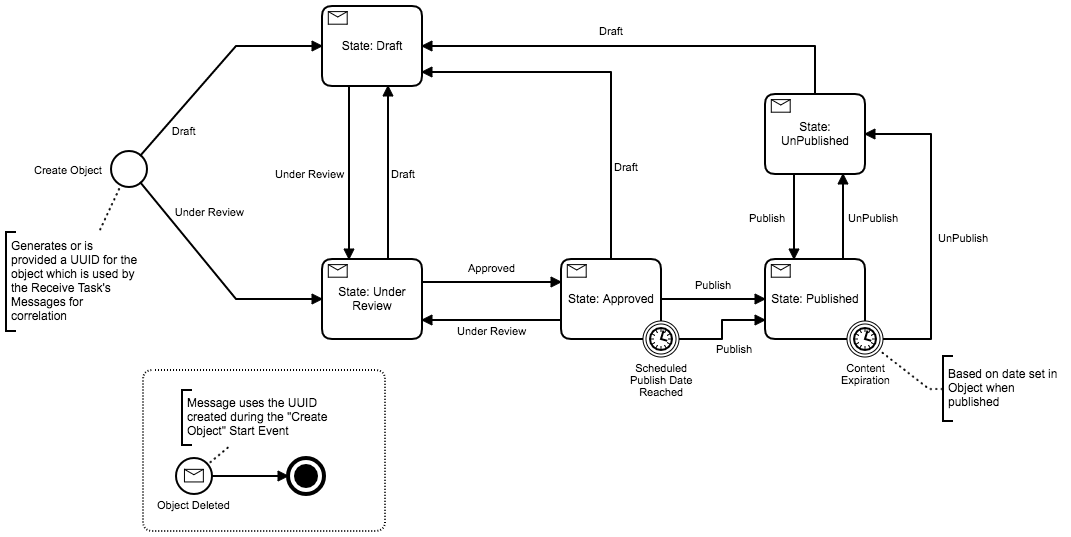
Given content management implies a more object centered or document-centric approach to process modeling, maybe a CMMN model provides a better illustration? For example, a document’s state may go directly from “published” back to “draft” - this implying a person/worker noticed an error, and outside the context of the process model, set the content’s “review” status to something like “contains errors” (i.e. draft-state).
Now, regardless of the token’s position in our process model, it must jump from “state:published” to “state: draft” - basically representing the need for cross-cutting a BPMN model so that all tasks become reasonably accessible regardless of path. Hence, CMMN is the better solution.
BPMN models tend to “straight-jacket” documents into activities - as described above in an absence of path from “published” to “draft”. Acknowledging that your model doesn’t represent actual activities… though implied given a request for “state-machine-style” (also taking a liberal position for discussion).
Given need for document-centric design (content state machine), we’re looking at case management… (Van der Aalst):
The core features of case handling are:
• avoid context tunneling by providing all information available (i.e., present the case as a whole rather than showing just bits and pieces),
• decide which activities are enabled on the basis of the information available rather than the activities already executed,
• separate work distribution from authorization and allow for additional types of roles, not just the execute role,
• allow workers to view and add/modify data before or after the corresponding activities have been executed (e.g., information can be registered the moment it becomes available).
See:
Van der Aalst, Wil MP, Mathias Weske, and Dolf Grünbauer. “Case handling: a new paradigm for business process support.” Data & Knowledge Engineering 53.2 (2005): 129-162.