Hello,
I am working for a startup that has chosen Camunda as an engine for their product for its responsive community and convenient web editor. As a product manager, I am concerned with customer’s satisfaction and product ease of use. While we believe that standards (namely BPMN) are key for reducing the cost of learning the product, we decided to introduce some extensions to speed up the integration possibilities of a process engine.
We know that there are many integration points in Camunda like web services, integration bus and Apache Camel extension elements, we still find that as an integration tool, Camel is still the most developed, though with its xml/java configuration it lacks a lot of convenience.
I suggested that I prototype a solution that embeds Camel possibilities into Camunda graphical representation of process routes, we test its performance and hopefully present it to our customers as a building tool for their needs.
To achieve this, I have changed the notion of BPMN messages. They are now Camel endpoints, and instead of message name a user provides a Camel URI.
With this we get unlimited integration possibilities together with interprocess messaging if we use Camel’s “direct” or “seda” protocols.
Take a look at examples below:
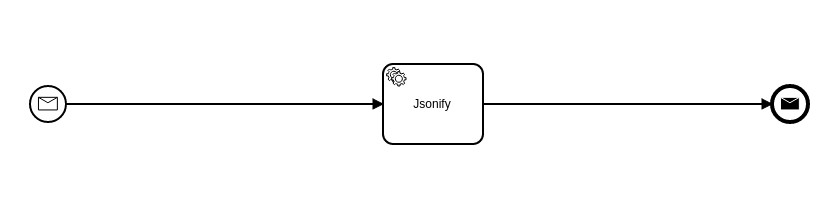
This process reads a CSV file, transforms it to JSON and writes to another file. Editing extensions looks like the following:
The starting message event is basically a file polling Camel endpoint. Once a CSV file appears, Camunda starts this process, which with its first step puts file contents as a java Map into the “content” variable. The next step is pure Camunda service task, it turns the Map into JSON using Spin. The ending message throwing event takes “json” as the message body and writes it into a file.
This was able to be done with existing Camel integration, but would require editing two Camel routes in an xml file.
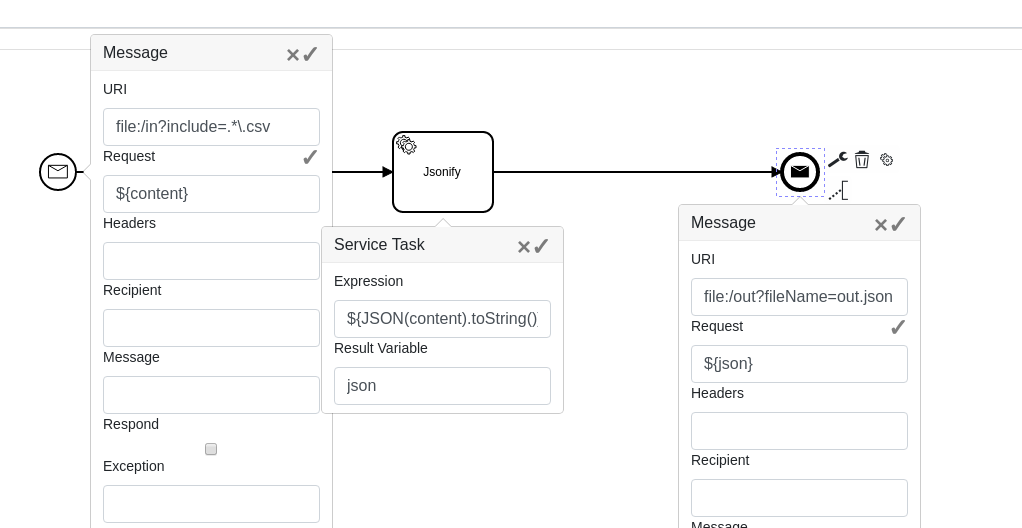
We may go further and even generate a response to the Camel route.

This process listens to a rest request, generates the response and then throws it back:
To achieve this, we check the “Respond” tick and store the message so we can work with it, promising that we will throw the response later. Then we modify the response body, and then we add a throw message event without any URI, but with the “starting” variable mentioned. At this point Camunda sends response to the original source. We can test it with web browser: invoke “hello/camunda” URL and find out what Camunda responds to that.
