After discussions in the thread here I start this dedicated topic to discuss the development of the GraphQL extension (open source project).
Adding GraphQL means adding another query API to Camunda, see the Docs here:
So…
Any thoughts from you guys on how to setup the right Camunda development environment / Camuda setup to develop such a GraphQL extension?
Are there any technical prerequisites like JEE / Spring we should/must consider?
Do you know if there any other members of the Camunda community considering GraphQL as well? Are there any started projects aiming in the same direction?
(I haven’t found anything yet)
Great that you want to contribute to the Camunda community. I’ll try to answer your specific questions tomorrow. If you haven’t done this yet, you may want to read the guide on code contributions as an introduction to how code contributions can look like.
The answers to your questions depend on whether you want this to become a part of the Camunda core or a Camunda community extension (see the link in my previous post for the difference). So I’ll comment on this decision first. From how I understand GraphQL and the scope of your idea, I recommend to go with a community extension. It is a non-trivial issue you are tackling and in a community extension you have more freedom in choice of technologies, implementation, features and releases. I think this is useful to get something out there that users can try out in a reasonable amount of time. Also, there’s still the possibility to make it part of the Camunda core in the future. Lastly, this would avoid/postpone the question if Camunda as a company can maintain and support a GraphQL API.
So, given we are talking about a community extension, my answers to your questions are:
Just start out with a Maven project and camunda-engine as a dependency. I can’t comment on the GraphQL side of development, as I heard yesterday for the first time about it . Repository-wise, I would we move this into the Camunda organization once we have a simple proof of concept that validates the idea.
This is very much up to you. Camunda engine requires Java 6+ and has a rather small set of dependencies. One of those is spring-beans that is used to bootstrap the process engine, but it runs without Spring and we don’t program against Spring interfaces. For example, you can choose Spring and Java 8 to build your extension, if this makes development easier for you. The more technologies you require the smaller your potential user base gets, which is why I personally tend to build things with as little dependencies as possible. As an example, the camunda spring boot starter extension chose to go with Java 8.
As stated above, I heard of GraphQL yesterday for the first time. There is no ongoing project in Camunda as a company or the community extension space on this topic. I would like to hear other users’ opinions on GraphQL and your idea.
Let us know if you have further questions, for example on the core codebase vs extension issue. I’m happy to help with technical questions if you provide some context on the GraphQL side of things. I’m curious if you are envisioning to build this on top of the Camunda Java API or on top of the Camunda database schema (i.e. GraphQL implementation making direct SQL queries).
Hi @thorben,
Thanks, great answer and as always you guys provide quick and good help here.
So, yes, I also think of a Community Extension in the first place. I also agree to keep things as easy as possible.
Since we stick pretty much with node.js/express in the last couple of month and the GraphQL reference implementation is in JavaScript and therefore some real cool tools and libraries for GraphQL are actually written in JavaScript, I am looking for something to bridge the Java and JavaScript worlds here.
The options I found are:
a Java-JavaScript-Bridge like node-java or - as you point out at the end of your reply
the direct access of the Camunda database…can be easily connected from the JavaScript/nodes.js-App.
Here we can ask: do you allow direct DB mutations?
The third option - to make it more complete - would be
3) graphql-java - as the name says it’s a GraphQL Java implementation. In this case the GraphQL server would be written in Java (which I hesitate to do in the case of GraphQL).
So, lets check this points in more detail:
node-java at least seems to allow a Camunda Process-Engine (JVM) to live inside a JavaScript/node.js App. This would be the ‘Camunda embedded’ deployment pattern - inside JavaScript. But what about an already running Camunda Process-Engine JVM - how do I connect to this JVM Java-API from within the JavaScript/node.js-App. node-java does not give me an answer yet, but since they seem to use JNI it might work…
Some remarks here:
we need something real fast and directly connected to the Camunda core, so I believe the REST-API is not an option (although its valuable for other use cases). REST would diminish the advantages of GraphQL (something like DataLoader could bring some relief here and help out through caching and batching, but the basic problems of REST remain)
Another bridge technology could be a Message-Queue (e.g. RabbitMQ) - but I am afraid of too much integration work in the Java and the JavaScript side. But maybe that is exactly the best solution here…?
I did not invest in JNI. JNI would allow to call the Camunda JVM and the Java API from another Application, here it would be the GraphQL-JavaScript/node.js-Server. Maybe this node-java does exactly that, I need to figure it out…
For the second point I am a little bit scared, because normally you are told not to do such bad things as directly connecting to the database when there are nice APIs available for a good reason.
