Hi, we have a job which being kicked off every hour (let’s call it Generator), and it can have one or more tasks (i.e. external task in Camunda) being launched, depending on number of input files being generated. In the end, after all input files for that specific day have been processed, it’ll kick off a final job (let’s call it Aggregator), which will aggregate all computation results done by previous jobs. The way it’s currently implemented in our POC using Camunda is something like:
Start → [Generator-sub-process] → Wait-for-Aggregator-task-message → Run-Aggregator → End
Inside [Generator sub-process], there are 2 flows shown parallel on the modeler:
Wait-for-Generator-task-message → Run-Generator-> End
Start → Wait-for-Final-Generator-message → End
In this case, the client will periodically (i.e. 1 hour) sends Generator-task message, until the last input file encountered, which then it sends Final-Generator message (after the last Generator-task-message being sent).
At this point, Client will send Aggregator-task message, but it failed in this case because there is still Generator task running (it’s not exiting from [Generator-sub-process] yet) and return this error:
“org.camunda.bpm.engine.MismatchingMessageCorrelationException: Cannot correlate message ‘AggregatorTaskMessage’: No process definition or execution matches the parameters”
I am thinking either of these 2 options as workaround:
Client periodically send Aggregator-task message, and if failed, then it means there is any Generator task still running, so it’ll try again later
Our Aggregator task already has logic to wait for corresponding Generator task to be done (this may not be best practice), so in this case I’d still like to see Client is able to send Aggregator-task-message, since it knows all Generator tasks for that day have been submitted
Can you tell me how to achieve option #2 from Camunda modeler? Basically, can Camunda kick off another process instance, even the process instance in proceeding flow is still running?
Thanks!
Does the process know how many files it needs to process when it starts? Or are the files added throughout the day and there is some sort of “message” sent indicating all files have been sent and to begin processing the aggregate?
Where does the aggregate come from? Is this data already stored in the process from returned data to the process when a external task completes?
The Generator job will process 1 input file, but within that 1 hour, we could have one or more input files.
The job that creates those input files, will know what is the last input file, that’s why Client should be able to know which is the last file when kick off the Generator job.
To answer your question, the Client will kick off the Aggregator job, and yes, it’ll just process the data in back-end db, stored by Generator jobs earlier. The bottom line is we should only kick off Aggregator job when all Generator jobs are done. However, since Client just submit request to kick off Generator job async, then it doesn’t know when all of them are done. That was the reason we put the logic in Aggregator to check if any of those input files (we know already when it kicked off) are done or not, I don’t say this is ideal though.
Now from Camunda model perspective, Client can’t send message to kick off Aggregator, it failed (see the error I mentioned previously) because likely there is still one or more Generator job(s) still running.
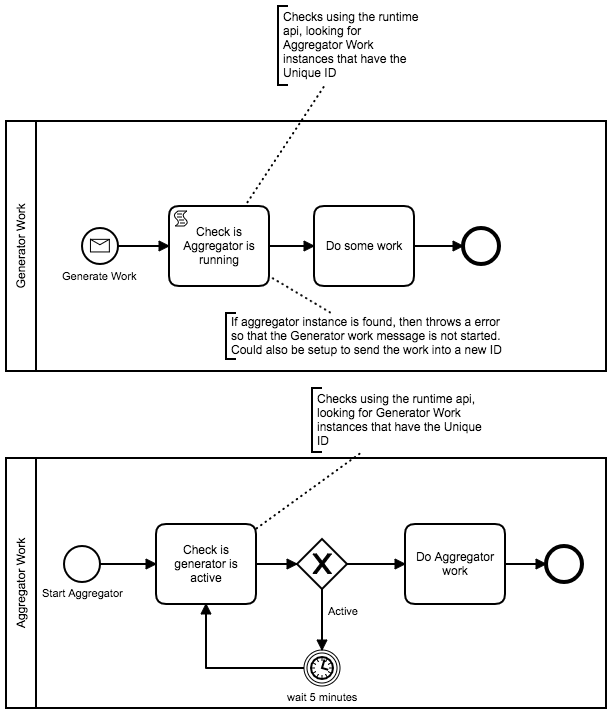
@z123 I made some assumptions about your use case, (if you can provide more real example of what you are trying to do, that would help) (there was another user who was explaining a similar issue as you).
