Hi everyone ![]()
I’ve run into a distributed-transaction-challenge in our system that I suspect some of you might have encountered as well in the context of zeebe. I’m reaching out to see if anyone has insights, best practices, or alternative approaches for solving this.
The Challenge
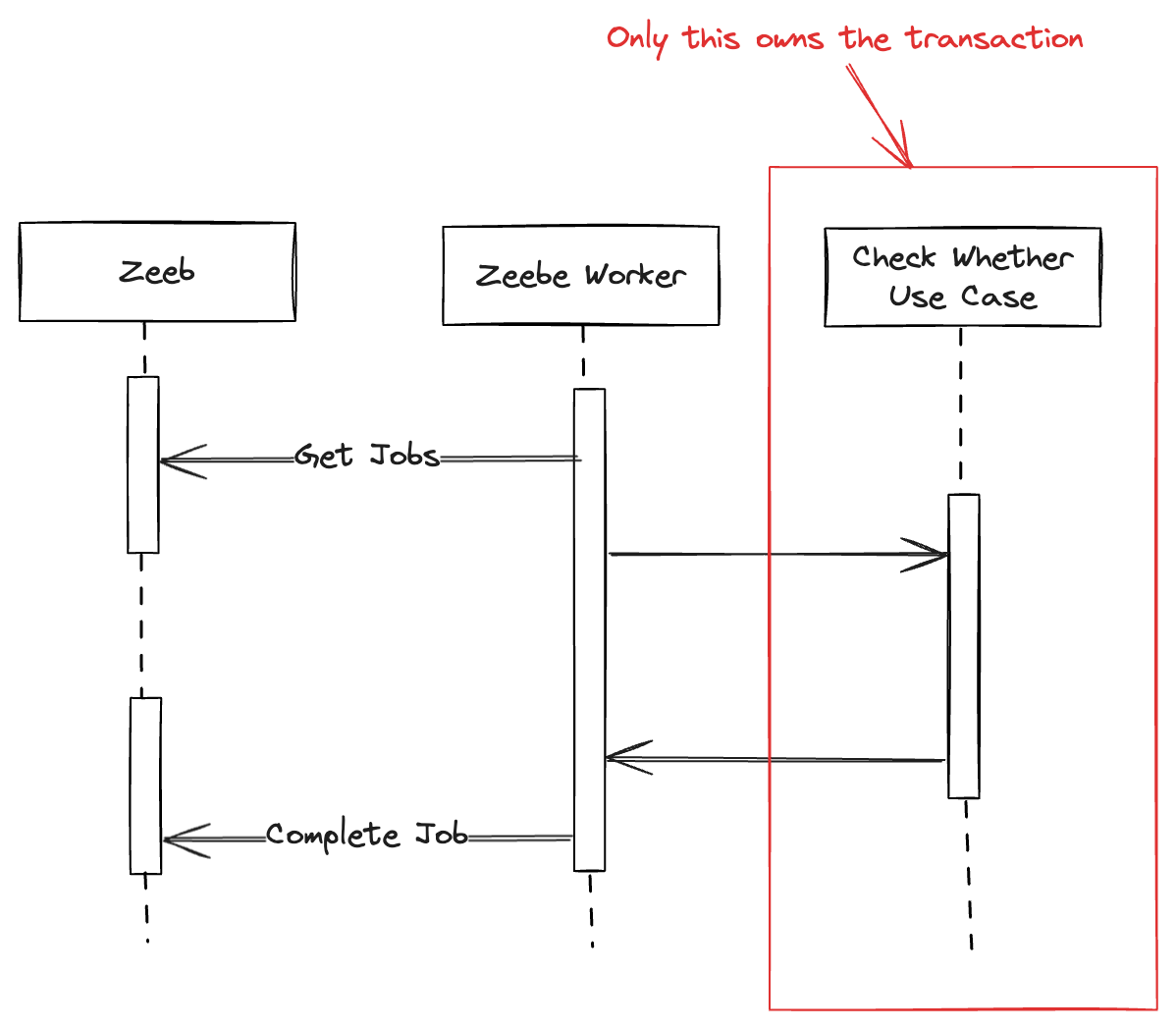
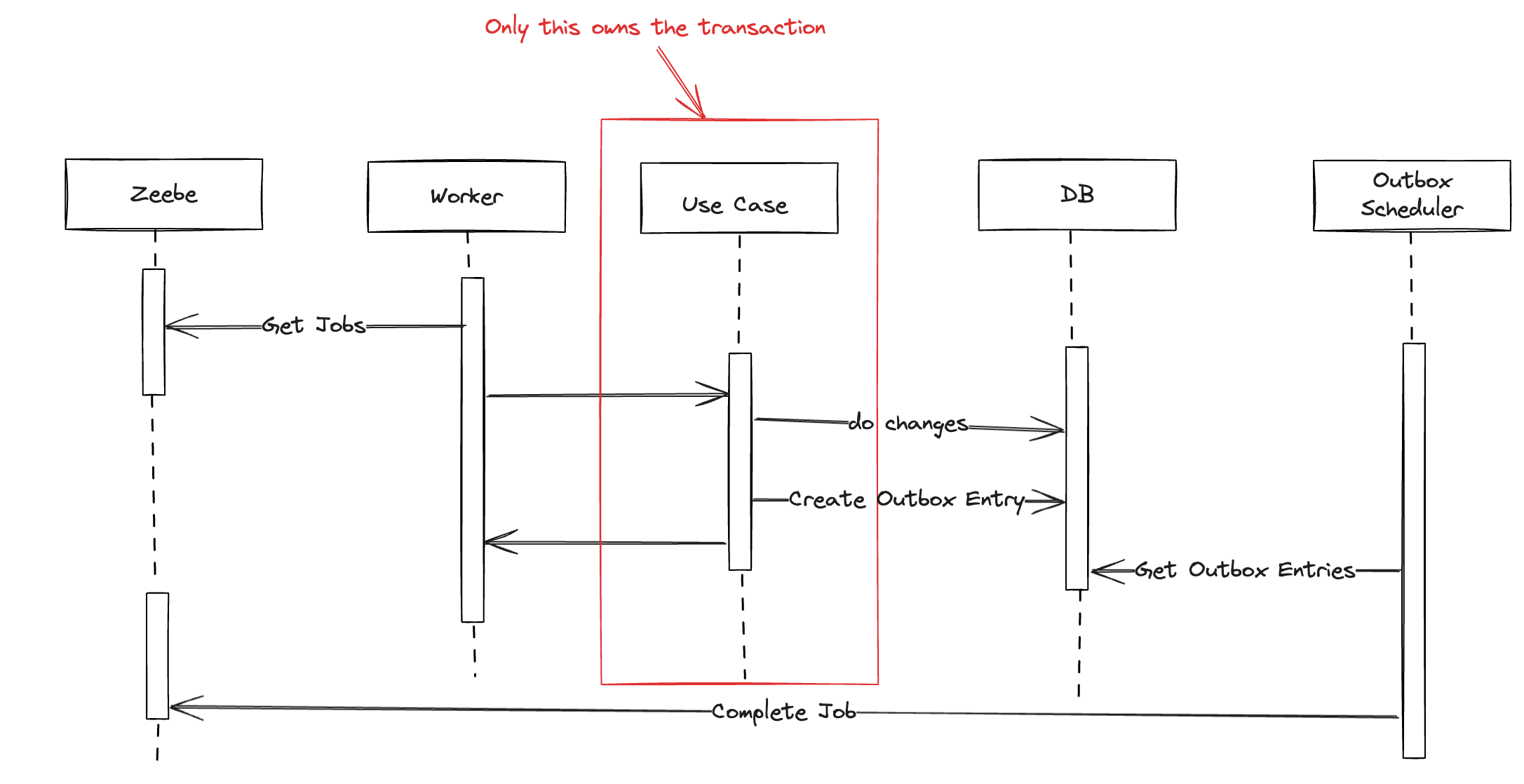
We’re using Zeebe to orchestrate processes across our microservices. During testing, I noticed that when a new process is started, there’s a chance that the first task gets executed by Zeebe before the originating transaction has fully committed. This issue applies not only to the process start but also to all cases in which a message is sent to Zeebe.
This can lead to inconsistencies: Zeebe starts the process and executes a task before the database changes are available, causing potential errors when a second worker tries to access uncommitted data.
To clarify, assume the following example, which is also visually represented in the accompanying image. Imagine we have a process that manages vacation requests. This process is deployed to and orchestrated by Zeebe. It includes a start event and an initial worker.