Anyway, lets elaborate on this point a little bit:
GraphQL is a specification that defines a query languages for your data / API. It also defines ‘mutations’. This means we can potentially change data (through the implemented resolvers behind the scenes that do the magic) and so can consumers of the GraphQL API, when mutations are made available.
Question is: Does Camunda encourage or “not disallow” direct DB-mutations by using a direct Camunda database connection? Would that be accepted by customers? I doubt it a little bit. I see problems. But maybe with the blessing from Camunda we can make it happen?
better performance, especially for queries that aggregate a lot of data; also avoids 1 + n queries problem (e.g.
less complexity when developing GraphQL client Javascript
Cons
Mutations can be hard to get right. There are simple things like changing a user’s name, but there are also complex things like starting a process instance.
Mapping database rows to GraphQL schema entities may be non-trivial (e.g. process variables)
Getting authorization checks right may be non-trivial
Using Java API
Pros
Mutations and queries do the right things, assured by the camunda-engine test suite
Cons
It’s Java, so added complexity when used from a node application
Worse performance, as you still make multiple queries to the relational database; it’s just the multiple HTTP requests, that GraphQL would save us here
My 2 cents
If you want the GraphQL extension to become as powerful as the REST API in terms of mutations, then I would strongly suggest to go with the Java API. Building an API on top of the relational database schema is what we do for product development here at Camunda, so a couple of years have gone into that task already. Rebuilding this in another language will be a major effort and getting this production-ready would impose a high testing effort. However, Camunda does not forbid doing this
If query performance becomes an issue, you could also think about a hybrid approach, i.e. where mutations access the Java API, but queries go directly against the SQL database. For querying, the complexity to rebuild the API is not as high but still significant.
As a next step, I investigate how the node.js-Java integration works. I am not a node-js-guy, but I am happy to help you with getting the Java side right (e.g. how to work with shared engine scenario?). Using a message queue for bridging the technology gap sounds overkill and not so robust.
I dropped Node.js for the Camunda-GraphQL-Server. The whole Java-Javascript-bridge makes it too complicated.
So… back to 100% Java…
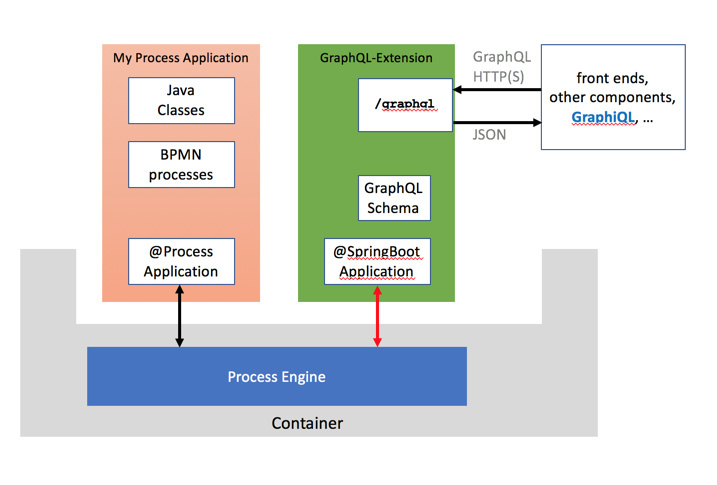
I setup a prototypical GraphQL-Extension (picture below: green) based on GraphQL Java Tools as a Spring Boot Application. I deployed this Spring Boot Application on a Camunda BPM 7.6. Server (Tomcat), which is configured running a shared Process Engine i.e. container managed. Beside the deployed GraphQL-Extension you can deploy whatever Process Application you like in the same container - all deployed applications run in parallel to the GraphQL-Extension.
I am still on track with this setup? (to build a GraphQL extension)
Sounds good to me. Feel free to share code at any time.
What ist the best way to access the Camunda Java API i.e. the running Process Engine from the GraphQL-Extension (green part)?
You could use BpmPlatform#getProcessEngineService or ProcessEngines#getProcessEngine. The latter should also work in an embedded engine setup. Here’s how we do it in the REST API:
The GraphQL part is running in a separate WAR, i.e. a different ClassLoader than the BpmPlatform was loaded. Are you sure just using BpmPlatform as described above is enough?
