Hello Guys,
We are currently using Zeebe 8.3.3 on self managed mode. Usually our workflows are small and expected to be finished within a second.
We have all our workers in python and are using pyzeebe library. We encounterd huge delays in workflow completion. Upon digging deep we found the jobs were not getting picked up/activated by the workers.
We played around with task timeout and pooling timeout and managed to reduce the activation delay to a certain extent. We currenlty use task timeout of 300ms and pooling time of 1sec.
We were looking out to solve this and stumbled across https://camunda.com/blog/2024/03/reducing-job-activation-delay-zeebe/ this article. And we have started to embark on the journey to use grpc server streaming rpc.
We decided to add the worker on Java as it seemd as native to Zeebe and could find sample code. Our client looks as below.
ZeebeClientBuilder zeebeClientBuilder = ZeebeClient.newClientBuilder();
zeebeClientBuilder.gatewayAddress(this.config.getZEEBE_BROKER_GATEWAY());
zeebeClientBuilder.numJobWorkerExecutionThreads(128);
zeebeClientBuilder.defaultJobWorkerStreamEnabled(Boolean.TRUE);
zeebeClientBuilder.usePlaintext();
return zeebeClientBuilder.build();
and we are using java workers as below
@ZeebeWorker(type = "http_worker_save_ncfm_to_wds", autoComplete = true, timeout = ncfmWorkerTimeout)
We added few unique workers in Java with above setting. Upon deploying the java service we noticed
- workers in java that were stream enabled were not receiving any jobs
- we restarted zeebe pod and things started to work
We noticed an intermittent behaviour of workers suddenly stopped receiving jobs altogether.
We want to solve this activation problem for good. Can you guys please help us here with anything we might be missing.
How to differentiate between a pooling worker and a stream worker in production monitoring?
Do you think having workers in Java would be beneficial?
What are best practices around zeebeClient or job worker configuration?
@nathan.loding @Niall can you please have a look at this. We have been struggling with this for quit sometime now. Any views would help us immensly.
Hi @STopcharla, welcome to the forum!
In the future, please refrain from tagging users who have not participated in the thread. This is a community forum, not an official support channel. If you need priority support, I’d recommend reaching out to our enterprise support team. Thanks!
hey @miamoore
Sure, noted
@STopcharla - a couple notes to start:
- the pyzeebe library is maintained by the community, and looking at the repository, support for >8.0 is still in beta testing (4.0.0-rc4 as of writing this comment). Any testing with pyzeebe against 8.3 needs to be using 4.0.0 and feedback should be given to the maintainer in the GitHub issues
- task timeouts are the amount of time an active job can run before Zeebe reassigns the job to another worker; it does not affect activation. Perhaps you are looking to use the request timeout for long polling?
You mentioned that restarting Zeebe allowed the jobs to be picked up; this, to me, indicates the issue might be on the Zeebe end. How many jobs are in your process, and how many PIs are you running (per minute or hour)? How many Zeebe brokers do you have configured, and what resources have you given them? Can you share your Zeebe configuration?
hello @nathan.loding
Sorry for late reply missed this notification.
About pyzeebe library, we are planning to move all workers to java. Using the native java client.
We need some help with stream processing for Java workers, which we are not able to get it right.
Yeah we adjusted request timeout to be 1s now, do you recommend us to reduce this further?
Resource configuration:
Development environment:
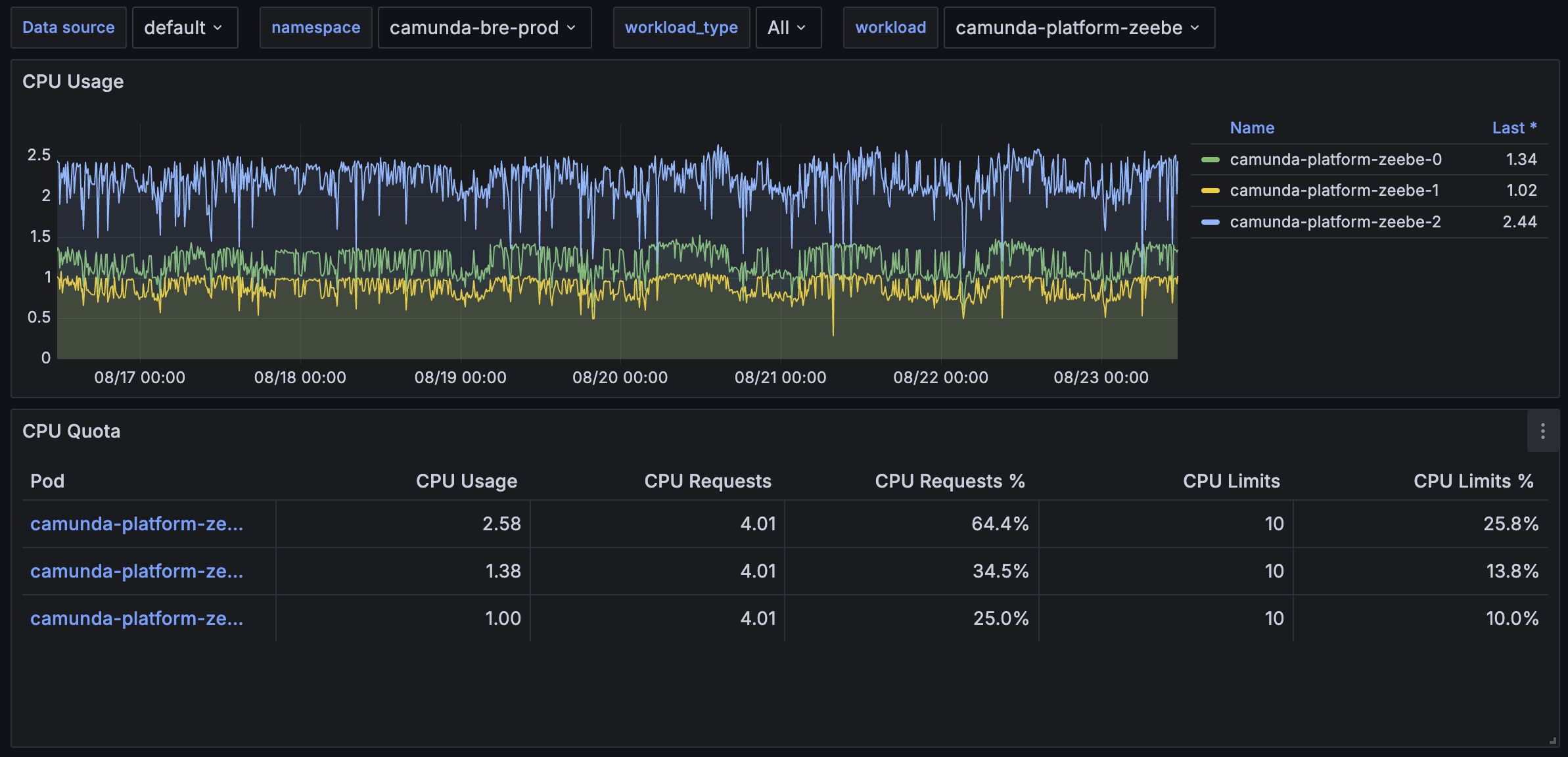
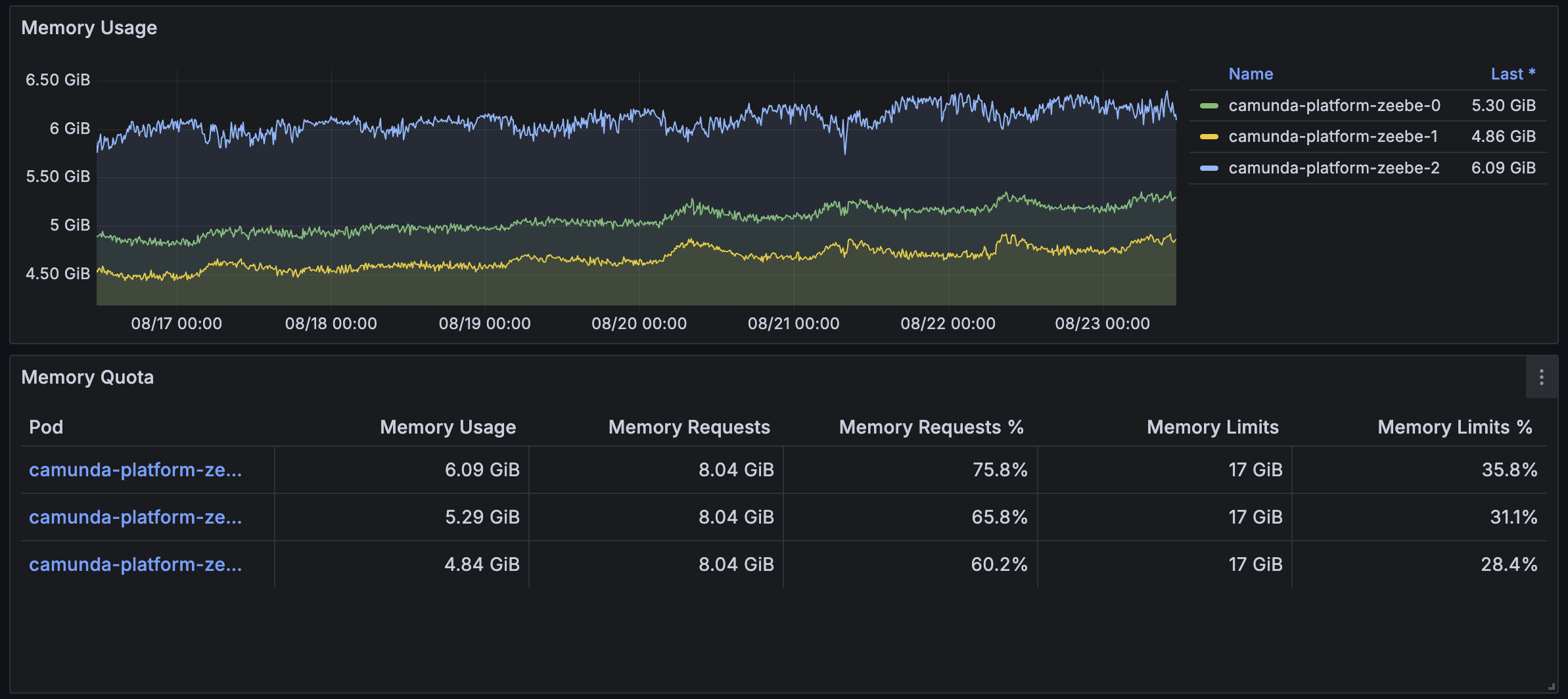
We have 3 nodes with 3 partitions with very less traffic on day to day around 100-200 on the whole day but we do run our load testing of creating a couple of 100 workflows in a minute once in a while, we had to restart zeebe pods in development environment, below is the resource configuration
resources:
requests:
cpu: 800m
memory: 2048Mi
limits:
cpu: 1024m
memory: 4192Mi
PROD Env:
3 nodes with 9 partitions, we have comparitively less traffic as we get around 10000 workflow requests during the working hours. Each workflow has around 7-10 workers. below is the resource configuration
resources:
requests:
cpu: 800m
memory: 2048Mi
limits:
cpu: 1024m
memory: 4192Mi
Worker configuration:
request timeout: 1s
task timeout: 500ms
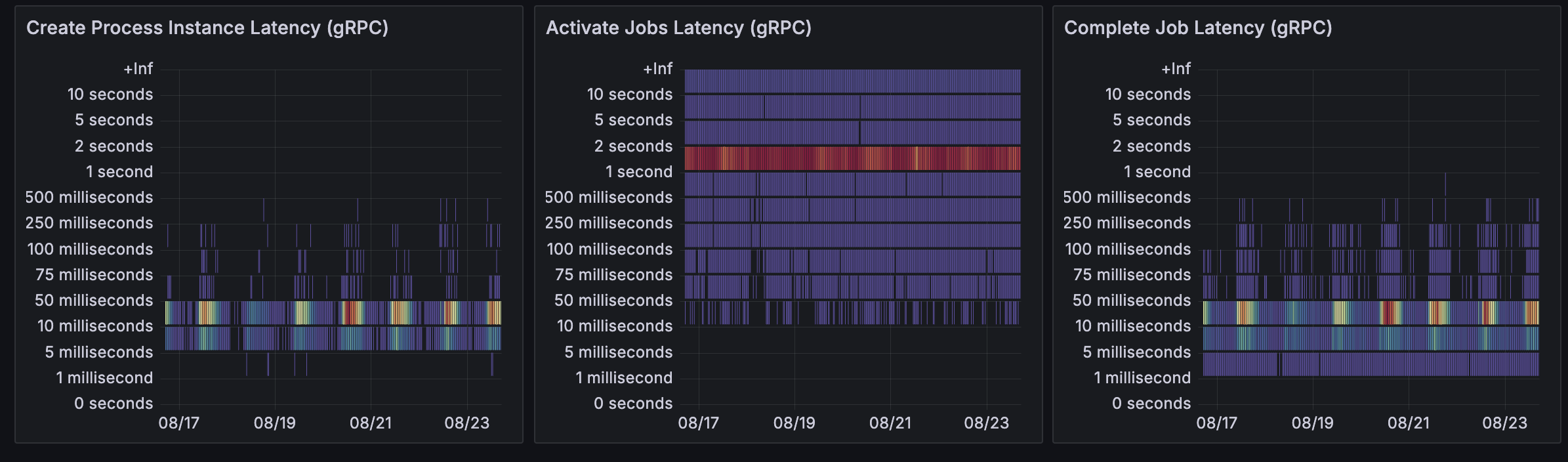
Zeebe pod cpu and memory usage:
@STopcharla - nothing stands out to me in the graphs except for the red line in the “Active Jobs Latency”. It looks to me like your timeout configuration is causing issues.
