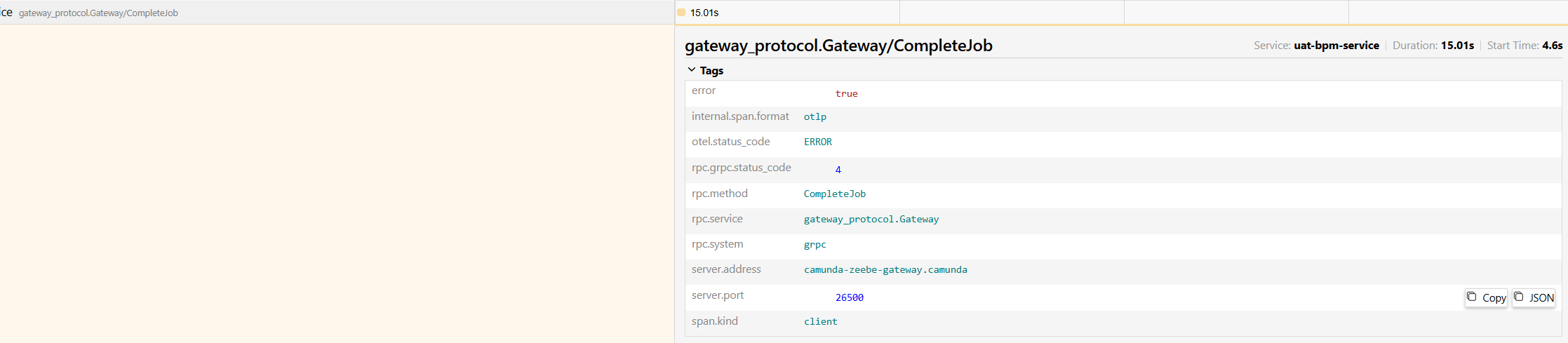
**Describe the bug**
While executing processes on zeebe we intermittently get… errors on the zeebe client, broker and gateway.
We have 20 workers for each worker type. This is the reason we are guessing that workflow continues to get processed (despite the
errors) but this leads to slow processing times and increasing log dumps.
Similar errors were reported in the past reported [here](https://github.com/camunda/zeebe/issues/11864) but those were during a load test while this one is in an environment that hardly has 2 processes being executed in a minute.
**To Reproduce**
We have seen this error constantly in our zeebe client logs but can't find a pattern or a specific process that reproduces this. We could just guess that this could be because of processes that have high state to maintain.
It would be great if someone from the zeebe team could analyse the logs to understand the root cause/ workarounds/ troubleshooting tips.
**Expected behavior**
No errors in the client, broker and gateway logs.
**Log/Stacktrace**
Below are the logs in the zeebe client
<details><summary>Zeebe Client Full Stacktrace</summary>
<p>
```
{"@timestamp":"2023-11-14T11:42:59.977098319Z","@version":"1","message":"Failed to activate jobs for worker mbxworker_8 and job type mbx","logger_name":"io.camunda.zeebe.client.job.poller","thread_name":"grpc-default-executor-134","level":"WARN","level_value":30000,"stack_trace":"io.grpc.StatusRuntimeException: UNAVAILABLE: io exception\n\tat io.grpc.Status.asRuntimeException(Status.java:539)\n\tat io.grpc.stub.ClientCalls$StreamObserverToCallListenerAdapter.onClose(ClientCalls.java:487)\n\tat io.grpc.internal.ClientCallImpl.closeObserver(ClientCallImpl.java:576)\n\tat io.grpc.internal.ClientCallImpl.access$300(ClientCallImpl.java:70)\n\tat io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInternal(ClientCallImpl.java:757)\n\tat io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInContext(ClientCallImpl.java:736)\n\tat io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37)\n\tat io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:133)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)\n\tat java.base/java.lang.Thread.run(Unknown Source)\nCaused by: java.io.IOException: Connection reset by peer\n\tat java.base/sun.nio.ch.FileDispatcherImpl.write0(Native Method)\n\tat java.base/sun.nio.ch.SocketDispatcher.write(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.writeFromNativeBuffer(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.write(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.write(Unknown Source)\n\tat java.base/sun.nio.ch.SocketChannelImpl.write(Unknown Source)\n\tat io.netty.channel.socket.nio.NioSocketChannel.doWrite(NioSocketChannel.java:415)\n\tat io.netty.channel.AbstractChannel$AbstractUnsafe.flush0(AbstractChannel.java:931)\n\tat io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.flush0(AbstractNioChannel.java:354)\n\tat io.netty.channel.AbstractChannel$AbstractUnsafe.flush(AbstractChannel.java:895)\n\tat io.netty.channel.DefaultChannelPipeline$HeadContext.flush(DefaultChannelPipeline.java:1372)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeFlush0(AbstractChannelHandlerContext.java:921)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeFlush(AbstractChannelHandlerContext.java:907)\n\tat io.netty.channel.AbstractChannelHandlerContext.flush(AbstractChannelHandlerContext.java:893)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler.onError(Http2ConnectionHandler.java:656)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler$FrameDecoder.decode(Http2ConnectionHandler.java:395)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler.decode(Http2ConnectionHandler.java:453)\n\tat io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:529)\n\tat io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:468)\n\tat io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:290)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:444)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)\n\tat io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)\n\tat io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:440)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)\n\tat io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)\n\tat io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:166)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:788)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:724)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:650)\n\tat io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:562)\n\tat io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)\n\tat io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)\n\tat io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)\n\t... 1 common frames omitted\n"}