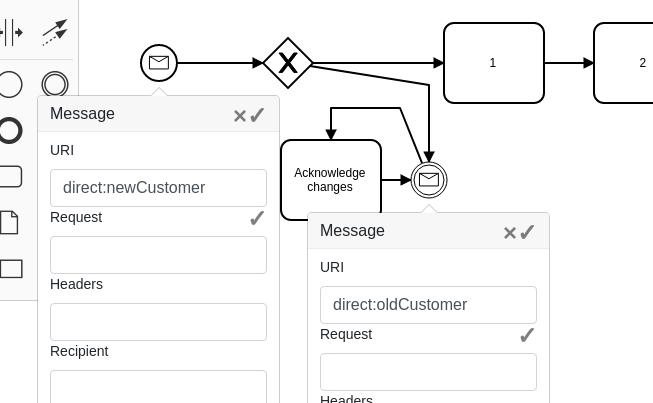
This process also shows how we can specify which process waiting for an intermediate message should be invoked. We are using a notion of “Recipient” for that. In an intermediate catching event we say that this particular process should receive messages only where the recipient equals something that is stored in ${first.me} variable. We may notice that “first” is actually the Camel message headers from the first incoming message, and for rest services it is a collection of query parameters and url pattern portions. If we invoked this process with “hello/camunda”, the variable ${first.me} was “camunda”.
Now if we call the rest service with “goodbye/camunda”, the intermediate message catching event will be invoked in this process. This will also respond with a modified message.
This way we can route processes based on what we have got.
As in real life we sometimes deal with enormous input files, I had to implement the streaming and splitting functionality, together with basic unmarshalling.
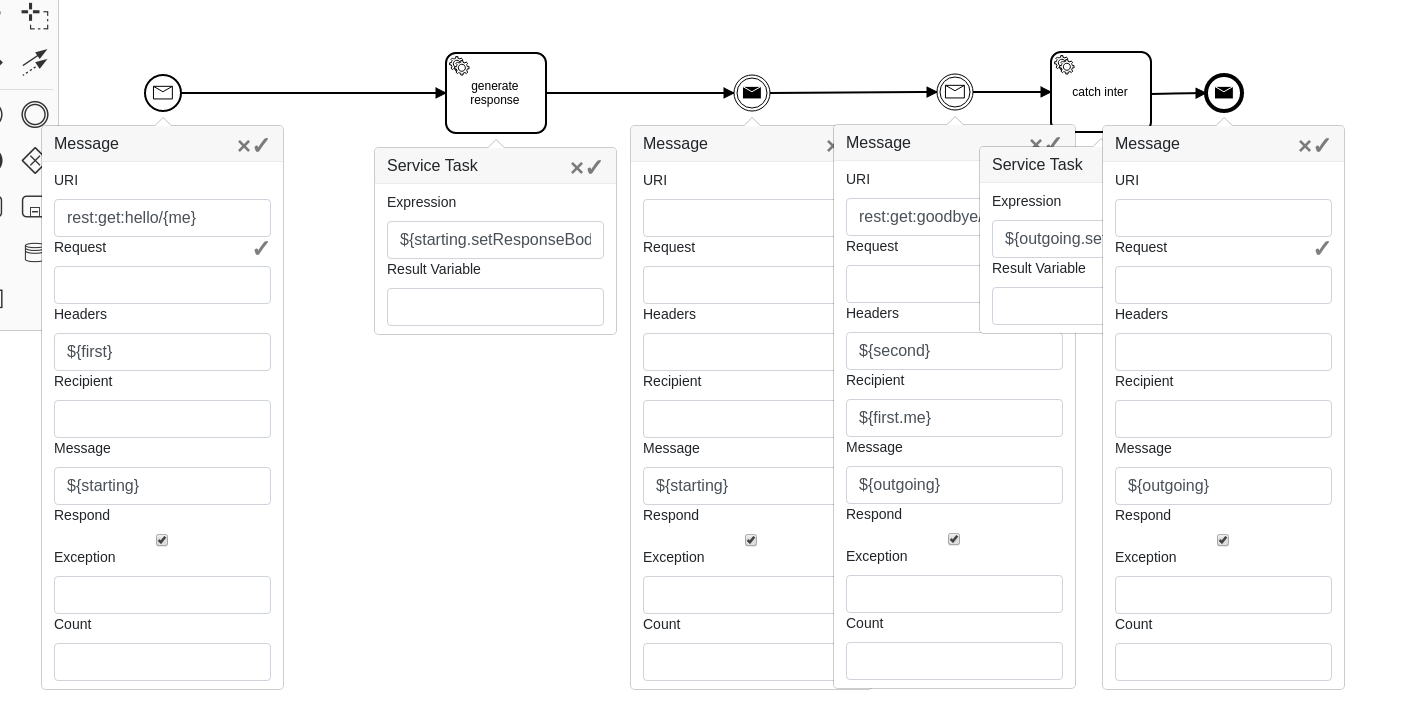
In the example below the CSV file is split, unmarshalled into the java Map, transformed to extract some customer information and routed further based on customer id.