Maybe I have misunderstood something, but my process engine (here: pi) is always null:
Quick snippet:
@Component
public class ContainerManagedProcessEngineProvider {
private ProcessEngine pi;
public ContainerManagedProcessEngineProvider() {
System.out.println("ContainerManagedProcessEngineProvider: BpmPlatform=" + ((URLClassLoader)BpmPlatform.class.getClassLoader()).getURLs());
pi = BpmPlatform.getDefaultProcessEngine();
if(pi == null) {
pi = ProcessEngines.getDefaultProcessEngine(false);
}
System.out.println("ContainerManagedProcessEngineProvider: Process Engine Name = " + pi);
}
public ProcessEngine getProcessEngine() {
return pi;
}
In a shared engine setup, the camunda-engine artifact must be loaded by a shared classloader available to all applications using the engine. It should not be part of the application. For example, on Tomcat this is achieved by putting camunda-engine.jar into the global lib folder and setting the Maven dependency to scope provided in all applications. Which container are you testing this in?
Hi Thorben,
Yes, I thought about that. Thanks for actually pointing me into this direction.
Currently I am using Tomcat, but I am not bound to this specific Servlet Container. Although lets have it run for Tomcat for now.
At the end of the day GraphQL should be available for alle Camunda BPM users
I agree. Just make sure to set the dependency to provided. The rest is application-server-specific configuration that is independent of the type of application. Users perform that for process applications anyway and it should be the same for the extension then.
Explanation:
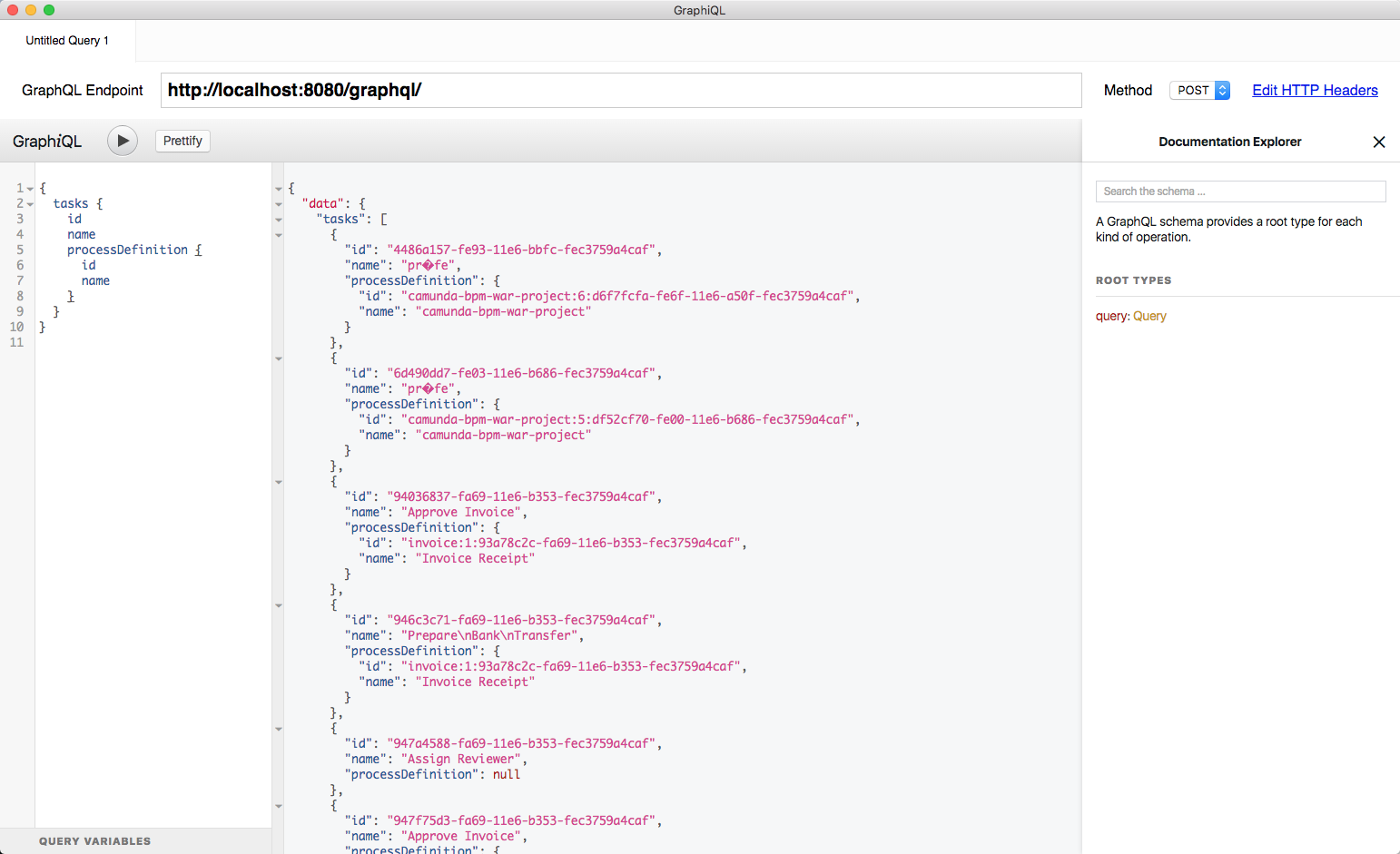
This query gives you all tasks. For each task it fetches the id, name and processDefinition. For each processDefinition, if available, the id and the name is fetched
Which fields exist on a task (=type TaskEntity)?
