Thanks again, Cristela
Thanks for providing the code and uncovering this bug. In fact, the engine performs compensation in forward instead of reverse order and I am amazed that we currently do not test this case as part of our test suite