We’re trying to get multi-instance sub-processes to run successfully in parallel, but we keep on encountering optimistic locking exceptions. We are running Camunda BPM 7.7, and one of the fixes mentioned here - https://blog.camunda.org/post/2017/02/camunda-bpm-770-alpha1-released/ is a drastic reduction in that type of exception, leading to notable efficiency increases. We’re trying to determine if these exceptions are from us setting up our BPMN processes incorrectly, or due to some other issue.
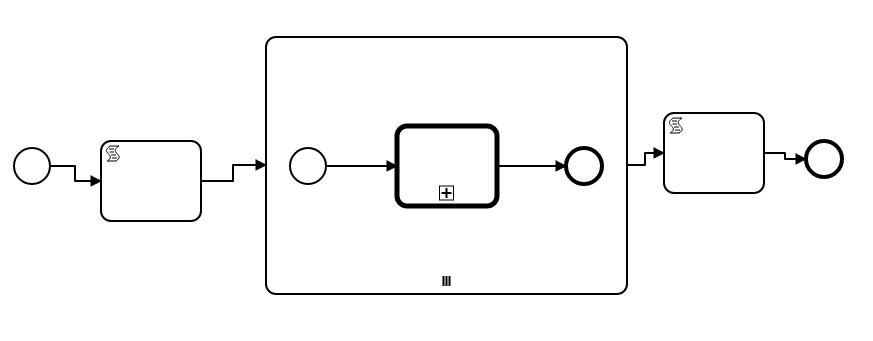
For reference, our exterior bpmn file looks like this. The script tasks are just log messages, and the sub-process in the center is multi-instance with loop cardinality of 10.
It looks like I’m only able to post one image in the topic, but the call activity in the sub-process calls a second bpmn file with a start event connected to a script task with another log message, which itself is connected to a second script task with a 10 second sleep (to easily determine whether the processes are being run serially or in parallel), and that’s connected to an end event.
We can get the processes to either run sequentially with no exceptions, or run in parallel with several optimistic locking exceptions.
Are there steps we need to make sure to follow when generating the models to allow for parallel execution without the optimistic locking exceptions? Do you have example .bpmn files which should function correctly in invoking a multi-instance sub-process?
Any ideas would be appreciated.
Thanks,
Matthew
Hi Matthew,
How to avoid optimistic locking exceptions depends on the process model in use and the API interactions that custom code makes. Thus, there is no general how-to-avoid-optimistic-locking guide. In general, optimistic locking exceptions occur whenever the process engine updates one database entity from multiple commands in parallel. This can for example be when your code updates the same variable, or when the process engine does something similar internally.
In the case of multi-instance, the process engine manages the multi-instance variables that are updated whenever a single instance completes and the execution tree that is updated whenever the structure of the process instance changes, for example when a single instance completes. The latter is typically important for synchronization in the process instance, e.g. to be able to reliably decide when the entire multi-instance activity has finished and can be completed.
These optimistic locking exceptions can never be avoided completely, as they lie in the nature of the problem and how the engine works and are therefore expected behavior. In that sense, having optimistic locking exceptions occur does not mean that anything is incorrect. By using asynchronous continuations, you can reduce the impact of such exceptions (i.e. you can reduce the amount of work that gets rolled back). For example, if you declare the end event in your multi-instance subprocess as async after, then any optimistic locking occurring due to synchronization of the multi-instance construct will only roll back to that point.
I hope that helps.
Cheers,
Thorben
1 Like
Hey all,
i think setting “asyncAfter” on the end event, as Thorben suggests, would help in order to reduce optmistic locking exceptions.
This works fine for subprocesses as we have a process element (the end event) that we can use to introduce a new transaction boundary. However, how we might achieve a similar solution when just having a “plain” multi-instance activity?
For example having a List of objects (i.e. Customers), in a loop a service is called who needs to retrieve some information for that object (i.e. Customer-ID):
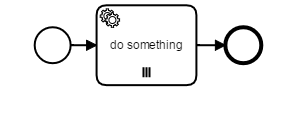
Using a process model as stated above in combination with an execution listener of type “end” for the activity “do something” that updates the customer objects in our list we of course get optimistic locking exceptions due to potential parallel updates of one process variable.
Wrapping that activity in a multi-instance subprocess works, but is no good modeling practice as we are introducing a process element only for technical reasons.
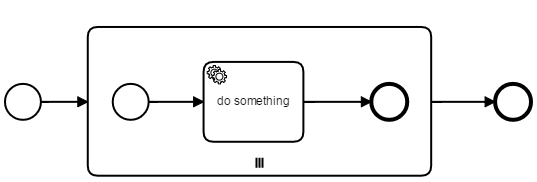
The “inner” end-event is a transaction boundary, so in case of OptimisticLocking Exceptions from our execution listener on the subprocess we just try to update the variable again and not executing “do something” twice.
Any other ideas/workarounds how to solve this without a subprocess?
Is there any chance to get the needed transaction boundary as we have using a subprocess?
Kind regards,
Matthias
1 Like