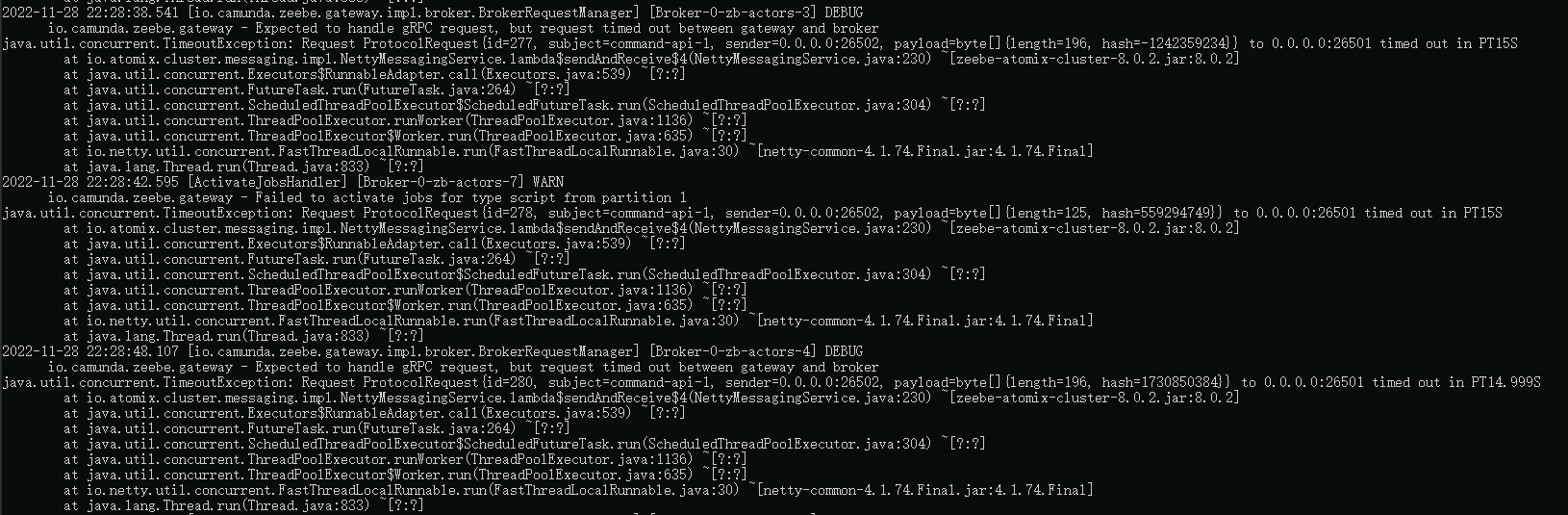
Sometimes we are facing with getting the timeout between Zeebe gateway and broker with no obvious reason for it.
The configuration of Zeebe is all-in-one, so the gateway and other Zeebe components are running on the same container in k8s cluster. The lion part of requests works fine, but sometimes ( ~ once a day ) we get the error:
[io.camunda.zeebe.gateway.impl.broker.BrokerRequestManager] [Broker-0-zb-actors-1] DEBUG io.camunda.zeebe.gateway - Expected to handle gRPC request, but request timed out between gateway and broker java.util.concurrent.TimeoutException: Request ProtocolRequest{id=1896336, subject=command-api-1, sender=0.0.0.0:26502, payload=byte[]{length=673, hash=-148275053}} to 0.0.0.0:26501 timed out in PT1M at io.atomix.cluster.messaging.impl.NettyMessagingService.lambda$sendAndReceive$4(NettyMessagingService.java:218) ~[zeebe-atomix-cluster-1.2.4.jar:1.2.4] at java.util.concurrent.FutureTask.run(Unknown Source) ~[?:?] at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(Unknown Source) ~[?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source) ~[?:?] at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source) ~[?:?] at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) ~[netty-common-4.1.68.Final.jar:4.1.68.Final] at java.lang.Thread.run(Unknown Source) ~[?:?]
There is no pressure on the CPU or other hardware resources.
The configuration of zeebe:
zeebe:
broker:
gateway:
enable: true
network:
port: 26500
security:
enabled: false
network:
host: 0.0.0.0
data:
directories: [ data ]
logSegmentSize: 512MB
snapshotPeriod: 15m
cluster:
clusterSize: 1
replicationFactor: 1
partitionsCount: 1
threads:
cpuThreadCount: 2
ioThreadCount: 2
exporters:
hazelcast:
className: io.zeebe.hazelcast.exporter.HazelcastExporter
jarPath: /tmp/zeebe-hazelcast-exporter-1.1.0-jar-with-dependencies.jar
elasticsearch:
className: io.camunda.zeebe.exporter.ElasticsearchExporter
args:
url: http://es-zeebe-dev.somedomain.local:9200
bulk:
delay: 5
size: 1000
index:
prefix: qa-zeebe-record
createTemplate: true
command: true
event: true
rejection: true
deployment: true
error: true
incident: true
job: true
jobBatch: true
message: true
messageSubscription: true
variable: true
variableDocument: true
workflowInstance: true
workflowInstanceCreation: true
workflowInstanceSubscription: true