Hey all!
Looking to get some use case ideas for a presentation at camundacon:
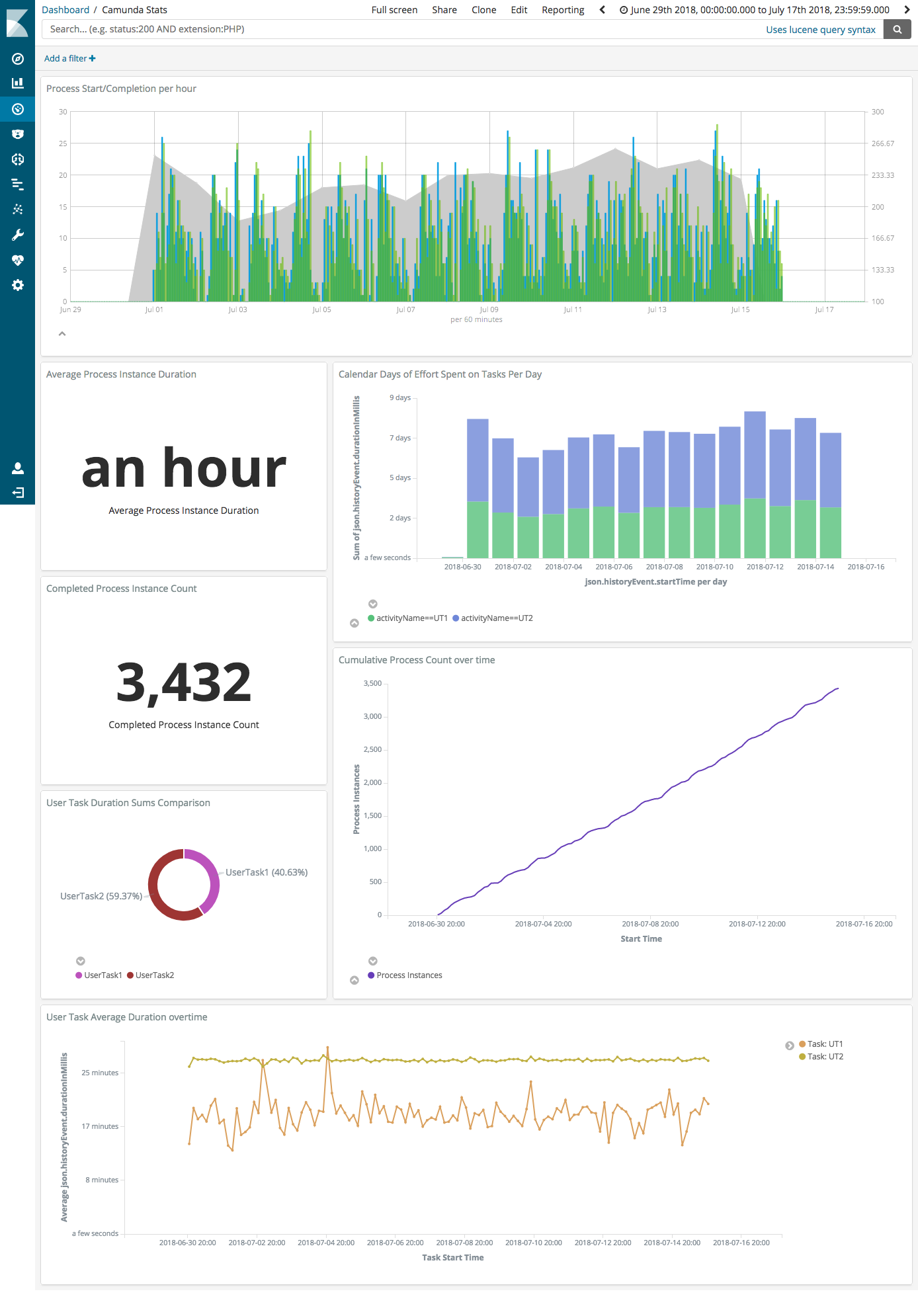
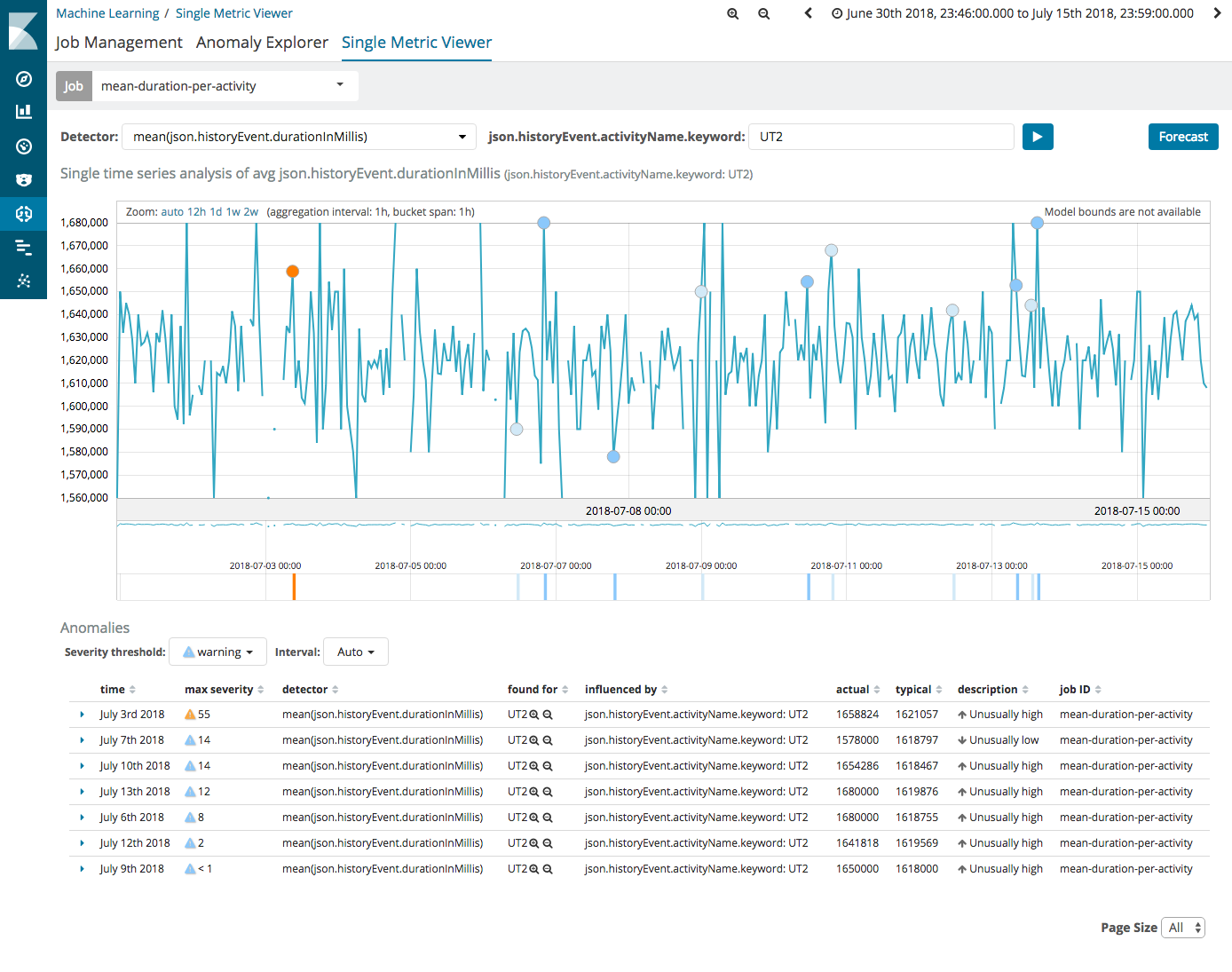
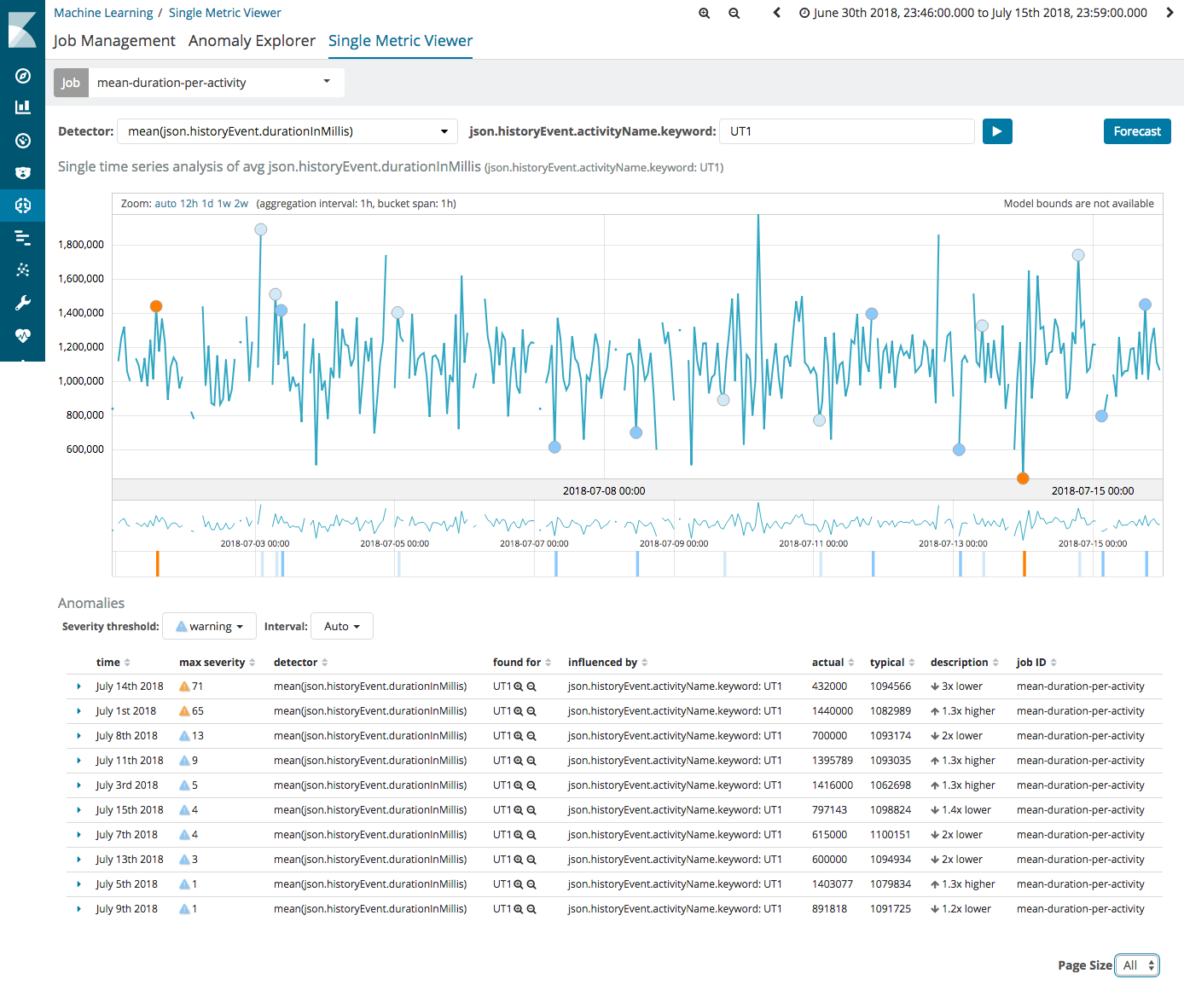
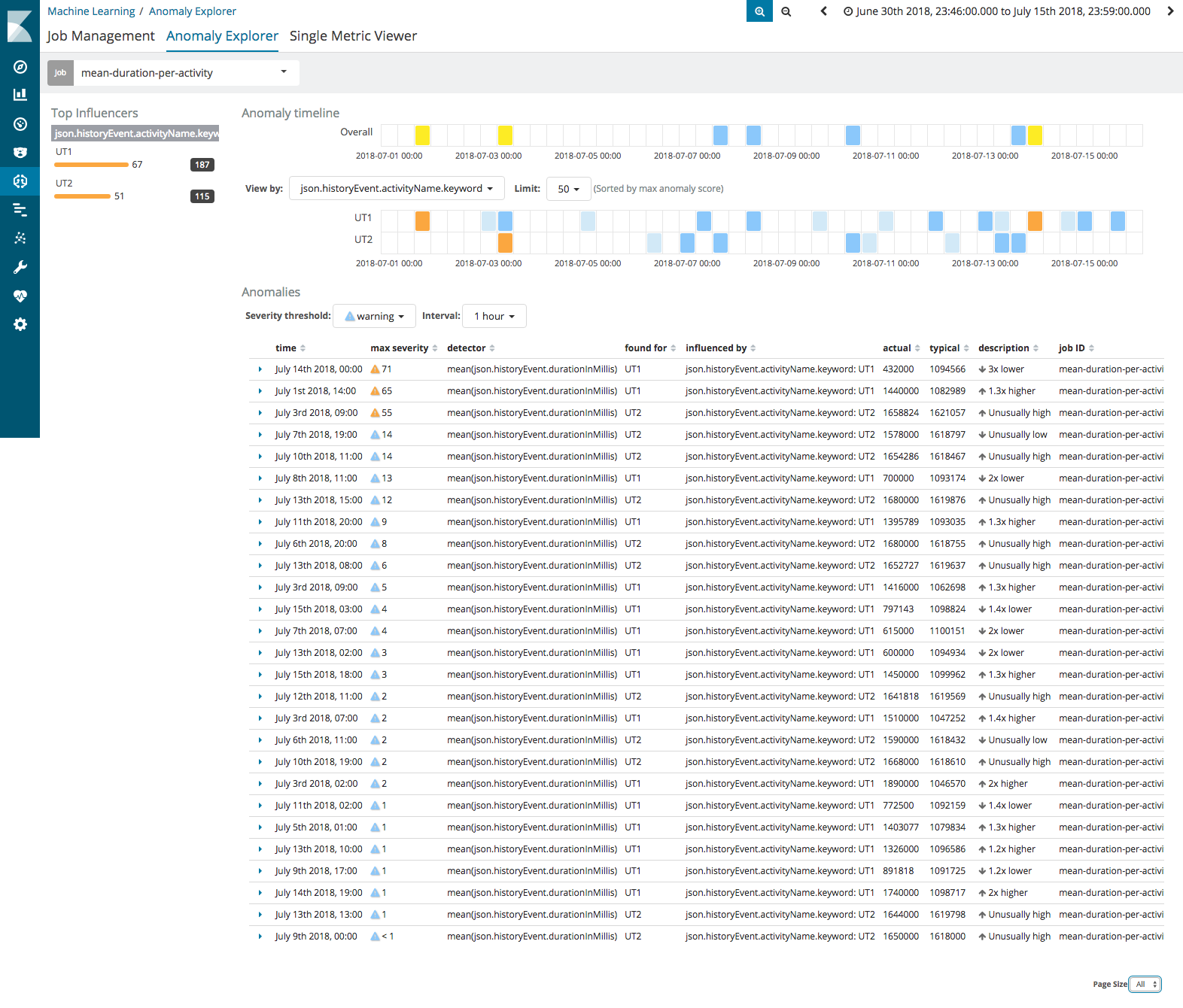
I am presenting on how you can use Camunda + Machine Learning, specifically Elastic Search and Kibana + xpack to provide machine learning reporting on whichever aspect of the BPMN processes.
Some simple use caes are things like:
- Task duration
- Variable values
- Users that start a specific process / unusual process usage
- Unusual variable value usage
- Process memory usage (if a process has a lot of variable usage / “fat” variables from binary data.
- BPMN Looping
- Multi-instance counts
- Business calendar usage (times of day, locations, times of month etc.)
- Incident occurrences and resolution times
- etc
So… I am looking for interesting problems you have in reporting, where you would like to see what ML can do. The more real the use case the better as it gives people something to bite into!
Thanks!
Hi Stephen,
A class of use cases I have is tuning of decision table values. Consider my recent blog post on face recognition. There are three outcomes, a very high match confidence, a very low match confidence and somewhere between. Hence I use a decision table to route to a user task for the in between cases, otherwise straight through processing. The trick is, what values to set the DMN confidence thresholds to. Hence the idea is to be quite conservative to start with and as the user task resolves a good match or no match, learn by example what the thresholds should be set to in order to reduce the incidence of referrals without introducing false positives… It could be that the image recognition performs differently based on age and gender etc. Hence the ML may inform much greater granularity.
This kind of pattern can be expanded to credit scoring etc…
P.S. - I guess this is really supervised learning, as the outcome has been determined by a person…
regards
Rob
 Yes a different model of ML for sure.
Yes a different model of ML for sure.