{"@timestamp":"2023-11-14T11:42:59.97727889Z","@version":"1","message":"Failed to activate jobs for worker mbxworker_2 and job type mbx","logger_name":"io.camunda.zeebe.client.job.poller","thread_name":"grpc-default-executor-129","level":"WARN","level_value":30000,"stack_trace":"io.grpc.StatusRuntimeException: UNAVAILABLE: io exception\n\tat io.grpc.Status.asRuntimeException(Status.java:539)\n\tat io.grpc.stub.ClientCalls$StreamObserverToCallListenerAdapter.onClose(ClientCalls.java:487)\n\tat io.grpc.internal.ClientCallImpl.closeObserver(ClientCallImpl.java:576)\n\tat io.grpc.internal.ClientCallImpl.access$300(ClientCallImpl.java:70)\n\tat io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInternal(ClientCallImpl.java:757)\n\tat io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInContext(ClientCallImpl.java:736)\n\tat io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37)\n\tat io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:133)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)\n\tat java.base/java.lang.Thread.run(Unknown Source)\nCaused by: java.io.IOException: Connection reset by peer\n\tat java.base/sun.nio.ch.FileDispatcherImpl.write0(Native Method)\n\tat java.base/sun.nio.ch.SocketDispatcher.write(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.writeFromNativeBuffer(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.write(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.write(Unknown Source)\n\tat java.base/sun.nio.ch.SocketChannelImpl.write(Unknown Source)\n\tat io.netty.channel.socket.nio.NioSocketChannel.doWrite(NioSocketChannel.java:415)\n\tat io.netty.channel.AbstractChannel$AbstractUnsafe.flush0(AbstractChannel.java:931)\n\tat io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.flush0(AbstractNioChannel.java:354)\n\tat io.netty.channel.AbstractChannel$AbstractUnsafe.flush(AbstractChannel.java:895)\n\tat io.netty.channel.DefaultChannelPipeline$HeadContext.flush(DefaultChannelPipeline.java:1372)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeFlush0(AbstractChannelHandlerContext.java:921)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeFlush(AbstractChannelHandlerContext.java:907)\n\tat io.netty.channel.AbstractChannelHandlerContext.flush(AbstractChannelHandlerContext.java:893)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler.onError(Http2ConnectionHandler.java:656)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler$FrameDecoder.decode(Http2ConnectionHandler.java:395)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler.decode(Http2ConnectionHandler.java:453)\n\tat io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:529)\n\tat io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:468)\n\tat io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:290)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:444)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)\n\tat io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)\n\tat io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:440)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)\n\tat io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)\n\tat io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:166)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:788)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:724)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:650)\n\tat io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:562)\n\tat io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)\n\tat io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)\n\tat io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)\n\t... 1 common frames omitted\n"}
