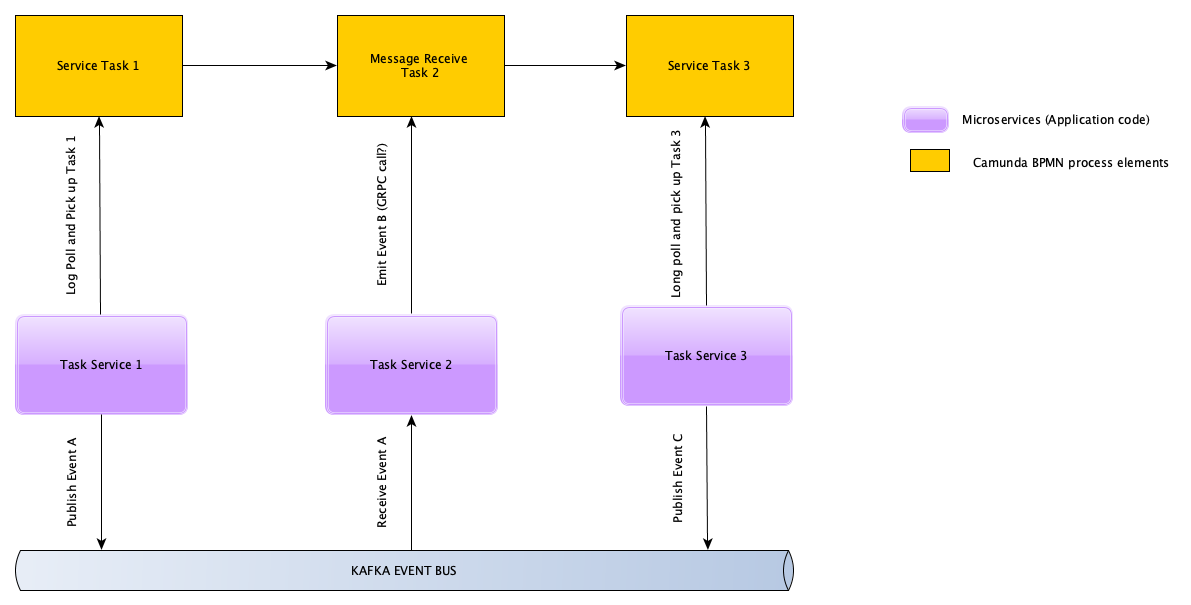
One thing that I stumbled upon is what’s the benefit of using a Kafka Topic as an event brokering mechanism as opposed to the built-in Camunda Topic (which I understand it to be a Task Row in the underlying database table).
Assuming I have Kafka available in my enterprise infrastructure, is it still a better choice to use the built-in topic for a solid production grade application?
One thing comes to my mind is scaling. Kafka scales really well as the traffic increases (much better than a RDBMS). Is there anything else?
What is the best practice or the recommended way here?
I’m trying to (over) simplify and generalise a pattern here. Please put your comments and recommendations keeping in mind the standards and best practices.
My assumption for the above diagram is Camunda doesn’t use any direct connectors (eg: Kafka). Camunda does not have direct access to my Kafka (event bus). Every task is accomplished by a microservice.
Here is my understanding (needs to be validated):
The worker services (microservice) always pulls the task from Camunda (it’s a pull model and not a push model). This is done via Long polling (REST or GRPC?)
The Task service notifies Camunda about the completion/error of the task (again via GRPC or REST?).
Is this a standard architectural pattern of not having to expose kafka directly to Camunda and always interact via “Task Microservices”? Therefore Kafka is more of an internal event bus as far as Camunda is concerned.
If this is the case, what checks/standards/precautions can be in place to avoid the choreography visibility hell within the microservices?
Any pointers towards guidelines/pitfalls/caveats would be much appreciated.
Camunda users often use an architecture, such as the one you’ve sketched. The task workers communicate directly with Camunda, but the communication with other systems/services is implemented via an Event Bus.
If you use Camunda 7 the long polling is done via REST. If you use Camunda 8, it is done via GRPC.
The same holds for the complete command.
This is the recommended architecture for Camunda 7. We call the setup “Remote Engine”. However, there are other options as well: Architecture Overview | docs.camunda.org
Can you explain what you mean with “Choreography Visibility Hell”?
In general, Camunda is a process orchestrator, which implies that no choreography is necessary. Camunda invokes services in the order required by the process. It receives all the data necessary to control the process and to invoke the services. In that case, each service talks only to Camunda and do not need to know about each other.
However, if you use a process orchestrator, to implement a business process, your microservices are often more fine-grained than the service tasks in the process. In this case, you can
use a service Choreography triggered by the task service
use another hierarchy layer of processes to orchestrate the fine-grained steps
PS: If scalability is a concern, check out Camunda 8. Camunda 8 is a cloud-native process orchestrator that does not rely on a (potentially slow) RDBS.
By “Choreography Visibility Hell”, what I mean is the microservices would be communicating via events passed though the event bus (kafka), one must not go overboard with losing the sight of what happens within the services (internal message flow). This is not relevant to Camunda per se. But was curious to know the general practices where understanding the bigger picture (flow) is made possible using Camunda, but the internal communication within services is still choreographed and a bit hard to track (if gone too far especially).
I’m planning to evaluate Camunda for one of my clients and unfortunately Camunda cloud may not be a viable option due to security policies. Mostly it would be an on-prem Camunda 8 “Remote Engine” set up around which the microservices collaborate.
For the above on-prem set up, can I be advised:
Would the ZeeBe connector (based SDK) still work (our services are in Spring Boot).?
Would this set up still use RDBMS for it’s internal state management (eg: tracking processes, tasks, locking etc)? Curious to know what database used under the hood that doesn’t affect the scalability at the same time offers consistency (in terms of locking tasks etc, which is largely internal to Camunda engine).
Yes, the connector SDK can be used in the self-managed Camunda 8 setup
No, Camunda 8 does not use a relational database (neither in the self-managed nor in the SaaS offering). Its state is stored in RocksDB and fault tolerance is established via replication. The following thread might be interesting:
Furthermore, events can be exported. Out of the box, Camunda 8 offers an exporter to Elasticsearch. The data produced by the exporter is used by the webapplications (Tasklist, Operate, Optimize). You can write your own exporters, but beware that these can become a bottleneck: