Hi all,
I’m quite new to Camunda, been learning as I go, but came across something I couldn’t explain to myself from documentation, so hoping to get educated ![]()
We are using Camunda 7 as a standalone engine and employing the external task pattern.
Problem
We were seeing some OptimisticLockingExceptions in production. They were easy to fix with an async after once I found out how they occur and managed to reproduce them locally, but getting there took some time. I still don’t quite understand why they occur, though.
This is probably not the smallest possible example to reproduce the situation, but at least it does the trick, and it resembles our production process flow.
Reproduction
I have two separate processes, which signal each other:
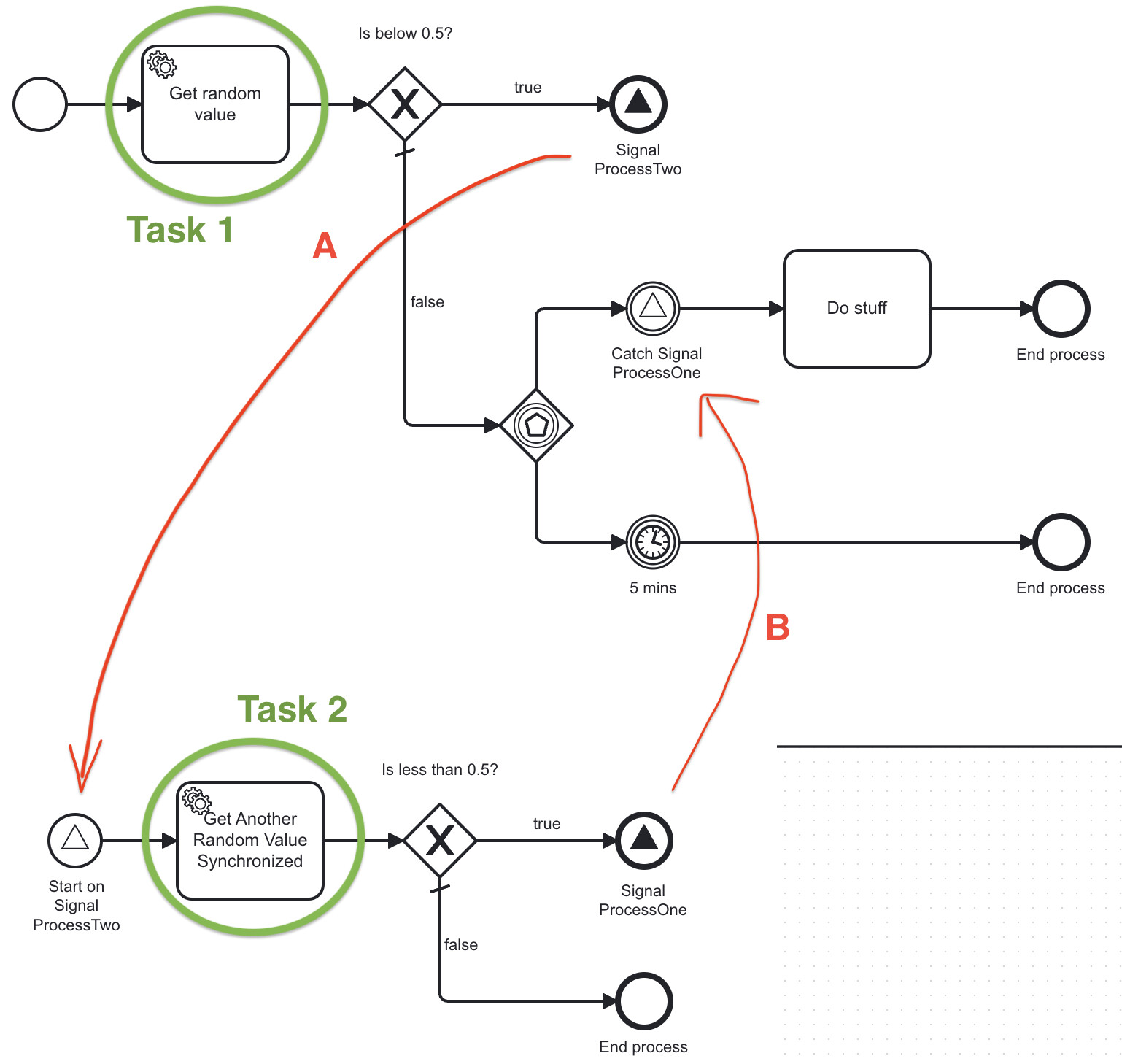
Process #1
- Task 1: Get a random number
- If number < 0.5, send signal A: Starts Process #2
- Else, proceed to wait for either:
- Signal B from Process #2
- 5 min timer
Process #2
- Task 2: Get a random number, but implemented so that the task waits a while for more invocations and completes them at the same time
- If number < 0.5, send signal B: Continue waiting process instances in #1
- Else, end process
EngineError
If I start a few Process #1’s, I’m getting an EngineError if:
- At least one process instance takes the
elsebranch and waits at the event based gateway - And at least two Process #2 instances complete Task 2 (at the same time) with a value such that signal B would be sent
All instances of Process #2 (beyond the first) trying to send signal B fail to complete Task 2 with this error:
EngineError: Response code 500 (Internal Server Error); Error: ENGINE-03005 Execution of 'DELETE EventSubscriptionEntity[(...)]' failed. Entity was updated by another transaction concurrently.; Type: OptimisticLockingException; Code: 1
Question: Why does this happen?
If I am understanding this correct, this behaviour is due to transaction boundaries: When Task 2 is completed, it actually commits Task 2 plus anything else up to the next transaction boundary. I guess the transaction boundary goes beyond the signal throw event, and only the first signal is able to correlate to the waiting Process #1 instance(s). Any later concurrent signals fail, and, because the whole transaction couldn’t be committed, completing Task 2 fails.
The problem goes away if I add an asynchronous continuation after Task 2: Any number of tasks can then complete at the same time. I’m guessing this does not actually get rid of the signal race condition, but it just gets resolved automatically within the engine?
What I don’t understand is that the document about Transactions in Process lists a Signal Event as an automatic Wait State. I thought that means the element has an implicit “async before”, and therefore the transaction boundary of Task 2 should not go beyond the signal throw, and therefore could be committed safely multiple times?
But obviously my mental model is not quite right ![]()
Where is my thinking going wrong, and am I understanding the situation at all correct?
Thanks in advance! ![]()