We are using Camunda community edition 7.12 with springboot in a fault tolerant cluster mode. The back end has a my sql database. The process definitions deployed contain externalized functionality accessed via SQS using Camel SQS and CAMEL Camunda components. SQS redelivery moves the message to Dead Letter Queue after three attempts. When it is running with two nodes cluster, quite often when the instances are waiting in message receipt activity, the BPM throws exceptions saying that it cannot correlate the message to an instance waiting for the message. This is not true. What happens is the BPM has a service task which sends a SQS message to another external micro-service, and then it moves to the next message receipt waiting task. The second micro-service upon completion responds to the SQS with the BPM is listening to with businessKey. When there is load on the cluster, there are times that the SQS delivers the message to the second cluster instance (not the instance from which the step transition was initiated) which finds that the instance has not yet moved. I suspect that the issue may be cache synchronization issue. Because we can easily re-create the problem when we have same mysql backend and two nodes running. What ultimately happens is that after several retries the the message fails and goes to dead letter queue while leaving the instances stuck in the middle. After some time if we manually trigger another message, the instance moves from where it is stuck. The issue does not occur in non-clustered development environments.
I want to know if there is a parameter or a process engine setting through which we can tune the cache refresh or synchronization frequency of the supposed to be intelligent cache which keeps save points in memory and then commit to database in batches. I saw it in the camunda.
in this link of the documentation:
https://camunda.com/products/camunda-bpm/performance/
I see the following:
"When reaching a savepoint, the in-memory state is synchronized with the database to ensure fault-tolerance. Camunda provides fine granular control over the placement of savepoints,and thus allows you to balance fault tolerance and performance. For example, you can batch the execution of multiple activities in a single transaction and by this reduce the number of database synchronization points.
"
Could this be causing synchronization issues with messaging?
If so how can we disable if it cannot be tuned by us.
If this cache is not causing an issue, what could be causing this racing of instances when externalized messages try to correlate messages with business keys. Can you please provide the detail information?
Hi
I assume you have a send task followed by a receive task. Are these two tasks synchronous or in the same transaction? (eg there is no async after set on the send task nor async before on the recieve task)…
I suspect what you are experiencing is a race condition between the send and receive, hence you want to minimize latency…
There is also a community plugin which can ‘cache’ receive messages for retry…(see here)
regards
Rob
Hi,
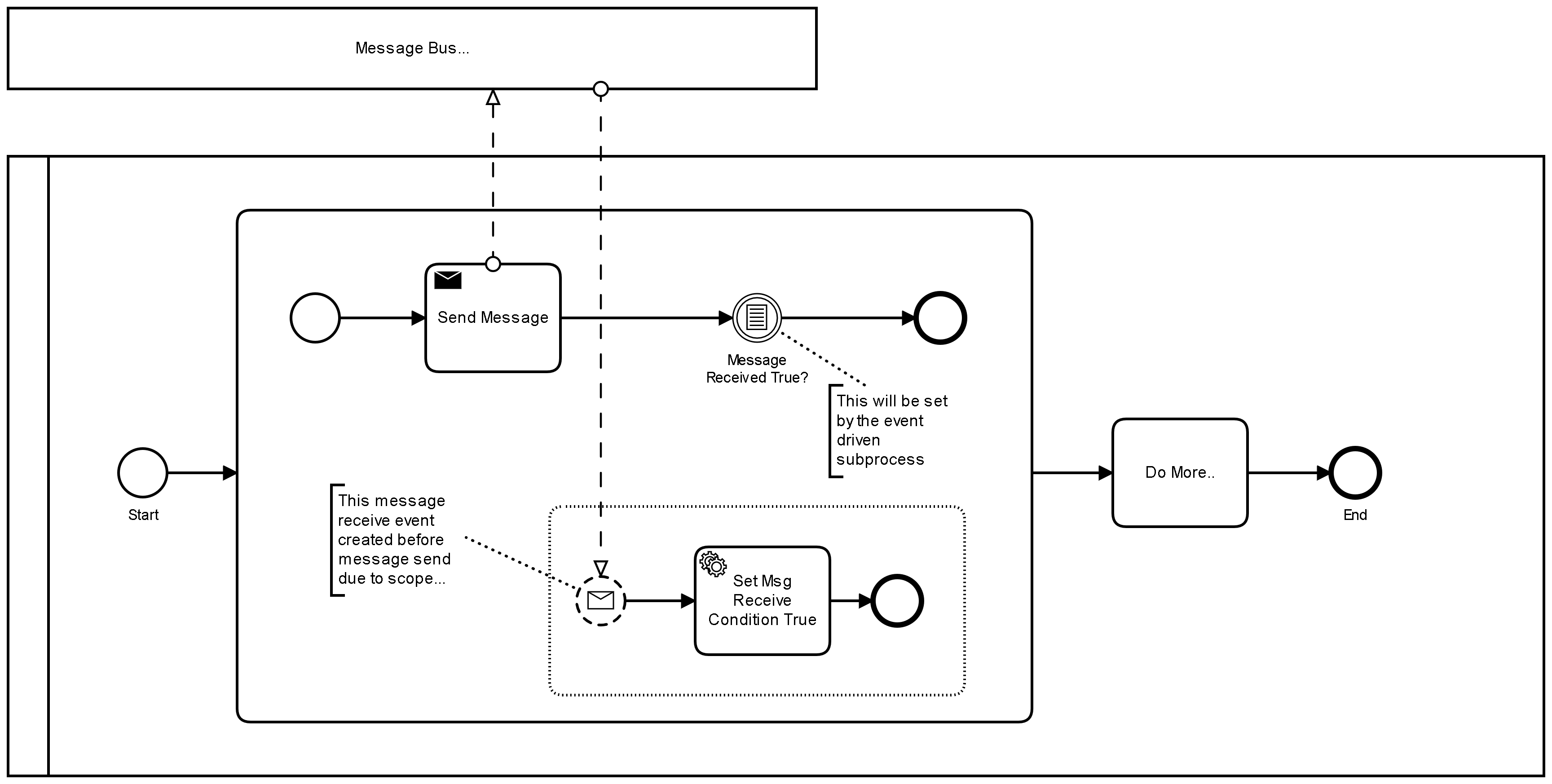
Here’s a process pattern which could also eliminate receive race conditions… This pattern effctively sets up the receive event before the send task executes (set the send task to async before to ensure a DB flush)…
regards
Rob
1 Like
Hi Webcyberrob, How you understood this problem is correct. My initial suspicion was that racing may be due to caching issue. The BPM engine code containing the cache used by entity manager does not look like a cluster aware cache. If you create caches which do not synchronize with other instances then it can cause an issue. However, I have an interesting observation.