{"@timestamp":"2023-11-14T11:42:59.977529355Z","@version":"1","message":"Failed to activate jobs for worker datatransformationworker_13 and job type data-transform","logger_name":"io.camunda.zeebe.client.job.poller","thread_name":"grpc-default-executor-130","level":"WARN","level_value":30000,"stack_trace":"io.grpc.StatusRuntimeException: UNAVAILABLE: io exception\n\tat io.grpc.Status.asRuntimeException(Status.java:539)\n\tat io.grpc.stub.ClientCalls$StreamObserverToCallListenerAdapter.onClose(ClientCalls.java:487)\n\tat io.grpc.internal.ClientCallImpl.closeObserver(ClientCallImpl.java:576)\n\tat io.grpc.internal.ClientCallImpl.access$300(ClientCallImpl.java:70)\n\tat io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInternal(ClientCallImpl.java:757)\n\tat io.grpc.internal.ClientCallImpl$ClientStreamListenerImpl$1StreamClosed.runInContext(ClientCallImpl.java:736)\n\tat io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37)\n\tat io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:133)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)\n\tat java.base/java.lang.Thread.run(Unknown Source)\nCaused by: java.io.IOException: Connection reset by peer\n\tat java.base/sun.nio.ch.FileDispatcherImpl.write0(Native Method)\n\tat java.base/sun.nio.ch.SocketDispatcher.write(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.writeFromNativeBuffer(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.write(Unknown Source)\n\tat java.base/sun.nio.ch.IOUtil.write(Unknown Source)\n\tat java.base/sun.nio.ch.SocketChannelImpl.write(Unknown Source)\n\tat io.netty.channel.socket.nio.NioSocketChannel.doWrite(NioSocketChannel.java:415)\n\tat io.netty.channel.AbstractChannel$AbstractUnsafe.flush0(AbstractChannel.java:931)\n\tat io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.flush0(AbstractNioChannel.java:354)\n\tat io.netty.channel.AbstractChannel$AbstractUnsafe.flush(AbstractChannel.java:895)\n\tat io.netty.channel.DefaultChannelPipeline$HeadContext.flush(DefaultChannelPipeline.java:1372)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeFlush0(AbstractChannelHandlerContext.java:921)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeFlush(AbstractChannelHandlerContext.java:907)\n\tat io.netty.channel.AbstractChannelHandlerContext.flush(AbstractChannelHandlerContext.java:893)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler.onError(Http2ConnectionHandler.java:656)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler$FrameDecoder.decode(Http2ConnectionHandler.java:395)\n\tat io.netty.handler.codec.http2.Http2ConnectionHandler.decode(Http2ConnectionHandler.java:453)\n\tat io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:529)\n\tat io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:468)\n\tat io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:290)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:444)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)\n\tat io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)\n\tat io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:440)\n\tat io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)\n\tat io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)\n\tat io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:166)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:788)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:724)\n\tat io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:650)\n\tat io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:562)\n\tat io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)\n\tat io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)\n\tat io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)\n\t... 1 common frames omitted\n"}
```
</p>
</details>
<details><summary>Zeebe Broker Full Stacktrace</summary>
<p>
```
{"timestamp":"06:13:05.526","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"WARN ", "logger":"io.atomix.cluster.protocol.swim.probe","message":"0 - Failed to probe sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl java.util.concurrent.TimeoutException: Request ProtocolRequest{id=999587, subject=atomix-membership-probe, sender=sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502, payload=byte[]{length=808, hash=1299715342}} to 10.42.0.108:26502 timed out in PT0.1S\n\tat io.atomix.cluster.messaging.impl.NettyMessagingService.lambda$sendAndReceive$4(NettyMessagingService.java:251)\n\tat java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)\n\tat java.base/java.util.concurrent.FutureTask.run(Unknown Source)\n\tat java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)\n\tat io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)\n\tat java.base/java.lang.Thread.run(Unknown Source)\n"}