Again, the task timeout cancels the job. By setting the task timeout to 500ms you are saying “If this job hasn’t activated, run, and completed, in 500ms, cancel it and try again”. I suspect you may be accidentally creating a backlog of jobs that need to re-queue and try again.
The first thing I would do is increase those timeout values. Then, I would double check to make sure I’ve configured the Java client for job streaming properly (I’m sure you have, but always worth double checking the documentation when troubleshooting, in my opinion). Then try again.
If you continue to have issues, I would try a few additional things:
@nathan.loding thanks for the response, we will enable the metrics and update back our findings.
@nathan.loding our workflow completion SLA is under a second, coz the amount of functionality these workers are doing is minimal. Our p99 is around 10-15 sec, p95 - 5sec, p90 - 2sec. Hence we had the task timeout configured that way.
On another note, last night we deployed java workers with stream disabled (previously we had workers only in python) i.e. same type of worker in python as well as in java. There are 9 pods of python service and 2 pods of java service. We could see activation delay was through the roof, all of the workflows were taking around 20sec to complete.
As a break fix we removed java workers. What do you think is happening here? What would be a better setup? having only java workers?
@STopcharla - I understand you’re trying to achieve a certain SLA, but you’re having issues, so troubleshooting is necessary. Also as noted, the timeout cancels the job which causes it to requeue, and you might perhaps be creating additional pressure and a longer queue because of the extremely short timeout.
- Did you try making the task timeout longer? What was the result?
- Did you enable the metrics? What do they show?
- Did you review the troubleshooting steps, and what does the job actuator endpoint show when you’re experiencing delays?
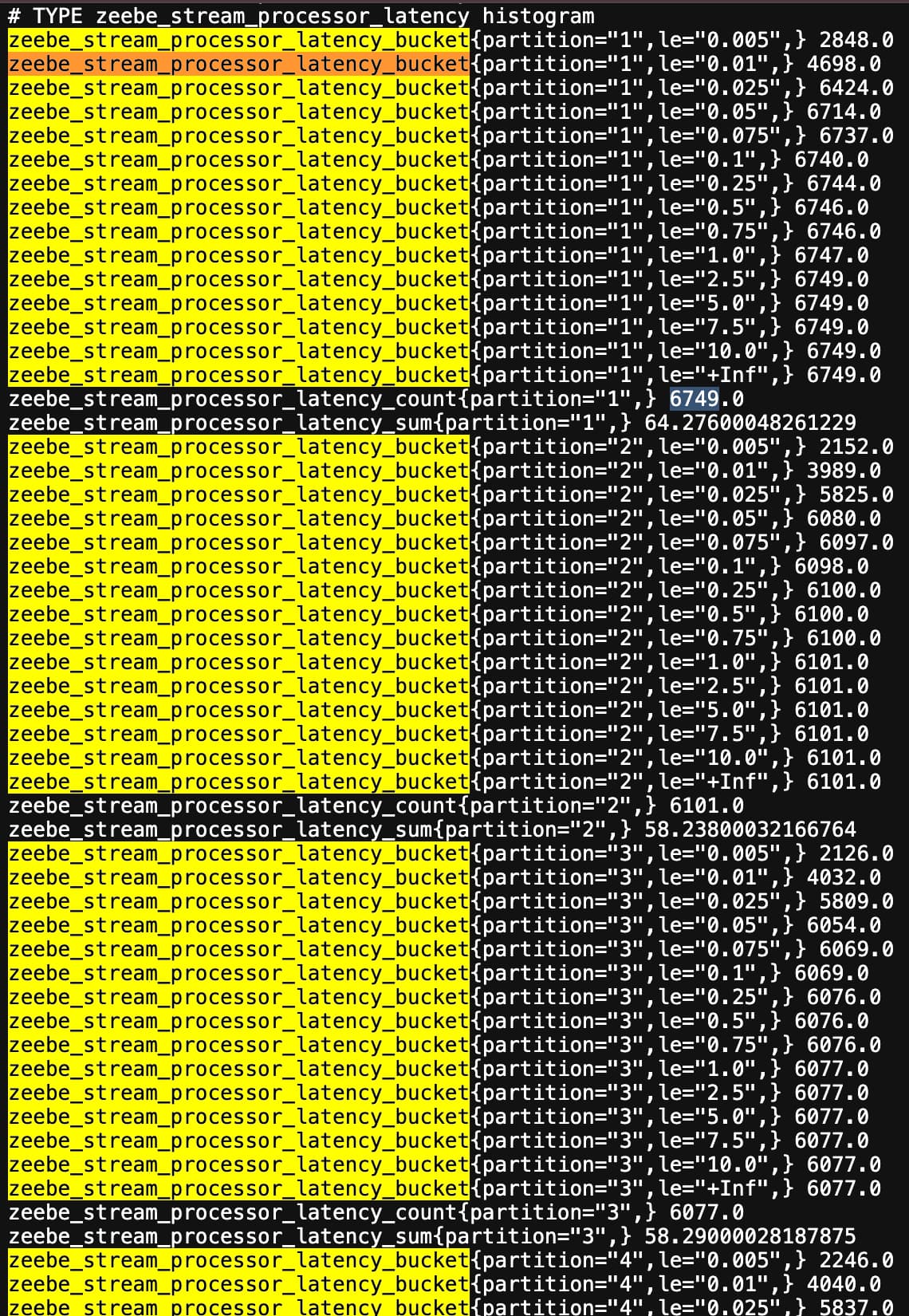
hey @nathan.loding,
here is the stream latency metrics
We are getting below error in logs that grpc connection is reset.
