Hello my friend @Hadi_Hoteit1 !
If you are referring to the ACT_RU_INCIDENT table, it will only have records if there is an incident (red token) in the camunda cockpit, as these are runtime incidents.
If you are referring to the ACT_HI_INCIDENT table, this is indeed related to your change in the “history level”… however, I believe that if you have never done or configured a “history cleanup”, after setting your history level, this table should still have any incidents, if any have occurred since the deployment of your Camunda application.
Now let’s talk about what can be done to catch your mistakes…
In this case of optimisticLocking or mismatchingCorrelation, Camunda will most likely not generate an incident, as this “theoretically” is a safeguard to avoid unwanted concurrent transactions in the optimistic case, and the mismatch is telling you that the message you want to correlate is not it was possible, because Camunda was not waiting for her.
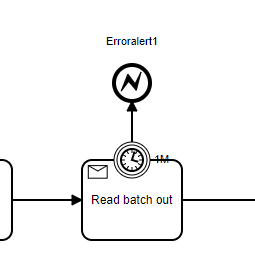
But as for capturing errors in general, you can wrap everything in a subprocess, capturing generic errors, or even with a subprocess of events.
An alternative that could be done for these cases in which you have an instance stopped for a long time, and without incidents generated, would be to understand the time it takes for an instance to finish the entire flow… and wrap your entire flow in a subprocess, adding an interruptive timer that shifts your instance to a treatment flow.
For example, the instance normally takes 24 hours to complete the entire flow… so put a timer for 48 hours… because every instance that stays there for 48 hours will be moved to a treatment flow and verification of possible errors.
OBS.: I suggest that when making the call for message correlation with camunda using the “Message” REST API, you put a Logger in your code to capture the Camunda API response and be able to have this record that is of great importance for check possible invisible problems in the Camunda Cockpit.
William Robert Alves