Hi @StephenOTT,
Yes, each generator work on a unique id (combination of date and a type).
That’s a good idea, I’ll look into the solution you mentioned here. Thanks a lot!
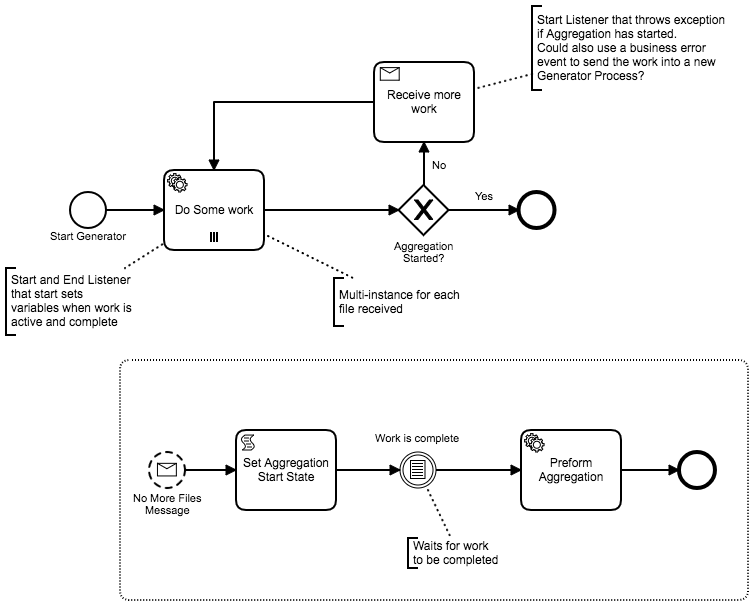
Let me attach my current diagram (yesterday I didn’t know we can attach picture here :-))
Hi @StephenOTT,
I agree with you. Looking back at my diagram, I am actually wondering why we have to make Client to send start-aggregator-message, instead of letting proceeding task to tell it when to start the aggregator, which is pretty much similar like what you proposed. Slight revision from your diagram is the Client still needs to send ‘final’ message to let it knows that there is no longer new Generator to submit, hence Aggregator will just check for remaining Generators that are running. For this ‘final’ message, the Client can send list of input files, which Aggregator can check if all of them are processed.
Btw, what is the best practice to store the state? For example, I want each successful Generator to save the input file to a list object (persisted), which then next task, Aggregator can check the list.
In your example, why is the aggregator the next task?
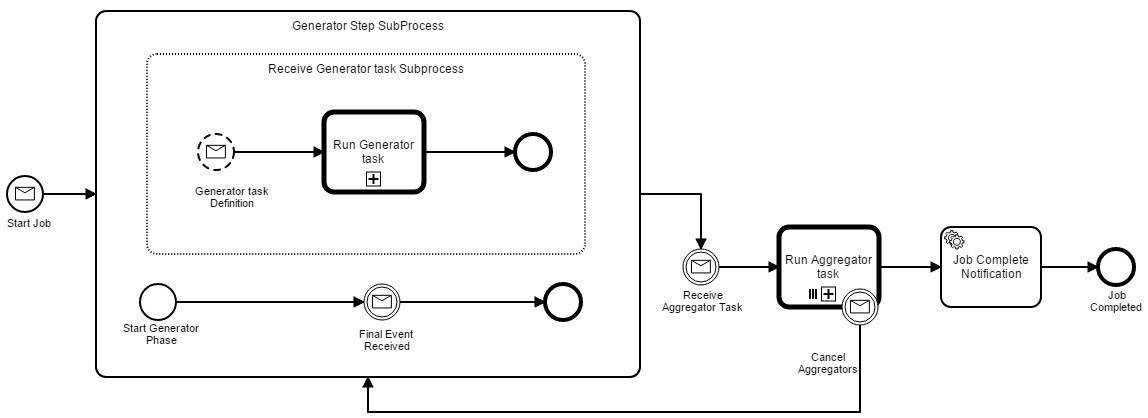
If you draw the workflow in non-bpmn, just draw it as you understand it without trying to convert to BPMN, then we can build from that. I think you are trying to convert to bpmn format and there are parts you are omitting or assuming are clear, but are being missed when we look at the bpmn.