Hi,
There is a requirement to handle exception on activity level say, if any exception(BPMError) occure in service task , we need to retry the same task configurable amount of time after configurable amount of timer(say 10sec).
Once retry is successfull, it should resume the workflow execution.
Since we are forced to use venilla camunda, I cant write java code here.
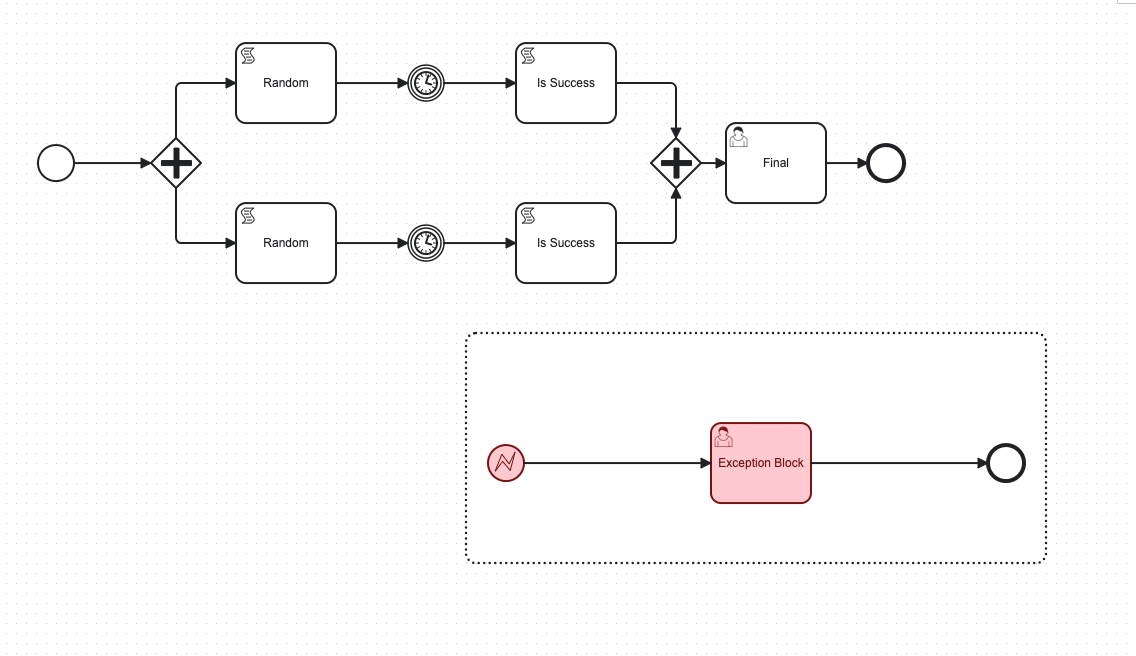
I was trying with event subprocess(with error start event) but this will create issue when we have parallel gateway(as given below). Here we suppose to get 2 token for subprocess but we get only one.
Is there a way to design this with much less effort(Dont want to touch each and every activity for this)
Thank you in advance
Sample.bpmn (12.6 KB)
Some things to keep in mind about Event Subprocess…
It basically behaves like wrapping the entire process in a task, and attaching boundary events to it.
So, in your case, since you used an Interrupting Start in your event subprocess, ALL the tokens in your process get cancelled, and move to 1 token in the “Exception Block”
If you used Non-Interrupting Start in your event subprocess, the tokens wouldn’t be cancelled, BUT a new one would be created (so then you would have 3 tokens until the “Exception Block” was cleared).
2 Likes
Hi @GotnOGuts
Thanks for the details but there is no non-interrupted error event inside event sub-process. if I use message event(non-interrupt), I believe process execution will continue which is not the case I wanted. So Im not getting what’s the best way to handle this situation. Can you please suggest?
Specifically on how to handle retry mechanism when we have Parallel or inclusive gateways.
You can simply wrap your entire process in an expanded subprocess and attach an interrupting error boundary event for catching errors which will loop back to start of the expanded subprocess. Keep in mind that this can create an infinite loop, so you might want to add some condition on the loopback to keep track of the loops and kill it in case of infinite looping
By definition, you will only get one.
When the Interrupting Subprocess is triggered, all the other tokens are canceled.
The only way around this is to catch the errors on each task. You can group “Reason → (timer) → Is Success” in a single subprocess and catch the error on that subprocess, deal with it, allowing the other subprocess to continue.
Hi @GotnOGuts
Thank you for the response, but I’m not clear on
You can group “Reason → (timer) → Is Success” in a single subprocess and catch the error on that subprocess, deal with it, allowing the other subprocess to continue.
Can you please provide sample/dummy workflow or explain in detail?