We were able to trace two logs from both containers running the camunda instances. We have made 10 redeliveries with 2 minute visibility in place. So it will be retried for about 20 minutes. When failed we expect 10 attempts and we see those. it is distributed like this, 7 failed in first instance and 3 failed in the other instance. If we assume that one instance has stale cache then this will not happened. It failed in both instances. If Camunda is enterprise ready, if my process diagram works fine in single node case, it should work in clustered mode. If someone asks me to change process diagram to workaround this issue in clustering, then that is a workaround and not a fix to the root cause of the cluster racing issue. Can someone explain which part of the code and what results in this racing issue. Since code is open source we might be able to fix the issue in the BPM engine. I am surprised if Caminda does not know that this issue exists. I am sure this is a well known issue because I find other topics describing the same issue. Can someone tell is pointing to the engines code what is the root cause of this racing issue? Is it a problem in the cache, is that a database record corruption, is it a thread deadlock? or what? I highly appreciate your responses. Thanks again for trying to help.
Hello, I appreciate you sharing this design pattern. Our process already has like 8 sub processes and within each sub process we have multiple send and receive tasks chained. This is a heavily automated process where it looks cumbersome to add sub process block within sub process block. The BPM process needs to be simple because it should be self explanatory to a business user. Our business users can understand BPMN2.0 diagrams, if we complicate the process diagram like this, even some of the good developers will find it difficult to understand the process. Instead, I would like to know if there is a way to understand the root cause of the issue in the BPM which makes it limited in its ability to support all types of process diagrams, especially the ones with messaging. If someone in this forum (if there is anyone who has built this part of the engine can help us understand, we might be able to fix the issue.)
Hi,
Can someone explain which part of the code and what results in this racing issue.
Its not really an issue, its a consequence of the architecture design. Camunda basically relies on optimistic locking rather than pessimistic locking and database transactions to manage consistent state. Hence in a clustered environment, if an external trigger occurs twice (for some reason) and two separate stateless engine nodes receive the trigger, each node will retrieve a snapshot of the current process state from the DB. Thus each node may be concurrently, yet independently running the process. When a wait state is reached in the process, an engine will flush the process state to the DB. Hence in this case, the DB transaction will result in success for one of the engines, however the other node will fail with an optimistic locking exception. Thus in a typical process centric domin where process semantics are typically serial, this architecture maintains great performance and throughput. In the case of ‘collisions’, the architecture will always converge on a consistent state at the rare occurence of the expense of unnecessary or duplicate processing…
In the case of a send receive pair in a process model, the engine will likley - read process state from DB->execute send code->create receive task-> flush state to DB. There is a race condition here in that if the response message arrives faster than the time it takes the engine to create the receive task, then message correlation can fail. This should be extremely rare, if it happens a lot, either the system is not tuned, or the interaction may be better as a synchronous remote procedure call and thus a service task…
For very robust systems or where message redelivery is difficult, compensating patterns (such as create the receive task before the send task, or message buffers have been used)…
Ideally the time taken for the engine to initiate the send task and create the receive task should be minimised. So what can add latency to this? The send and receive task should be in their own tranactional unit - in other words ensure there is no async after set in the send task, or no async before set in the receive task. Minimise any additional listener code in these tasks. Ensure the DB tier is not resource starving the engine tier - for example if the DB is busy or the DB connection pools are full, the receive task flush could be stuck wiating for DB resource. (BTW, in my experiance using some tests on AWS, I found the engine nodes were very lightly utilised and thus I could use small T3 instances, however the DB tier (RDS Aurora Serverless) needed to be quite substantial…
Anyway, I hope this gives you some more insight… Also can you reproduce your issue with a minimal process model? If so, can youpost your model?
regards
Rob
Hi,
Yup I get where you are coming from and its a good principle to keep BPMN business user friendly…
Perhaps you could try my pattern on a test case - if this seems to workarond your problem, then its a useful diagnostics to confirm wht the problem may be. If that pattern does not cure your problem, then we may be looking in the wrong area…
regards
Rob