camunda/zeebe:8.2.7
spring-zeebe-starter:8.0.7
Zeebe Cluster information :
- 3 brokers
- Embedded Gateway in first broker
- one partition with replication factor of 3
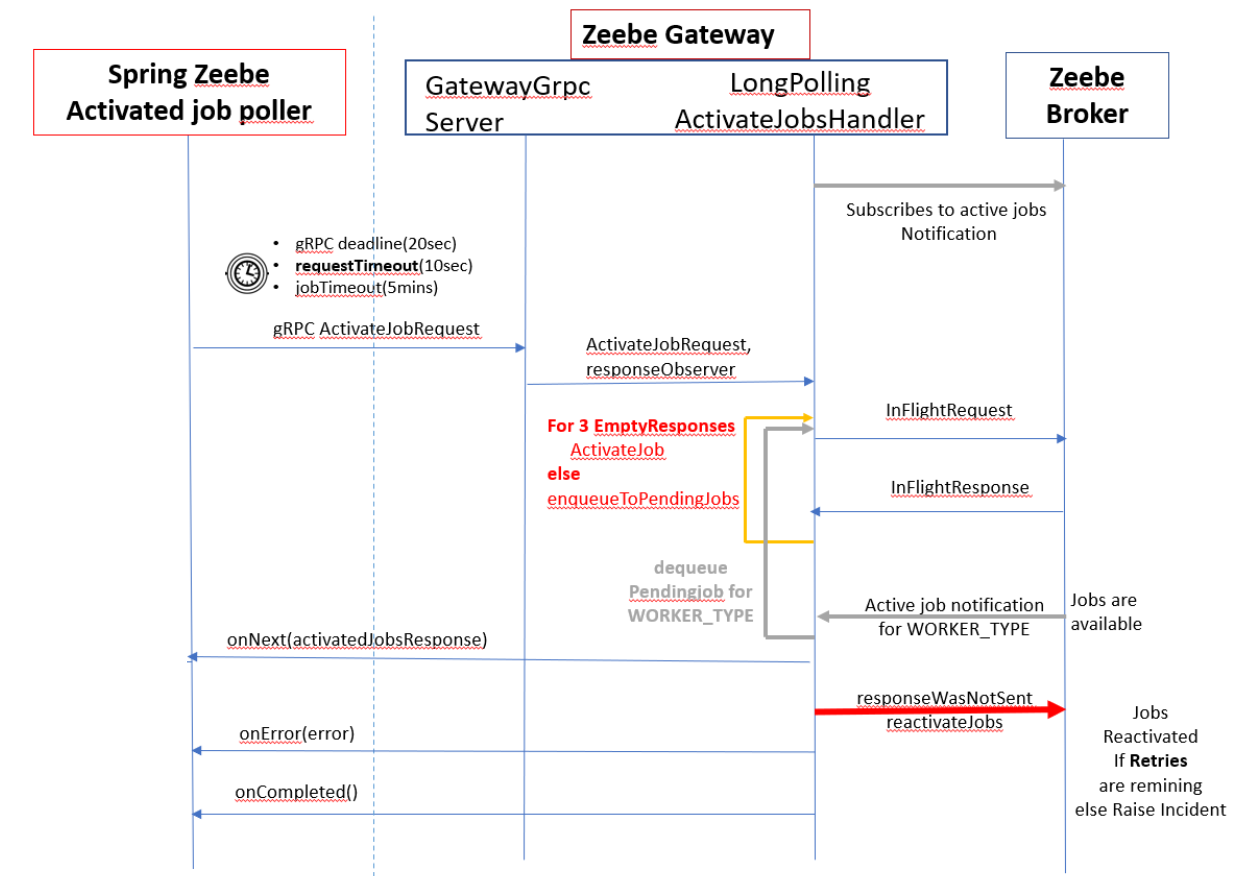
Gateway and Broker report INCIDENT
During execution of the bpmn process, what i see is that Zeebe creates an INCIDENT that it Failed to send activated jobs to client
DEBUG io.camunda.zeebe.gateway - Failed to send 1 activated jobs for type TEST_TASK (with job keys: [2251799813710278]) to client, because: Failed to send activated jobs to client
TRACE io.atomix.raft.roles.LeaderRole - {EventType = INCIDENT, intent=CREATED}, key=2251799813686910, sourceIndex=-1, unifiedRecordValue={"errorType":"**JOB_NO_RETRIES**","errorMessage":"**Failed to send activated jobs to client**","bpmnProcessId":"test_model","processDefinitionKey":2251799813685456,"processInstanceKey":2251799813686889,"elementId":"TEST_TASK","elementInstanceKey":2251799813686906,"jobKey":2251799813686908,"variableScopeKey":2251799813686906}
Upon investigation of the zeebe logs: what we see is that
when job is activated by broker and sent back to gateway
Gateway tries to give back this job to zeebe client but then logs the failure “Failed to send activated jobs to client”
When Gateway tries to send back the job, its the time when old poll request is expired with timeout of 10 secs and the next poll request comes in.
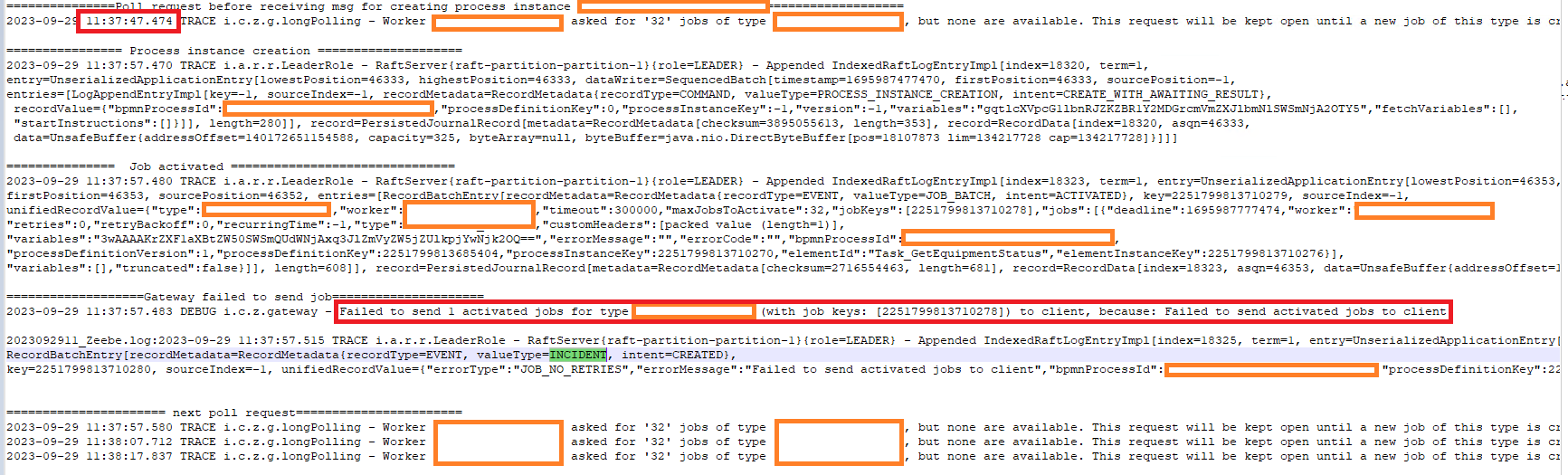
We want know if it is the behavior of the zeebe or its a bug? : Gateway tries to send activated job to client within a transition time period between expired poll request and new poll request?