But question based on your use case: why is the dmn taking the management of deciding confidence value in the image analysis’ response? In my understanding, one would use the image analysis’ response / confidence % number as the indicator: if you felt that the system was not doing a good job for a certain sex or type of person, then that would be captured higher up in the chain to reduce the confidence% number that is returned by the image analysis. If you are doing it in the dmn, then all of that ML specific logic is being carried down into the dmn space rather than improving the overall confidence response of the ML tool.
A good use for un-supervised learning would be:
- Track the Success and Failures of the image analysis from the user task input/responses, and have it detect patterns and exceptions: Such as:
- A unusual amount of failures in a period of time
- Failures related to one or more attributes of the image (the metadata that is returned from the analysis: objects, race, sex, location, camera, etc)
- Failures related to a specific process or task, etc
Hi Stephen,
But question based on your use case: why is the dmn taking the management of deciding confidence value in the image analysis’ response?
To clarify, the facematch service is a blackbox which returns a confidence somewhere between 0% and 100% (in addition to age estimate, gender estimate etc).
The business drivers are;
straight through processing as much as possible (maximise efficiency).
No false positives (err on the side of caution).
Hence the DMN decision rules are;
- If confidence >= 95% then accept as a match
- If confidence <= 70% then reject as unmatched
- if 70 < match < 95 then refer.
The challenge I have is these values (70 and 95) are (conservatively) arbitrarily chosen as the characteristics of the black box face match are unknown. Thus the machine learning aspect is over time, learn what the rule parameters should be in order to meet the competing business drivers. In addition, a more sophisticated outcome is just dont tell me what these parameters should be, find me the set of parameters and their corresponding values which gives me the greatest discrimination in order to satisfy the business drivers.
From this perspective, I was thinking more along the lines of principle components analysis or a kohonen network. It could be a random forrest approach etc. For example, the ML may learn that for female images, if the difference between the actual age and the estimated age is large, then set the match threshold to 97%. If the actual age and the estimated age differnce is low, set the acceptance threshold to 88%.
An obvious question now could be, why use a DMN approach then, why not use the AI model to be the decison maker? The advanatge of the DMN table encoding the rules is it then becomes transparent and easily enforced in a commercial contract.
I hope that clarifies,
regards
Rob
Hi Stephen,
another fruitful area from my perspective is fraud detection based on unusual transactional patterns. The challenge here is what constitutes unusual? A common approach is to look at incidences outside 95th percentiles. A really cool capability is the ability to configure moving windows so that the 95th percentile is measured relative to the population of transactors over unit times.
Using moving windows to define the 95th percentile is useful as the threshold self tunes to seasonal variations as well as product popularity peaks and troughs. Not all incidents above thresholds are fraudulent, however this approach tends to focus limited forensic resources on the most likely locations.
Consider a branch network selling giftcards. Is there a branch or an individual selling more gift cards than anyone else in the same timeframe? Consider a spike in sales on a Saturday - is it because there is fraudulent activity and the perpetrator is going to skip the country on Sunday and thus get a day’s head start?
Ive typically wanted to do this in a complex event processor with temporal query capability. Thus I can define moving windows across when, who and where to derive 95th percentiles, then a second set of queries to extract where and who is exceeding the threshold for closer monitoring. Ive contemplated doing this in optimize, perhaps kibana is a better approach?
regards
Rob
Hi Stephen,
Outlier detection may a good example of fraud detection using UL. This specifically applies to expenses / purchase orders. There are multiple metrics that you can use for outliers / anomaly detection. For example Benford’s law is a good way to detect manipulated transactions in expense reports and POs. In this case a typical approach would be to split transactions by originator or department. If transactions for different originators / departments have different statistical nature (e.g. following and not following Benford’s law) this may be an indicator of an anomaly.
Another example is shown here: https://blog.easysol.net/advanced-outlier-detection/
Best regards,
Ilya
Using the ML tools of Elastic you can use Population outlier detection and provide key influencers. You just need to define the influencers that specific matter (transaction $ amount, department, location, etc). It also have Geo detection as well so you can leverage the same tools for location anomalies.
@Webcyberrob so we can look at examples of using:
https://www.elastic.co/guide/en/x-pack/current/ml-rare-functions.html
and also we can look at using Pipeline aggregations to create a Moving Average and then route that average into the ML stream. That would give you a lot of the moving window.
The giftcards is a great use case.