{"timestamp":"06:13:05.526","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim.probe","message":"0 - Failed all probes of Member{id=sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl, address=10.42.0.108:26502, properties={event-service-topics-subscribed=KIIDAGpvYnNBdmFpbGFibOU=}}. Marking as suspect. "}
{"timestamp":"06:13:05.526","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim","message":"0 - Member unreachable Member{id=sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl, address=10.42.0.108:26502, properties={event-service-topics-subscribed=KIIDAGpvYnNBdmFpbGFibOU=}} "}
{"timestamp":"06:13:06.529","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim","message":"0 - Member reachable Member{id=sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl, address=10.42.0.108:26502, properties={event-service-topics-subscribed=KIIDAGpvYnNBdmFpbGFibOU=}} "}
{"timestamp":"06:13:43.807","actor":"[SnapshotStore-1]","thread":"[zb-fs-workers-2]","log_level":"INFO ", "logger":"io.camunda.zeebe.snapshots.impl.FileBasedSnapshotStore","message":"Committed new snapshot 7021506-8-12438075-12438078 "}
```
</p>
</details>
<details><summary>Zeebe Gateway Full Stacktrace</summary>
<p>
```
Nov 14, 2023 1:22:08 AM io.grpc.netty.NettyServerHandler onStreamError
WARNING: Stream Error
io.netty.handler.codec.http2.Http2Exception$StreamException: Stream closed before write could take place
at io.netty.handler.codec.http2.Http2Exception.streamError(Http2Exception.java:173)
at io.netty.handler.codec.http2.DefaultHttp2RemoteFlowController$FlowState.cancel(DefaultHttp2RemoteFlowController.java:481)
at io.netty.handler.codec.http2.DefaultHttp2RemoteFlowController$1.onStreamClosed(DefaultHttp2RemoteFlowController.java:105)
at io.netty.handler.codec.http2.DefaultHttp2Connection.notifyClosed(DefaultHttp2Connection.java:357)
at io.netty.handler.codec.http2.DefaultHttp2Connection$ActiveStreams.removeFromActiveStreams(DefaultHttp2Connection.java:1007)
at io.netty.handler.codec.http2.DefaultHttp2Connection$ActiveStreams.deactivate(DefaultHttp2Connection.java:963)
at io.netty.handler.codec.http2.DefaultHttp2Connection$DefaultStream.close(DefaultHttp2Connection.java:515)
at io.netty.handler.codec.http2.DefaultHttp2Connection$DefaultStream.close(DefaultHttp2Connection.java:521)
at io.netty.handler.codec.http2.Http2ConnectionHandler.doCloseStream(Http2ConnectionHandler.java:921)
at io.netty.handler.codec.http2.Http2ConnectionHandler.closeStream(Http2ConnectionHandler.java:629)
at io.netty.handler.codec.http2.DefaultHttp2ConnectionDecoder$FrameReadListener.onRstStreamRead(DefaultHttp2ConnectionDecoder.java:444)
at io.netty.handler.codec.http2.Http2InboundFrameLogger$1.onRstStreamRead(Http2InboundFrameLogger.java:80)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.readRstStreamFrame(DefaultHttp2FrameReader.java:509)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.processPayloadState(DefaultHttp2FrameReader.java:259)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.readFrame(DefaultHttp2FrameReader.java:159)
at io.netty.handler.codec.http2.Http2InboundFrameLogger.readFrame(Http2InboundFrameLogger.java:41)
at io.netty.handler.codec.http2.DefaultHttp2ConnectionDecoder.decodeFrame(DefaultHttp2ConnectionDecoder.java:173)
at io.netty.handler.codec.http2.Http2ConnectionHandler$FrameDecoder.decode(Http2ConnectionHandler.java:393)
at io.netty.handler.codec.http2.Http2ConnectionHandler.decode(Http2ConnectionHandler.java:453)
at io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:529)
at io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:468)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:290)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:444)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:440)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)
at io.netty.channel.epoll.AbstractEpollStreamChannel$EpollStreamUnsafe.epollInReady(AbstractEpollStreamChannel.java:800)
at io.netty.channel.epoll.EpollEventLoop.processReady(EpollEventLoop.java:509)
