Hi everyone,
I was wondering if I could have some help trying to improve the external task consumption performance in our project. We are having what I suppose to be some concurrency issues that are affecting the performance of the external tasks consumption when we scale up our camunda pod number in our cluster. I’m gonna try to make some schemes to contextualize.
First of all, in our architecture we use camunda as a remote application (Camunda 7.15.1 but used 7.18 on these tests), not embedded, and communicate with camunda exclusively via the camunda rest api. We have a service which has the single responsibility to provide that communication with camunda (Bpm Gateway Service).
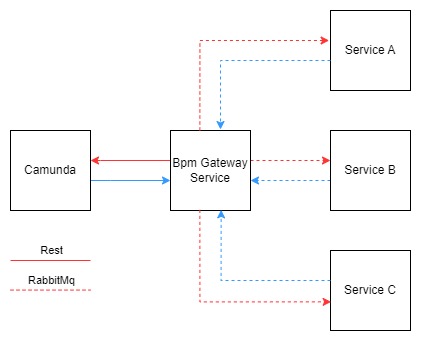
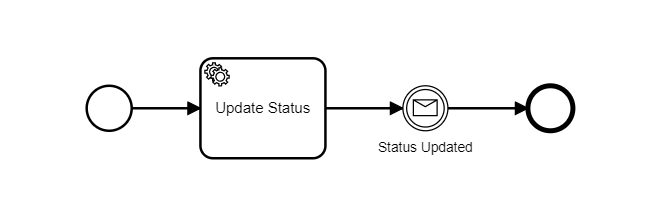
We handle our service tasks asynchronously, modeling the bpm processes as the following example:
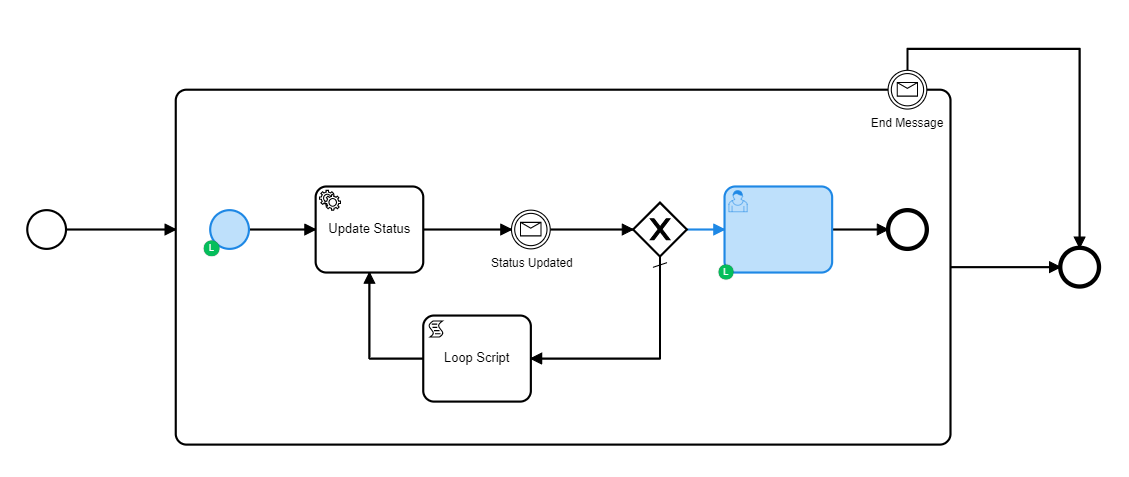
We have simplified the way our Bpm Gateway Service handles the external tasks right now to try to avoid concurrency caused by our side of the equation and being able to test the case on the camunda side. So in this test version we have the following behaviour:
Only 1 Bpm Gateway Service pod is up and is requesting fetch and lock with a list of all topics of our application. We are using the following parameters: asyncTimeoutResponse: 30000 / lockDuration: 5000 / maxTasks: 10
Bpm Gateway Service is running the following infinite loop on its start:
while(true) {
- Bpm Gateway Service executes fetchAndLock request to Camunda through rest api
- Bpm Gateway Service completes all external tasks retrieved from Camunda through rest api
- The bpm process moves to the following correlate message activity waiting for the response the task was handle to move on.
- Bpm Gateway Service produces a message to the Service responsible to handle the external task (e.g. Service A)
}
Asynchronously:
5. Service A consumes the rabbitMq message and does its job
6. Service A sends a rabbitMq message to Bpm Gateway Service after the handling
7. Bpm Gateway Service sends a correlate message request to Camunda through rest api
8. The process moves on
We tested the following bpm process running in a loop and made some queries to Camunda db to obtain some metrics regarding the time external tasks take to be consumed after its creation.
These are the results:
- 1 Camunda pod up:
The following query result shows the minimum, maximum and average external task consumption time (among the 200 ET looped):

No external task took more than a second to be consumed
- 2 Camunda pods up with shared db:
The following query result shows the minimum, maximum and average external task consumption time (among the 200 ET looped):

10 of the 200 external tasks took many time to be consumed, a value close to the asyncTimeoutResponse time used. Next table shows the 10 results with consumption time over 1 second:
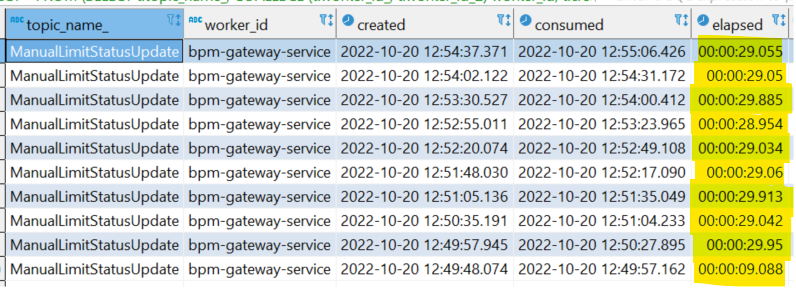
Do you have any ideas how to mitigate or minimize this delay?
Thank you