@JoHeinem
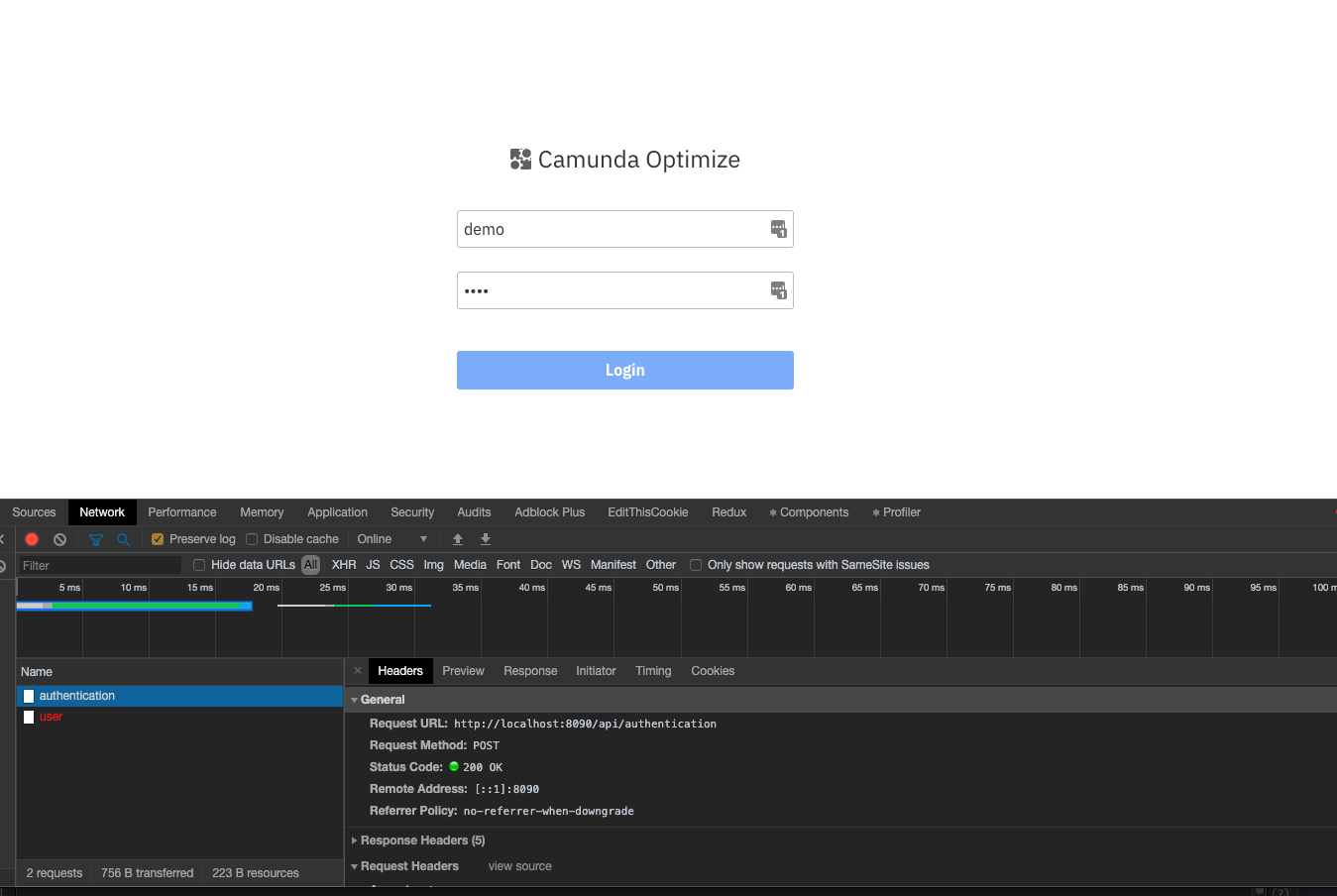
I did get Optimize up and running but I had to run a Docker Elasticsearch container instead of the one provided in camunda-optimize-3.0.0-demo. Incase you are interested here is what I was seeing in my camunda-optimize-3.0.0-demo elasticsearch.log
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
[2020-04-03T09:49:09,032][INFO ][o.e.e.NodeEnvironment ] [***] using [1] data paths, mounts [[/ (/dev/disk1s5)]], net usable_space [59.7gb], net total_space [233.4gb], types [apfs]
[2020-04-03T09:49:09,036][INFO ][o.e.e.NodeEnvironment ] [***] heap size [989.8mb], compressed ordinary object pointers [true]
[2020-04-03T09:49:09,039][INFO ][o.e.n.Node ] [***] node name [***], node ID [lD8OpstvTIe1Uk_h3iEAOQ]
[2020-04-03T09:49:09,039][INFO ][o.e.n.Node ] [***] version[7.0.0], pid[3403], build[oss/zip/b7e28a7/2019-04-05T22:55:32.697037Z], OS[Mac OS X/10.15.3/x86_64], JVM[Oracle Corporation/OpenJDK 64-Bit Server VM/11.0.1/11.0.1+13]
[2020-04-03T09:49:09,039][INFO ][o.e.n.Node ] [***] JVM home [***/oracle_open_jdk-11.0.1.jdk/Contents/Home]
[2020-04-03T09:49:09,040][INFO ][o.e.n.Node ] [***] JVM arguments [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Des.networkaddress.cache.ttl=60, -Des.networkaddress.cache.negative.ttl=10, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFastThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.netty.recycler.maxCapacityPerThread=0, -Dlog4j.shutdownHookEnabled=false, -Dlog4j2.disable.jmx=true, -Djava.io.tmpdir=/var/folders/y6/g20vt2y50m3cg1y57jv283hnrsw83g/T/elasticsearch-4362108986650709219, -XX:+HeapDumpOnOutOfMemoryError, -XX:HeapDumpPath=data, -XX:ErrorFile=logs/hs_err_pid%p.log, -Xlog:gc*,gc+age=trace,safepoint:file=logs/gc.log:utctime,pid,tags:filecount=32,filesize=64m, -Djava.locale.providers=COMPAT, -Dio.netty.allocator.type=unpooled, -Xms1g, -Xmx1g, -Des.path.home=***/projects/camunda-optimize-3.0.0-demo/elasticsearch/elasticsearch-7.0.0, -Des.path.conf=***/projects/camunda-optimize-3.0.0-demo/elasticsearch/elasticsearch-7.0.0/config, -Des.distribution.flavor=oss, -Des.distribution.type=zip, -Des.bundled_jdk=false]