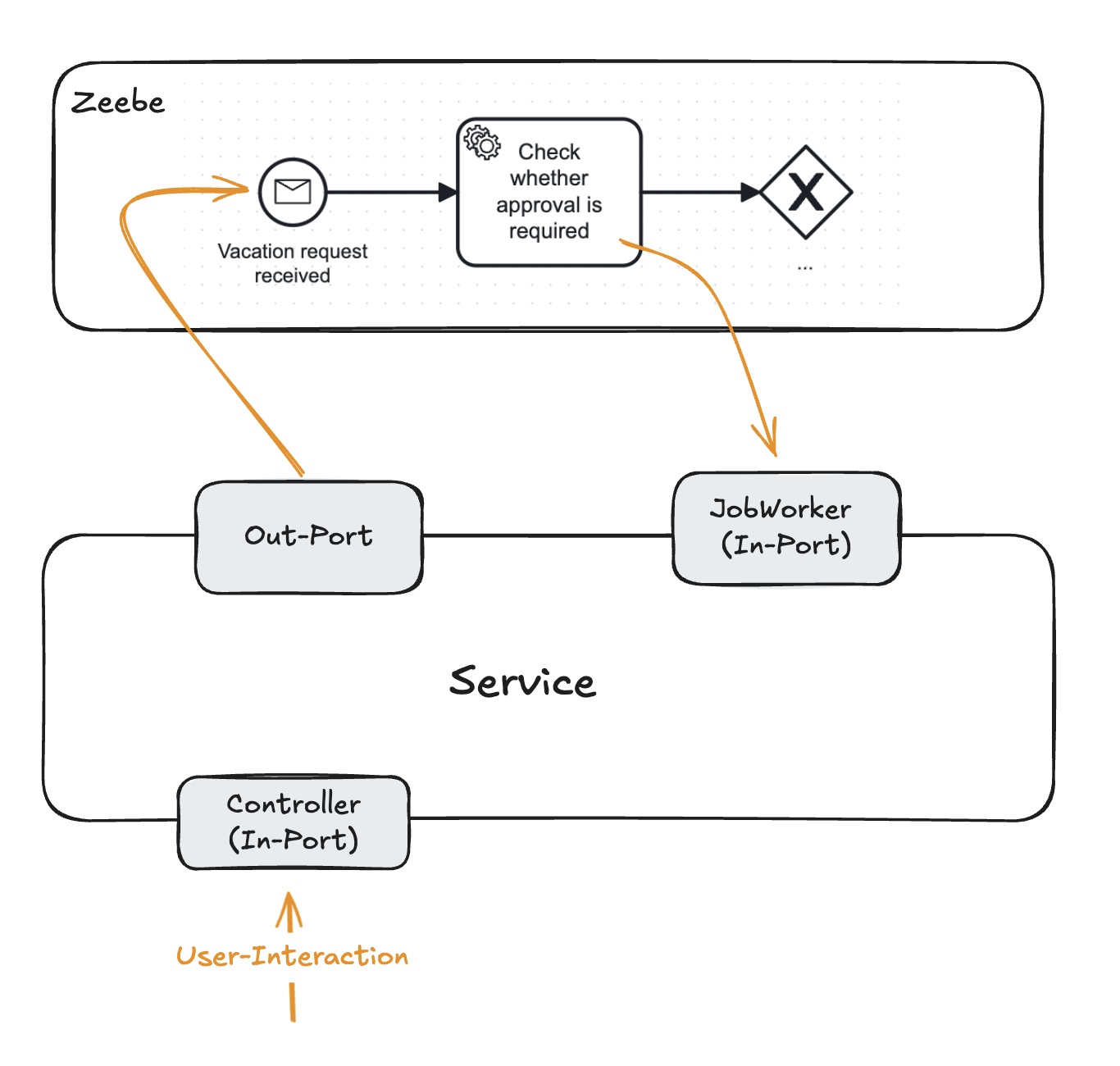
The process is triggered whenever a user submits a vacation request. This is implemented by a CreateVacationRequestService that saves the vacation request to the database and then calls Zeebe to start the process. The service looks something like this and is annotated with @Transactional :
@Transactional
class CreateVacationRequestService(
val repository: VacationRequestRepository,
val processPort: ProcessPort
) : CreateVacationRequestUseCase {
override fun createVacationRequest(command: CreateVacationRequestCommand) {
val request = VacationRequest(command)
repository.save(request)
processPort.vacationRequestCreated(request)
}
}
The issue arises because the transaction completes only after both the database save and the Zeebe call are done. This means Zeebe might start executing the process while the database commit is still pending, which can result in errors if other tasks need to access the newly created vacation request before it’s available. This issue becomes more likely if additional operations are executed after the process call, extending the transaction duration and increasing the likelihood of inconsistency.
Possible Solutions I’ve Considered
- Rely on Zeebe’s Retries: Ensure that the Zeebe start-process-call is always the last action in the service to minimize the risk. Then, I could ignore the issue and rely on Zeebe’s built-in retry mechanism. After a few retries, the transaction should be committed, allowing the task to execute successfully. However, with messages, for example, there could still be a risk of data records overwriting each other. Thus, i think this isn’t the best-idea
- Zeebe Call After the Transaction: Move the Zeebe API call outside the transactional scope, ensuring the process starts only after the database commit (same applies to messages). However, this approach introduces its own challenges—such as handling errors during the Zeebe call, which could lead to scenarios where a vacation request exists without an associated process instance.
Both options have their challenges, and I haven’t found much discussion about this issue yet. Before committing to one of these solutions, I wanted to ask the community:
- Is this a common problem others have faced?
- Are there any best practices or patterns for handling this kind of distributed transaction issue in Zeebe?
- Is there a better approach that I may have overlooked?
Looking Forward to Your Insights
I’d really appreciate any feedback, especially from those who have dealt with similar transactional issues in Zeebe. Perhaps there’s an established best practice I missed, or a simpler solution that makes more sense in this context.
Thanks a lot in advance for your help!
Cheers, Marco