See the “automatic documentation” on the right side:
The idea is, that GraphiQL will be part of the Camunda extension making it super easy to fetch and mutate data using GraphQL on Camunda. Currently I am running it standalone next to the server, so I had an extra installation here.
Under the hood we use the Camunda Java API as documented and a GraphQL Schema / Type System to define what query and mutations are possible. This Schema we are going to extend now step by step along with the development of the resolvers.
Current Lines Of Code so far: 209 (in 4 Java Classes + 2 GraphQL Schema files)
Next steps:
Figure out which GraphQL types (based on Camunda Java API classes) should be implemented next.
Possibles candidate are:
ExecutionEntity (aka ProcessInstances)
Cases
DMN
User, Groups
Switch to public GitHub repo
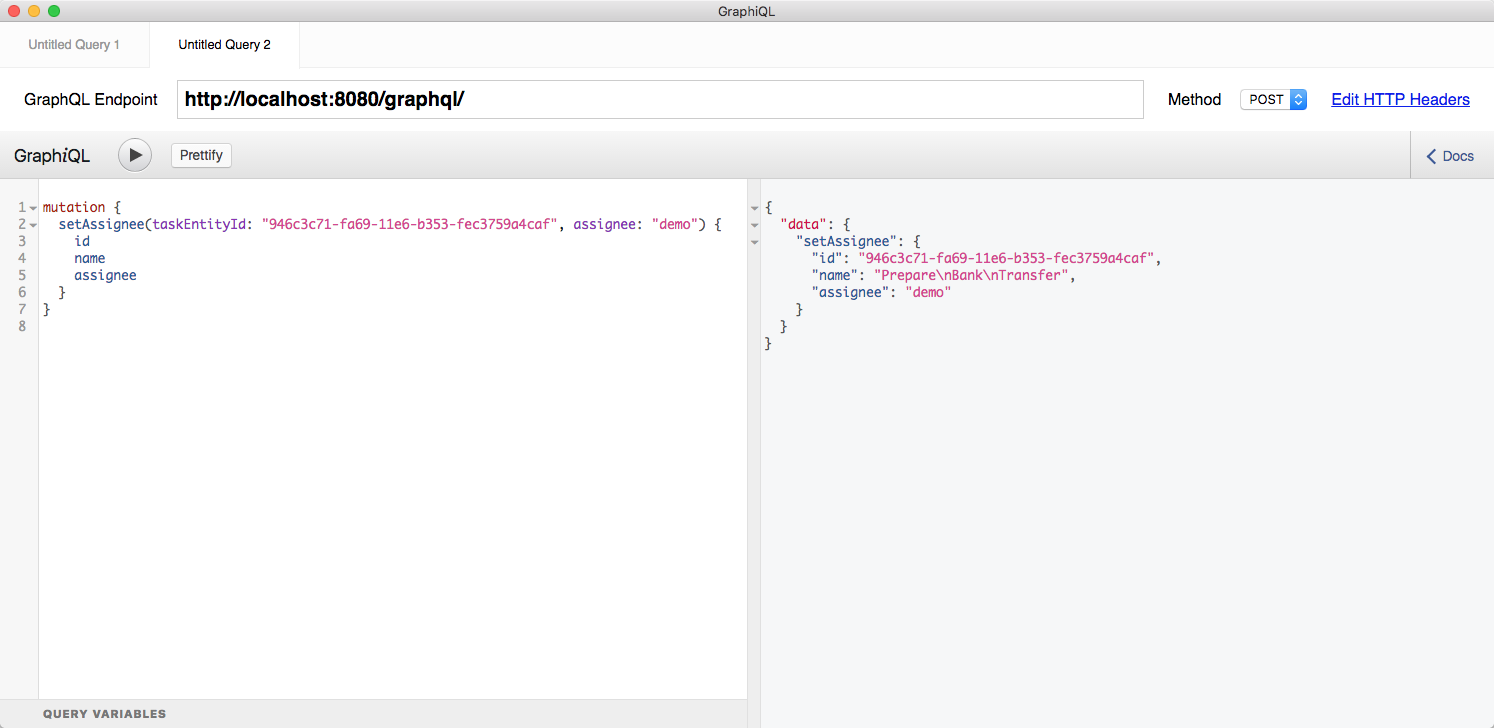
Implement mutations (again, based on what its possible with the Camunda Java API, “clean and green”)
Can’t wait for that :). We can also consider moving it directly to the Camunda github organization, just as you like.