at io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:407)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.base/java.lang.Thread.run(Unknown Source)
Nov 14, 2023 1:22:08 AM io.grpc.netty.NettyServerHandler onStreamError
WARNING: Stream Error
io.netty.handler.codec.http2.Http2Exception$StreamException: Stream closed before write could take place
at io.netty.handler.codec.http2.Http2Exception.streamError(Http2Exception.java:173)
at io.netty.handler.codec.http2.DefaultHttp2RemoteFlowController$FlowState.cancel(DefaultHttp2RemoteFlowController.java:481)
at io.netty.handler.codec.http2.DefaultHttp2RemoteFlowController$1.onStreamClosed(DefaultHttp2RemoteFlowController.java:105)
at io.netty.handler.codec.http2.DefaultHttp2Connection.notifyClosed(DefaultHttp2Connection.java:357)
at io.netty.handler.codec.http2.DefaultHttp2Connection$ActiveStreams.removeFromActiveStreams(DefaultHttp2Connection.java:1007)
at io.netty.handler.codec.http2.DefaultHttp2Connection$ActiveStreams.deactivate(DefaultHttp2Connection.java:963)
at io.netty.handler.codec.http2.DefaultHttp2Connection$DefaultStream.close(DefaultHttp2Connection.java:515)
at io.netty.handler.codec.http2.DefaultHttp2Connection$DefaultStream.close(DefaultHttp2Connection.java:521)
at io.netty.handler.codec.http2.Http2ConnectionHandler.doCloseStream(Http2ConnectionHandler.java:921)
at io.netty.handler.codec.http2.Http2ConnectionHandler.closeStream(Http2ConnectionHandler.java:629)
at io.netty.handler.codec.http2.DefaultHttp2ConnectionDecoder$FrameReadListener.onRstStreamRead(DefaultHttp2ConnectionDecoder.java:444)
at io.netty.handler.codec.http2.Http2InboundFrameLogger$1.onRstStreamRead(Http2InboundFrameLogger.java:80)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.readRstStreamFrame(DefaultHttp2FrameReader.java:509)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.processPayloadState(DefaultHttp2FrameReader.java:259)
at io.netty.handler.codec.http2.DefaultHttp2FrameReader.readFrame(DefaultHttp2FrameReader.java:159)
at io.netty.handler.codec.http2.Http2InboundFrameLogger.readFrame(Http2InboundFrameLogger.java:41)
at io.netty.handler.codec.http2.DefaultHttp2ConnectionDecoder.decodeFrame(DefaultHttp2ConnectionDecoder.java:173)
at io.netty.handler.codec.http2.Http2ConnectionHandler$FrameDecoder.decode(Http2ConnectionHandler.java:393)
at io.netty.handler.codec.http2.Http2ConnectionHandler.decode(Http2ConnectionHandler.java:453)
at io.netty.handler.codec.ByteToMessageDecoder.decodeRemovalReentryProtection(ByteToMessageDecoder.java:529)
at io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:468)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:290)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:444)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:412)
at io.netty.channel.DefaultChannelPipeline$HeadContext.channelRead(DefaultChannelPipeline.java:1410)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:440)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:420)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:919)
at io.netty.channel.epoll.AbstractEpollStreamChannel$EpollStreamUnsafe.epollInReady(AbstractEpollStreamChannel.java:800)
at io.netty.channel.epoll.EpollEventLoop.processReady(EpollEventLoop.java:509)
at io.netty.channel.epoll.EpollEventLoop.run(EpollEventLoop.java:407)
at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:997)
at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74)
at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)
at java.base/java.lang.Thread.run(Unknown Source)
{"timestamp":"01:22:09.656","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"WARN ", "logger":"io.atomix.cluster.protocol.swim.probe","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Failed to probe 0 java.util.concurrent.TimeoutException: Request ProtocolRequest{id=3671531, subject=atomix-membership-probe, sender=10.42.0.108:26502, payload=byte[]{length=807, hash=1671211815}} to sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502 timed out in PT0.1S\n\tat io.atomix.cluster.messaging.impl.NettyMessagingService.lambda$sendAndReceive$4(NettyMessagingService.java:251)\n\tat java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)\n\tat java.base/java.util.concurrent.FutureTask.run(Unknown Source)\n\tat java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)\n\tat io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)\n\tat java.base/java.lang.Thread.run(Unknown Source)\n"}
