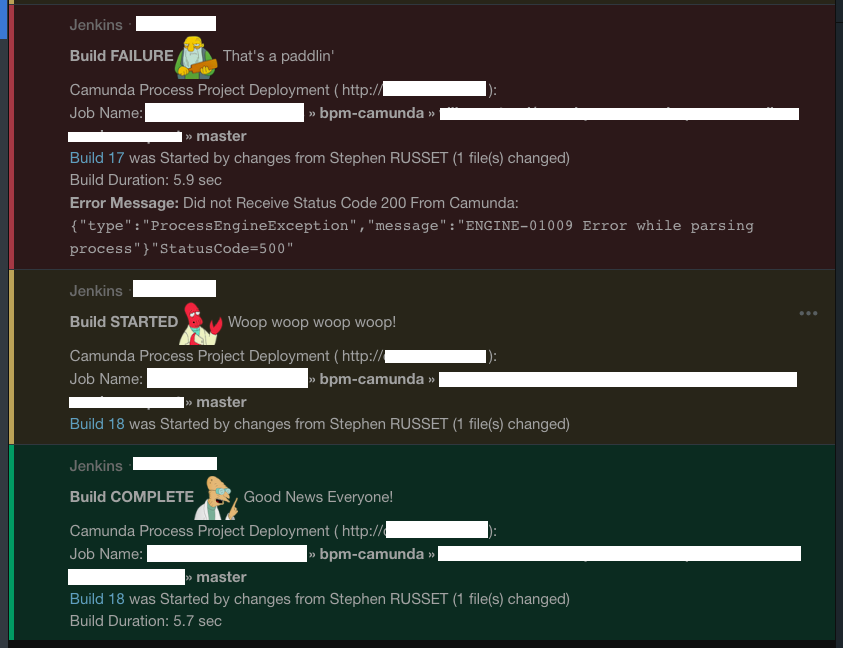
I put together a working example of Process Deployment using Jenkins for a sort of CI for Process Files.
Use Case: When you are not using Java WAR deployments, and you deploy directly to Camunda using the Rest API, and you still want to have the benefits and structure of CI.
Looking to get feedback from the community on the structure and style. Anything that was missed or ideas that would make this better.
For this first iteration I put this together using Jenkins. See the following Jenkins File: https://github.com/StephenOTT/ProcessProjectTemplate/blob/master/Jenkinsfile.
You can deploy jenkins locally with: docker run -p 8081:8080 -p 50000:50000 jenkins
See the following for notes about how the deployment process works: https://github.com/StephenOTT/ProcessProjectTemplate/blob/master/docs/deployment.md
TL;DR: the Jenkins file reviews the following file inside of your SCM Repository such as Github:
You set your Camunda /deployment/create arguments in the deployment object, and any files you are uploading as part of the deployment in the deployment.files object.
You can set this to work with Master, Branches, Releases, etc.
The Repo: GitHub - StephenOTT/ProcessProjectTemplate: Template project for Process (BPMN, CMMN, DMN) / Camunda Projects is a working example you can connect your jenkins system to. In this repo there are some other conventions that are documented. These are purely for ease of use/repeatability for large number of “projects”. Feel free to provide feedback.
Some top level thoughts that I would be interested to hear peoples thoughts on:
-
How can Tests be added? I am looking at jUnit + Cucumber at the moment. In the ProcessProjectTemplate model there are not java delegates or other java code you upload/deploy. Everything is in your Project as Scripts and related files. So the number of unit test use cases are reduced in some respect.
-
Thoughts on Migrations?
-
A few common helper scripts are documented at: https://github.com/StephenOTT/ProcessProjectTemplate/blob/master/docs/helpers.md, would be interested to know of other common scripts that people use.
-
The folders in the root of of the project(BPMN, DMN, and CMMN) were added for a more clean separation of files to make sorting through large projects easier. But would be very interested to hear back experiences on this, where you have projects with large numbers of process files.
-
In this current model, all files would be redeployed. Meaning that we are not taking advantage of redeployments, and other selective process file deployment strategies. Interested to hear peoples thoughts on how this could be addressed.