[2020-04-03T09:49:09,699][INFO ][o.e.p.PluginsService ] [***] loaded module [aggs-matrix-stats]
[2020-04-03T09:49:09,700][INFO ][o.e.p.PluginsService ] [***] loaded module [analysis-common]
[2020-04-03T09:49:09,700][INFO ][o.e.p.PluginsService ] [***] loaded module [ingest-common]
[2020-04-03T09:49:09,700][INFO ][o.e.p.PluginsService ] [***] loaded module [ingest-geoip]
[2020-04-03T09:49:09,700][INFO ][o.e.p.PluginsService ] [***] loaded module [ingest-user-agent]
[2020-04-03T09:49:09,701][INFO ][o.e.p.PluginsService ] [***] loaded module [lang-expression]
[2020-04-03T09:49:09,701][INFO ][o.e.p.PluginsService ] [***] loaded module [lang-mustache]
[2020-04-03T09:49:09,701][INFO ][o.e.p.PluginsService ] [***] loaded module [lang-painless]
[2020-04-03T09:49:09,701][INFO ][o.e.p.PluginsService ] [***] loaded module [mapper-extras]
[2020-04-03T09:49:09,702][INFO ][o.e.p.PluginsService ] [***] loaded module [parent-join]
[2020-04-03T09:49:09,702][INFO ][o.e.p.PluginsService ] [***] loaded module [percolator]
[2020-04-03T09:49:09,702][INFO ][o.e.p.PluginsService ] [***] loaded module [rank-eval]
[2020-04-03T09:49:09,703][INFO ][o.e.p.PluginsService ] [***] loaded module [reindex]
[2020-04-03T09:49:09,703][INFO ][o.e.p.PluginsService ] [***] loaded module [repository-url]
[2020-04-03T09:49:09,703][INFO ][o.e.p.PluginsService ] [***] loaded module [transport-netty4]
[2020-04-03T09:49:09,704][INFO ][o.e.p.PluginsService ] [***] no plugins loaded
[2020-04-03T09:49:12,062][INFO ][o.e.d.DiscoveryModule ] [***] using discovery type [zen] and seed hosts providers [settings]
[2020-04-03T09:49:12,393][INFO ][o.e.n.Node ] [***] initialized
[2020-04-03T09:49:12,394][INFO ][o.e.n.Node ] [***] starting ...
