Hello everyone,
I’m using a Self-Managed Camunda 8 instance based on Camunda Compose.
I’m testing a simple model that sends an Email using the Email Connector to send an Email.
The model was executing fine until was reaching the part to Send the email, then it was stuck there doing nothing until I eventually cancelled the Process.
The first tries I thought that was something wrong with my workflow and checked all the parameters and configurations, but then I checked the compose status and I noticed that the “connectors” service was down, I made it restart and when I tried to execute the model again it worked!
So I came here to ask:
- Why the component didn’t throw an error or indicated a problem and just remained stuck at that task?
- There’s a way to have better control on it? Like setting a timeout or changing something in the configuration?
Thanks.
Hi @a.vicidomini, welcome to the forums! This is expected behavior. Connectors can be thought of as fancy job workers (which, really, is what they are). When the engine encounters a connector or service task, it publishes the job to a queue to be picked up by a job worker or the connector runtime, and waits for the job to be picked up.
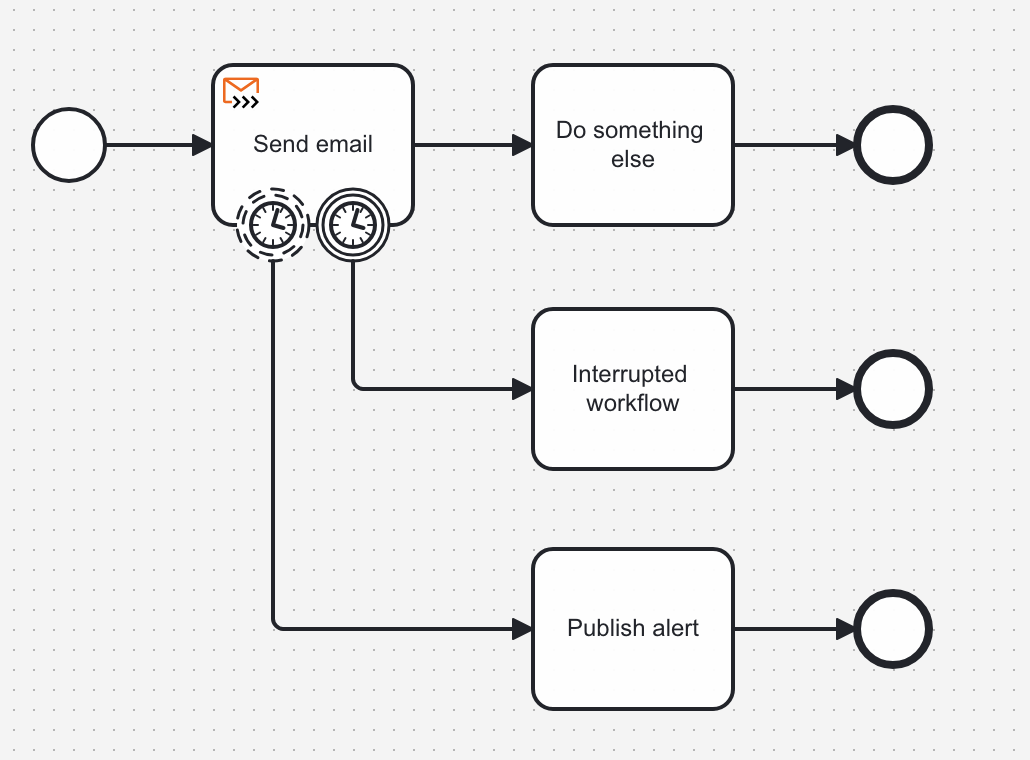
As you noticed, there is no timeout by default. There are two reasons for this. One reason is due to Camunda’s event driven and asynchronous architecture. But the primary reason is that it’s a better practice to explicitly model for that condition. You can use timer boundary events to handle this:
In this example, I set a non-interrupting boundary event and would set a shorter interval on it - perhaps 15 minutes - to alert somewhere that there’s a strange delay with sending an email, it shouldn’t take 15 minutes! And then an interrupting timer event that interrupts the entire workflow if it takes far too long.
This gives you complete control over how your process handles these conditions, and because it is explicitly modeled and not buried in implementation details, it’s easy to understand what the expectations are for each step.
At a production level, it is also important to monitor the services and ensure they are running. Ideally your infrastructure would alert you that the connectors runtime isn’t up or healthy so you can take action ASAP.
Hi Nathan,
Thank you for the reply and for the insight! I really appreciate it.
I admit it bothers me that Camunda leaves a task suspended like that, especially if a job is published and never picked up from no one, I expected an internal counter measure for common (at least in my view) cases like this.
I will follow your recommendations, just another question:
- If I apply a timeout as you suggested, and it goes off (5 minutes passed) what happens to the published job? It remains there indefinitely? Or is unpublished when the process stop?
Hi @a.vicidomini ,
The behavior of the process depends on the type of timer boundary event configured.
If it’s a non-interrupting timer boundary event, the original task continues to run while a separate path is triggered when the timer fires. This allows both flows to proceed in parallel.
However, if it’s an interrupting timer boundary event, the running task is immediately cancelled when the timer triggers, and the process flow follows the boundary event path.
@a.vicidomini - another option in a Self-Managed deployment: you can customize some timeouts for individual connectors - see the docs here.
The architecture of Camunda means that it’s unlikely that jobs wouldn’t be picked up without other alerts occurring. Traditional job workers support timeouts by default, and Self-Managed exposes a set of metrics you can monitor to see how many jobs are pending (which includes connector jobs). Connectors rely on the runtime to coordinate them, so monitoring the runtime to ensure it’s running and healthy is important as well. Combined with explicitly modeling your SLA conditions and we’ve found this to be a very robust solution with extremely little volatility.