Hi @Pradip_Patil, another possibility could be to use the process instance modification capabilities of the runtime service. The docs below talk about how this can be used to change multi-instance activities.
I’ve modelled an “add another task” process modification as a non-interrupting message catch event on the boundary of your multi-instance. The execution listener on the boundary event looks like this:
import org.camunda.bpm.engine.runtime.ProcessInstance
import org.camunda.bpm.engine.RuntimeService
println "= Adding another task "
def runtimeService = execution.getProcessEngineServices().getRuntimeService()
def processInstanceId = execution.getProcessInstanceId()
runtimeService.createProcessInstanceModification(processInstanceId)
.startBeforeActivity("loopThroughOrderItems")
.execute()
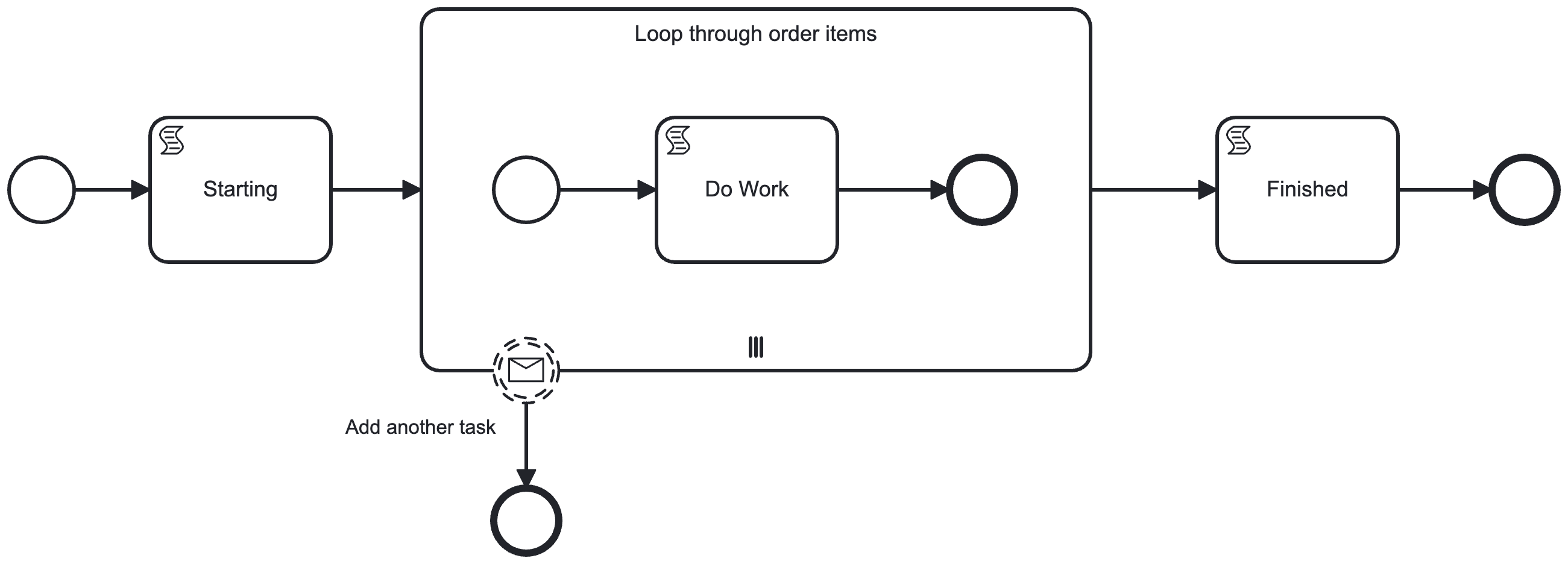
process_instance_modification.bpmn (8.0 KB)
- Each “Do work” script task of the multi-instance sleeps for about 15 seconds simulating some work
- After starting an instance of the process you can correlate the “add another task” message to your process instance. I used the REST API:
curl -X POST "http://localhost:8080/engine-rest/message" -H "Content-Type: application/json" -H "Authorization: Basic yourdigesthere” -d '{ "messageName": "addAnotherTask", "businessKey": "1234"}' - I added some logging to show what is happening. I had to change some of the async settings to get the multi-instance instance to truly run in parallel.
- The multi-instance body is marked as
async-beforeandnon-exclusive - The sub-process end event is marked as
async-afterandnon-exclusivebased on the advice from @thorben in this thread to reduce the amount of rollback if an optimistic locking exception is thrown when instances of the the multi-instance complete. I’d recommend playing with the async settings to see the impact on the logging - it is really interesting. - I’ve also added some randomness (+/- 4 seconds) to how long each “Do work” task runs
- The multi-instance body is marked as
- Side note, only 3 script tasks are runing in parallel because the default thread pool size for the job executor is 3 (I think). If you are running with a larger thread pool, you may see more concurrency.
Loop cardinality is 4, 2 new tasks were added, Tasks are numbered 0-5 inclusive:
= Starting ===============================
Started task 0
Started task 2
Sleeping for 14793 milliseconds
Started task 1
Sleeping for 18644 milliseconds
Sleeping for 11034 milliseconds
= Adding another task
= Adding another task
Finished task 1 after 11034 milliseconds
Started task 3
Sleeping for 16491 milliseconds
Finished task 0 after 14793 milliseconds
Started task 4
Sleeping for 16267 milliseconds
Finished task 2 after 18644 milliseconds
Started task 5
Sleeping for 11307 milliseconds
Finished task 3 after 16491 milliseconds
Finished task 5 after 11307 milliseconds
Finished task 4 after 16267 milliseconds
= Finished ===============================
Now a disclaimer ![]() In the docs there is this …
In the docs there is this …

But, “not recommended” != “don’t”. To me, this is quite a clean and readable solution, but I’d value feedback from others about the safety of this approach for this use case.
Hope that gives you some other ideas!