Regards,
Anoop
Hey @camundabpmlearner,
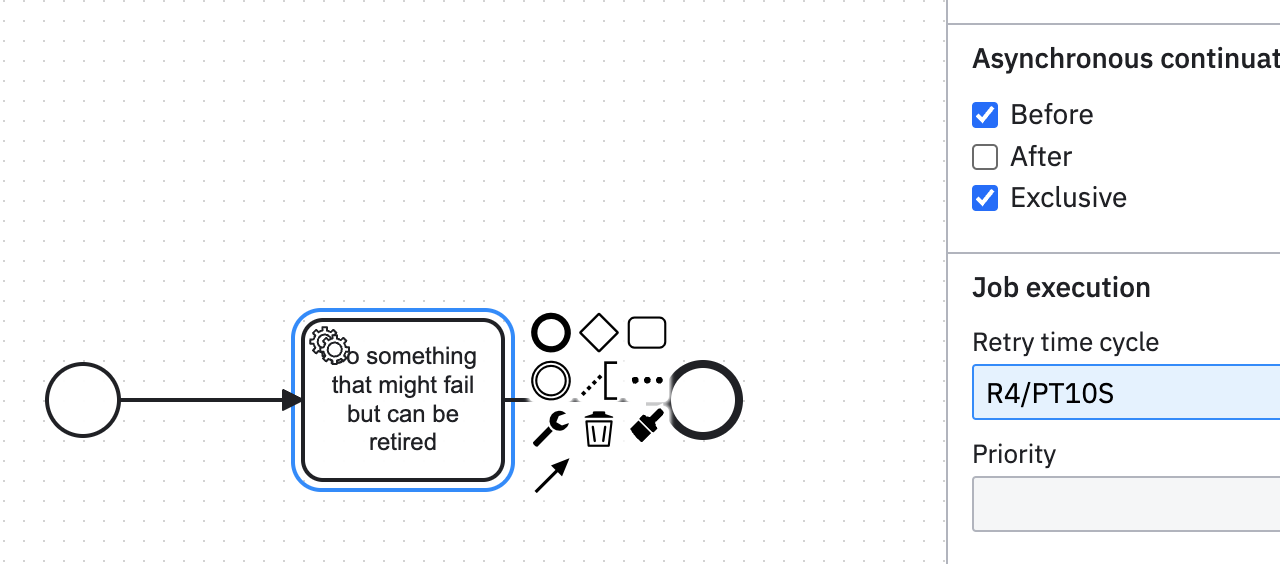
Another approach to consider - rather than pursuing a global (BPM) exception handling approach via explicit modelling why not consider using Camunda job retry mechanism for your service tasks - this might be a more appropriate and easy way to handle these failures if they are transient and the expectation is they will succeed after retrying.
Place an async continue before your service tasks and configure your retry behaviour. Example below retries 4x at 10 second intervals…
Some things to note:
- Throw normal java exceptions (not BPM errors) - this will trigger a rollback of the current engine transaction and a retry of the service task as described above
- Whatever your service tasks are doing will most likely need to be idempotent as certain types of failure (e.g. a network timeout) will leave your task unsure if the remote work has been done or not.
- Consider what you want to happen if the problem persists beyond your retries - what does this mean for you business process - should you stop everything if one leg of your process is not completable etc?
- I think it should be possible (although I have not tried) to apply a hybrid approach where your service task implementation throws exceptions but identifies when the retry limit is about to be reached and then throws a BPM error to trigger whatever BPM error handling you have modelled. Again, you’d need to decide what to do at this point. Retry the entire process (as @JohnArray suggested) or fail the whole thing gracefully (applying some compensations if necessary).
- If the retry limit is reached, the engine will raise an incident against your process instance and it will be paused. Look in cockpit.
Hopefully this helps!
1 Like
Hi @herrier
Thank you for the response, I have already considred this approach, the concern with this approach is, on each async encounter, engine will communicate with DB which impacts the performance if we enable this feature on most of the task.
Hey @camundabpmlearner, have you confirmed your concerns about performance by testing? On the face of it, like the others, I can’t see an obvious way to model this using a single error event handler in the manner of the model in your post, because the execution of the process cannot just “re-join” at the activity that generated the error in the first place.
You could look at using the process modification APIs but it’s not recommended for a process instance to mess with itself.
If it were me, I’d get something working correctly first and then benchmark it’s performance and then look at how it might be optimised. You might be surprised what you find.
3 Likes
Hi @herrier ,
Yes, as of now I have considered 3 different approaches for now:
- By using simple sequence lines & decision gateways
- By using event sub process
- By using Async continuation.
Need to test which one is optimal by performing tests.