{"timestamp":"01:22:09.656","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim.probe","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Failed all probes of Member{id=0, address=sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502, properties={brokerInfo=EADJAAAAAwAAAAAAAQAAAAEAAAABAAAAAAABCgAAAGNvbW1hbmRBcGlRAAAAc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLTAuc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLmRlZmF1bHQuc3ZjOjI2NTAxBQABAQAAAAAMAAEBAAAACAAAAAAAAAAGAAAAOC4yLjEyBQABAQAAAAE=}}. Marking as suspect. "}
{"timestamp":"01:22:09.656","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Member unreachable Member{id=0, address=sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502, properties={brokerInfo=EADJAAAAAwAAAAAAAQAAAAEAAAABAAAAAAABCgAAAGNvbW1hbmRBcGlRAAAAc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLTAuc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLmRlZmF1bHQuc3ZjOjI2NTAxBQABAQAAAAAMAAEBAAAACAAAAAAAAAAGAAAAOC4yLjEyBQABAQAAAAE=}} "}
{"timestamp":"01:22:11.660","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Member reachable Member{id=0, address=sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502, properties={brokerInfo=EADJAAAAAwAAAAAAAQAAAAEAAAABAAAAAAABCgAAAGNvbW1hbmRBcGlRAAAAc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLTAuc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLmRlZmF1bHQuc3ZjOjI2NTAxBQABAQAAAAAMAAEBAAAACAAAAAAAAAAGAAAAOC4yLjEyBQABAQAAAAE=}} "}
{"timestamp":"01:22:51.827","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"WARN ", "logger":"io.atomix.cluster.protocol.swim.probe","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Failed to probe 0 java.util.concurrent.TimeoutException: Request ProtocolRequest{id=3671586, subject=atomix-membership-probe, sender=10.42.0.108:26502, payload=byte[]{length=807, hash=-1469364055}} to sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502 timed out in PT0.1S\n\tat io.atomix.cluster.messaging.impl.NettyMessagingService.lambda$sendAndReceive$4(NettyMessagingService.java:251)\n\tat java.base/java.util.concurrent.Executors$RunnableAdapter.call(Unknown Source)\n\tat java.base/java.util.concurrent.FutureTask.run(Unknown Source)\n\tat java.base/java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)\n\tat java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)\n\tat io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30)\n\tat java.base/java.lang.Thread.run(Unknown Source)\n"}
{"timestamp":"01:22:51.827","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim.probe","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Failed all probes of Member{id=0, address=sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502, properties={brokerInfo=EADJAAAAAwAAAAAAAQAAAAEAAAABAAAAAAABCgAAAGNvbW1hbmRBcGlRAAAAc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLTAuc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLmRlZmF1bHQuc3ZjOjI2NTAxBQABAQAAAAAMAAEBAAAACAAAAAAAAAAGAAAAOC4yLjEyBQABAQAAAAE=}}. Marking as suspect. "}
{"timestamp":"01:22:51.827","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Member unreachable Member{id=0, address=sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502, properties={brokerInfo=EADJAAAAAwAAAAAAAQAAAAEAAAABAAAAAAABCgAAAGNvbW1hbmRBcGlRAAAAc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLTAuc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLmRlZmF1bHQuc3ZjOjI2NTAxBQABAQAAAAAMAAEBAAAACAAAAAAAAAAGAAAAOC4yLjEyBQABAQAAAAE=}} "}
{"timestamp":"01:22:53.830","actor":"[]","thread":"[atomix-cluster-heartbeat-sender]","log_level":"INFO ", "logger":"io.atomix.cluster.protocol.swim","message":"sunrise-workflow-camunda-zeebe-gateway-5496669764-htjsl - Member reachable Member{id=0, address=sunrise-workflow-camunda-zeebe-0.sunrise-workflow-camunda-zeebe.default.svc:26502, properties={brokerInfo=EADJAAAAAwAAAAAAAQAAAAEAAAABAAAAAAABCgAAAGNvbW1hbmRBcGlRAAAAc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLTAuc3VucmlzZS13b3JrZmxvdy1jYW11bmRhLXplZWJlLmRlZmF1bHQuc3ZjOjI2NTAxBQABAQAAAAAMAAEBAAAACAAAAAAAAAAGAAAAOC4yLjEyBQABAQAAAAE=}} "}
Nov 14, 2023 1:23:08 AM io.grpc.netty.NettyServerHandler onStreamError
WARNING: Stream Error
```
</p>
</details>
**Environment:**
- OS: Linux
- Zeebe Version: 8.2.12
- Configuration: Hazelcast exporter