I’m attempting to use Camunda for parallel processing using MultiInstance Iteration to process large amounts of data.
I’m using the expression “for i in 0…records return i” to supply the input data for the multi instance, where records is the variable name that the system would replace the record count size based on the input.
When I have less records, everything works perfectly. However, when I have a larger record size, such as 10K, it takes more time (approx. 5-8 minutes) to start the execution on the consumer side, and similarly, as the record size increases, it takes more and more time.
Could you please advise on how to expedite this process?
For your convenience, please see the accompanying sample screenshots and workflow.
@GRajaMca I am very new to Camunda and not in a position to give you a workable code reference to your problem. However, you can have a split gateway implementation to break the huge record lists to some sort of manageable record count (based on the performance you observed) and run them parallelly with your same multi-instance sub process solution. I assume 1K record execution performance is working fine. Then you can have 10 branches from the split gateway to work with your multi-instance loop. This is having limitation of hard coding branching.
Or you can introduce a simple loop implementation as a wrapper on top of your multi-instance parallel execution sub process to see performance improvement. Please make sure multi-instance record count is optimum based on your earlier observed performance result.
I haven’t tested parallel processing with that many records, but I am not surprised that there is a noticeable slowdown when you reach that task. There is suddenly a LOT more data to process and it will take time to process it all, especially as you are wanting parallel processing (in a sense, you are asking for 10,000 times the work to be completed by the same resources, which will inevitably take longer).
If you are using self-managed, you could try increasing your resources. (I admit I don’t know exactly which settings to adjust, so perhaps open a support ticket.) If you are using SaaS I would reach out to the support team using your enterprise support link.
Alternatives would be something like what @Suman_Paul suggested (batching the processing), or using a custom job worker or Connector to accomplish the same task.
If you are storing all the record data in your process - instead of just the IDs, for instance - then I would consider looking at storing your data elsewhere. The more data that is used in a process, the slower the process will execute. I try to think of data in terms of process data and application data: process data is the absolute minimum amount of data needed for the process to execute, whereas application data is all the rest. It may be more efficient to have a job worker that receives a large collection of record IDs to process than having a multi-instance subprocess that runs thousands of times. (But also maybe not, it depends on a lot of factors.)
Hi @Suman_Paul , For me the bottle neck is stage between the job start to record iterations(Multi Instance kick start). Also in my case where the record count is completely dynamic. Base on the file size it will change. With the suggestion what you have provided not sure how to use the split gateway to branch the things out in more dynamic way. if possible can you please share some reference ?
@nathan.loding, I’m running a self-managed instance with a 3GB CPU and memory. In addition, I just save my ids in the workflow; the rest of the logic and data are kept at the application level.
The major bottleneck is between job initiation and multi-instance job execution.
Also, I’d like to understand the custom job worker for multiple instances, or how to build something similar to kafka producer, where there’s a range of ids to have several subprocesses.
@Ingo_Richtsmeier. For my tests, I’m using the most recent version of the Docker image. I’ve already read the sample you mentioned. We must keep track of a large number of batches and ids individually in this case. This could potentially lead to memory issues. since we are predicting the data load for the particular operation may go 10M records.
Hi @GRajaMca
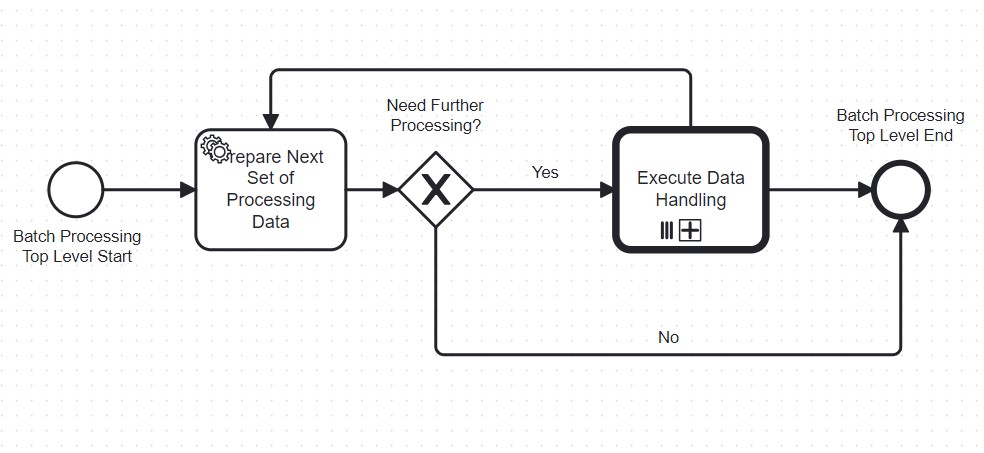
Please see the process diagram attached below for the second option mentioned in my earlier reply. In the “Prepare Next Set of Processing Data” activity, I am proposing to create a subset of your original records and pass it to the “Execute Data Handling” for parallel processing. After completion of that subset processing, move the control back to the first activity. The conditional check to determine whether you have more data to process. In case no more data available to handle, the process will end.