I’d also propose to get a first alpha release out soon and publish a blog post to get attention and feedback by other users. The feature set could be limited but enough to showcase the idea (e.g. something that I could use to build a basic task list: querying tasks by some criteria and mutations like task completion).
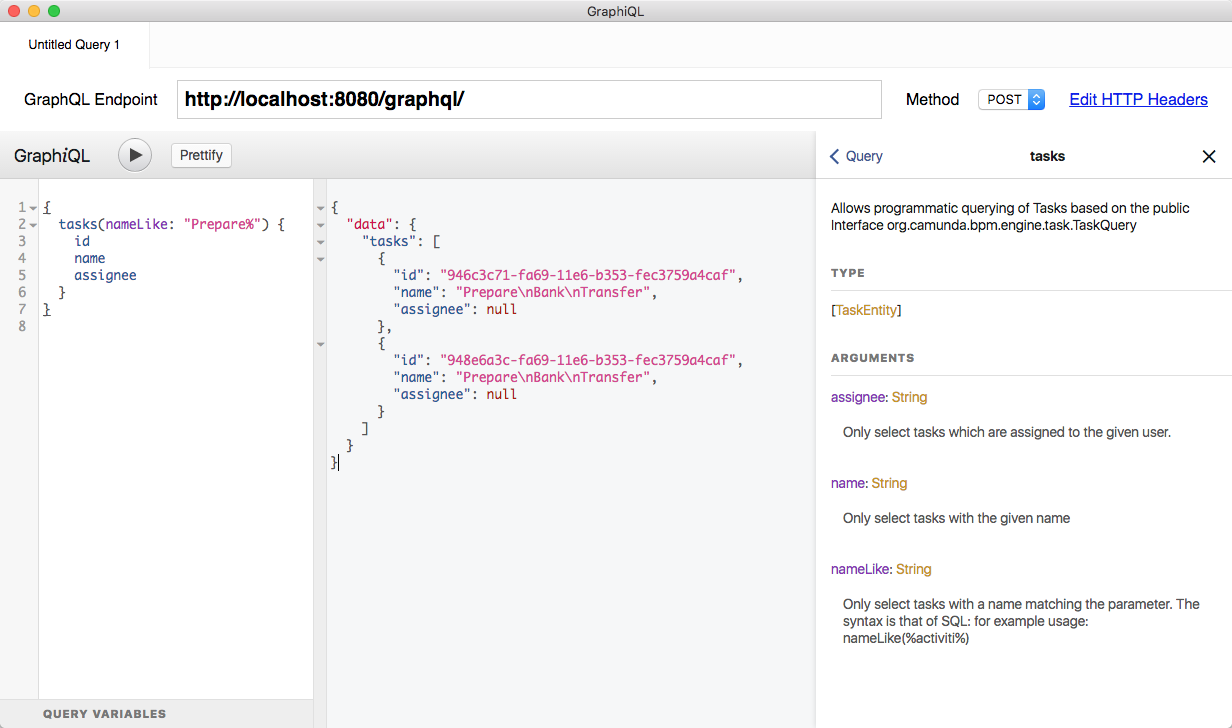
Added task filtering for name, nameLike and assignee - according to Java interface TaskQuery - just as an example how to use arguments in queries. Should be totally intuitive on how to use it…
Also added some GraphQL Schema documentation annotations, see the right side:

 . Repository-wise, I would we move this into the Camunda organization once we have a simple proof of concept that validates the idea.
. Repository-wise, I would we move this into the Camunda organization once we have a simple proof of concept that validates the idea.