The splitting/unmarshalling information is specified using a “Preprocess” menu that allows to define how a file/stream should be treated.
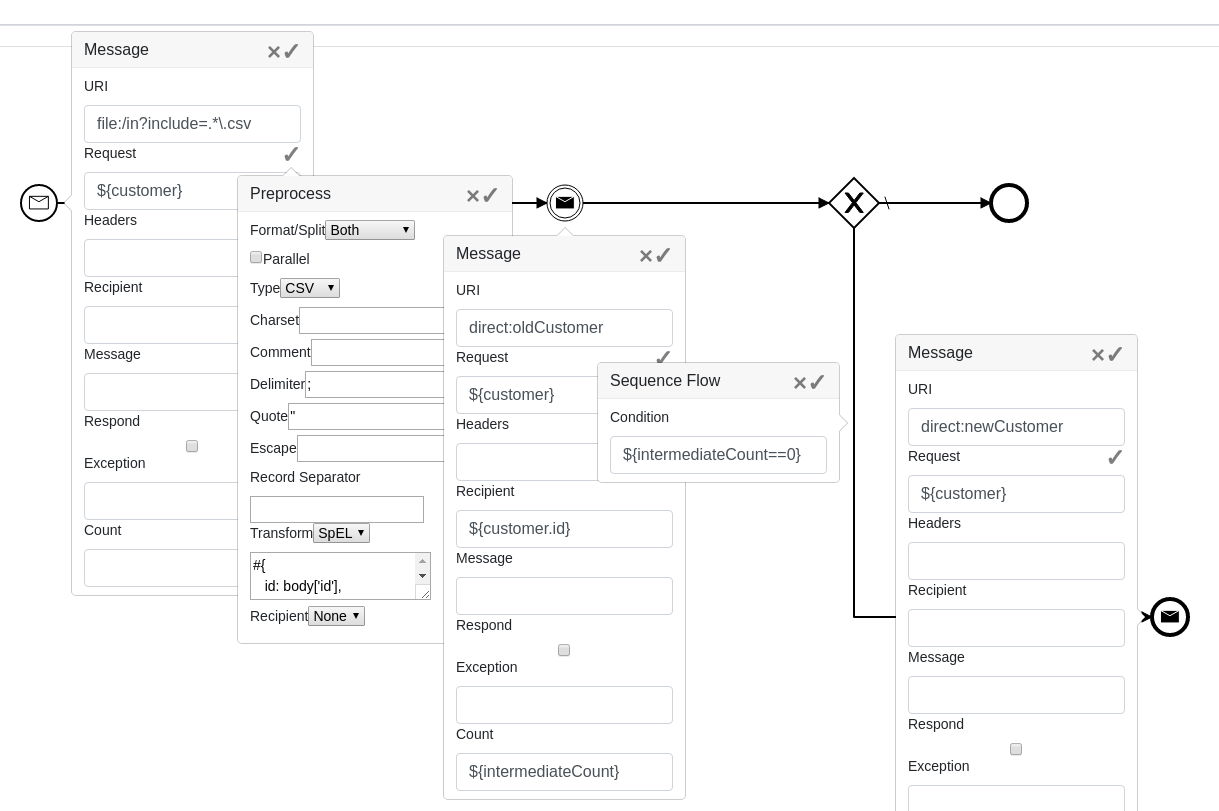
Here we wait for a file, then split it into chunks. Every line of the CSV file is transformed as a java Map, then we are able to construct another convenient Map in our own format, using SpEL inline Map creation notation #{id: body[‘id’]}.
This process is invoked as many times as we have lines in our CSV file. Every instance has its own ${customer} object where we have “id” field and any other fields. We’re able to create different transformers for different input file name patterns, and be sure that the customer identifier is taken from appropriate place of the input csv.
Then we send an interprocess message to a process where there is a catching message event with the same recipient waiting. The system counts how many intermediate catching events were notified. If we are accurate in route/message definitions, we may assume that this is a new customer if no message event was waiting for this “id”. In that case we call another message, knowing that this will start a new process for this customer.
Please let me know if this is interesting.
Regards,
Fedd
ps/ Feel free to rename the topic and also I admit that I haven’t quite figured out which category this falls in. This isn;t yet a community extension…