"POST /gateway_protocol.Gateway/ActivateJobs HTTP/2" 200 UF upstream_reset_before_response_started{remote_connection_failure,delayed_connect_error:111} - "delayed_connect_error:111" 60 0 0 - "-" "zeebe-client-java/8.4.0
grpc
-java-netty/1.60.0" "0ac2dd91-a8ac-9321-9036-184c159e40c2" "camunda-platform-zeebe-gateway.camunda-bre.svc.cluster.local:26500" "100.64.181.9:26500" inbound|26500|| - 100.64.181.9:26500 100.64.174.18:50702 outbound.26500._.camunda-platform-zeebe-gateway.camunda-bre.svc.cluster.local default
On client code:
"POST /gateway_protocol.Gateway/StreamActivatedJobs HTTP/2" 0 DPE codec_error:The_user_callback_function_failed - "-" 69 0 325584 - "-" "zeebe-client-java/8.4.0
grpc
-java-netty/1.60.0" "a83ecfc8-c73d-966e-8867-4df478d8dab7" "camunda-platform-zeebe-gateway.camunda-bre.svc.cluster.local:26500" "100.64.164.132:26500" outbound|26500||camunda-platform-zeebe-gateway.camunda-bre.svc.cluster.local 100.64.129.152:60594 172.20.147.14:26500 100.64.129.152:49072 - default"
job streams actuator is showing the connected consumers, we increased the task timeout that only made our workflows go longer on a overall level.
here are few more logs we found.
Will provide links to the logs while the process is stuck and while it started to run
If you have the chance to upgrade, job streaming will help in this situation. It is available from 8.4 - Job streaming | Camunda 8 Docs
@jothi-camunda @nathan.loding finally found the issue why the stream was ending abruptly. Here is how we found it out, looks like this was already identified.
We enabled debug logs for spring-zeebe dependency. Post enabling the logs we ran the application and found error logs : INTERNAL: Encountered end-of-stream mid-frame. Further checking this error over internet, we found that it is happening due to grpc version. Ref : On Spring 3.2.7 and above it throws `INTERNAL: Encountered end-of-stream mid-frame` · Issue #862 · camunda-community-hub/spring-zeebe · GitHub
We are using spring 3.3.1 and are not using grpc in our application, so we explicitly added
"io.grpc:grpc-bom:1.66.0"
dependency in our gradle file. Post enabling this dependency, streams are working as expected.