[2020-04-03T09:49:12,548][INFO ][o.e.t.TransportService ] [***] publish_address {127.0.0.1:9300}, bound_addresses {[::1]:9300}, {127.0.0.1:9300}
[2020-04-03T09:49:12,557][WARN ][o.e.b.BootstrapChecks ] [***] the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
[2020-04-03T09:49:12,570][INFO ][o.e.c.c.ClusterBootstrapService] [***] no discovery configuration found, will perform best-effort cluster bootstrapping after [3s] unless existing master is discovered
[2020-04-03T09:49:22,575][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:49:32,580][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:49:42,582][WARN ][o.e.n.Node ] [***] timed out while waiting for initial discovery state - timeout: 30s
[2020-04-03T09:49:42,583][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:49:42,597][INFO ][o.e.h.AbstractHttpServerTransport] [***] publish_address {127.0.0.1:9200}, bound_addresses {[::1]:9200}, {127.0.0.1:9200}
[2020-04-03T09:49:42,598][INFO ][o.e.n.Node ] [***] started
[2020-04-03T09:49:46,456][DEBUG][o.e.a.a.c.h.TransportClusterHealthAction] [***] no known master node, scheduling a retry
[2020-04-03T09:49:52,589][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:49:56,461][DEBUG][o.e.a.a.c.h.TransportClusterHealthAction] [***] timed out while retrying [cluster:monitor/health] after failure (timeout [10s])
[2020-04-03T09:49:56,462][WARN ][r.suppressed ] [***] path: /_cluster/health, params: {wait_for_status=yellow, timeout=10s}
org.elasticsearch.discovery.MasterNotDiscoveredException: null
at org.elasticsearch.action.support.master.TransportMasterNodeAction$AsyncSingleAction$4.onTimeout(TransportMasterNodeAction.java:259) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.cluster.ClusterStateObserver$ContextPreservingListener.onTimeout(ClusterStateObserver.java:322) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.cluster.ClusterStateObserver$ObserverClusterStateListener.onTimeout(ClusterStateObserver.java:249) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.cluster.service.ClusterApplierService$NotifyTimeout.run(ClusterApplierService.java:555) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:681) [elasticsearch-7.0.0.jar:7.0.0]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) [?:?]
at java.lang.Thread.run(Thread.java:834) [?:?]
[2020-04-03T09:49:59,399][DEBUG][o.e.a.a.c.h.TransportClusterHealthAction] [***] no known master node, scheduling a retry
[2020-04-03T09:50:02,591][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:50:12,593][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:50:22,598][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:50:29,404][DEBUG][o.e.a.a.c.h.TransportClusterHealthAction] [***] timed out while retrying [cluster:monitor/health] after failure (timeout [30s])
[2020-04-03T09:50:29,406][WARN ][r.suppressed ] [***] path: /_cluster/health, params: {master_timeout=30s, level=cluster, timeout=30s}
org.elasticsearch.discovery.MasterNotDiscoveredException: null
at org.elasticsearch.action.support.master.TransportMasterNodeAction$AsyncSingleAction$4.onTimeout(TransportMasterNodeAction.java:259) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.cluster.ClusterStateObserver$ContextPreservingListener.onTimeout(ClusterStateObserver.java:322) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.cluster.ClusterStateObserver$ObserverClusterStateListener.onTimeout(ClusterStateObserver.java:249) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.cluster.service.ClusterApplierService$NotifyTimeout.run(ClusterApplierService.java:555) [elasticsearch-7.0.0.jar:7.0.0]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:681) [elasticsearch-7.0.0.jar:7.0.0]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) [?:?]
at java.lang.Thread.run(Thread.java:834) [?:?]
[2020-04-03T09:50:32,604][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:50:42,610][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:50:52,615][WARN ][o.e.c.c.ClusterFormationFailureHelper] [***] master not discovered or elected yet, an election requires two nodes with ids [K7837AAkSWGSz8lzZ2KuWg, lD8OpstvTIe1Uk_h3iEAOQ], have discovered [] which is not a quorum; discovery will continue using [127.0.0.1:9301, 127.0.0.1:9302, 127.0.0.1:9303, 127.0.0.1:9304, [::1]:9301, [::1]:9302, [::1]:9303, [::1]:9304] from hosts providers and [{***}{lD8OpstvTIe1Uk_h3iEAOQ}{sh6h73hTRpe0UjSJ-vJz6Q}{127.0.0.1}{127.0.0.1:9300}] from last-known cluster state; node term 326, last-accepted version 0 in term 0
[2020-04-03T09:50:56,585][INFO ][o.e.n.Node ] [***] stopping ...
[2020-04-03T09:50:56,637][INFO ][o.e.n.Node ] [***] stopped
[2020-04-03T09:50:56,637][INFO ][o.e.n.Node ] [***] closing ...
[2020-04-03T09:50:56,647][INFO ][o.e.n.Node ] [***] closed