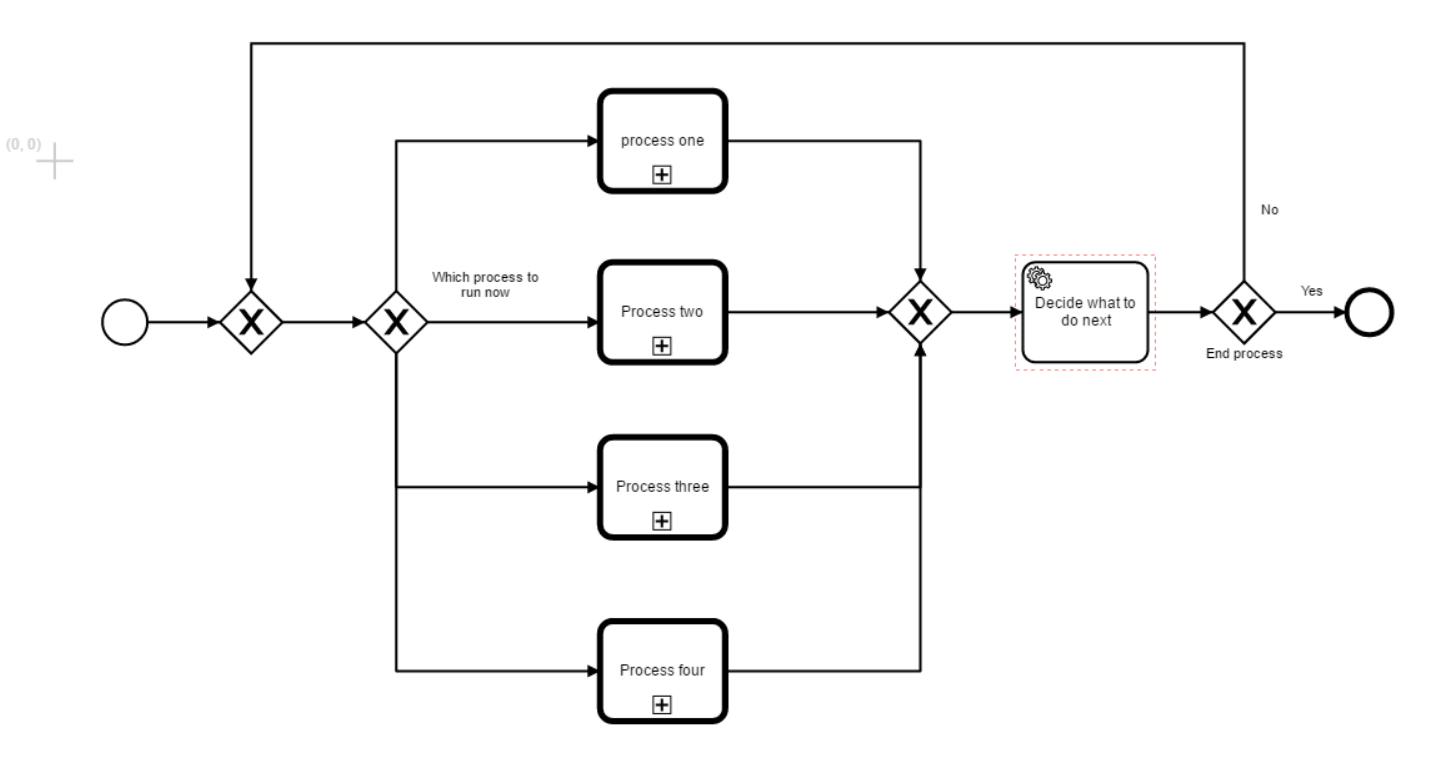
Hi,
We have a business process that is just too large for one process, so we’ve split it up into one super process with call activities that start child processes.
By now we have the “default” path.
Now we are debating the best way to incorporate looping behavior /error handling, between these child processes. In our case most commonly some later child process detects some error in the data and the process must return to a specific point inside an earlier child process.
We could model it with “error boundary events” on the call activities, an explicit connection to the previous call activity and then handling the new entry point inside the previous call activity. But this feels like it will quickly get verbose and rigid.
We could also do it with message or signal events, but are somewhat suspicious that we will run into problems once we have multiple deployed versions of this process that messages get sent to the wrong versions or that it becomes hard to follow the logs/process state/process variables.
Ideal would be being able to send signals under a “process and all processes callable by it” context, (I remember logic like this working with subprocesses).
The way I see it we can either have one large “orchestrating” superprocess;
- one clear root process instance, so state of process is easily visible / “drill-downable”
- easy logging
- quickly becomes verbose with errors/loops
Or multiple smaller processes that start each other via messages/signals
- most flexible
- versioning/logging/process variable headaches?
(or some mixture I guess)
What is the best practice/best approach/ are we missing or misunderstanding bpmn model elements/camunda features ?