we have an existing SQL-Server 2014 Database where the History-Tables consume a lot of space (~60GB). So we decided to setup the History-CleanUp for old data.
We did the following configuration in the bpm-plattform:
And with the API-Calls we defined the History-TTL, and startet the CleanUp-Job.
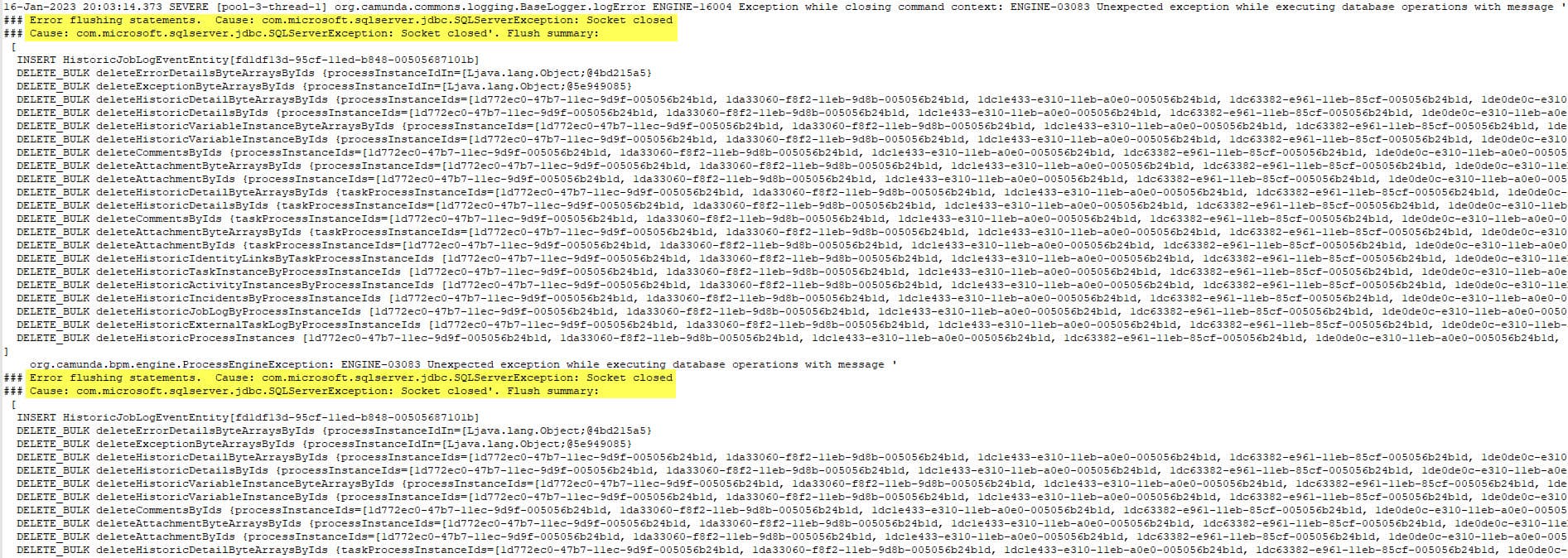
Due to the Job-Log-Table, it seems that in the first night, the Job runs succesfully a few times and also deleted some old data. But then we got the following exception:
And since then, every night at 8PM we only get the exact same exception three times in a row and then the job waits for the next night.
Can you help me out what’s excatly the problem why the job fails every night?
Did we misconfigure something? Or does it rather look like a DB problem (e.g. a Lock, …)?
Hi Manuel,
the error suggests that the database is closing the connection at 20.03.14. (After more than 3 minutes since the batch is started)
Why did happen?
There could be several causes.
I’d check if there are locks in the database tables caused by a previous batch that didn’t finish correctly.
Once the lock (if any) are removed, I’d retry to run the batch with less data, to check if the problem may be caused by the volume.
Then of course fine tuning MSSQL could help a lot.
These are just my 2 cents,
Have a good day,
Enrico
Hy Enrico,
thx for your response.
Yesterday in the evening I changed the BatchSize from 10 to 1 and tonight I didn’t get any errors in the ACT_HI_JOB_LOG-Table, but 26 log-records with the respective JOB_ID_ - so it seems that the clean up should have be done. But unfortunately the count of entries e.g. in the ACT_HI_DETAIL-Table didn’t change since yesterday…
I will observe this behaviour in the next days.
Concerning the fine tuning of MSSQL, how could I tune the camunda-relevant tables? All of the DB-Schema is created automatically by camunda and I’m not sure if can simply e.g. change sth with the index or any else?
Hi Manuel,
strange to read that you didn’t find any change in the database history tables after the batch execution.
As for the fine tuning I was not thinking at changing the Camunda schema, that can be risky, but more a general check up to ensure that there are no issues for the performance (check if the overall performance is ok, is the cpu enough?, etc)
which api call did you use to define the History-TTL?
Hint: the “normal” way of defining a History TTL for deployed process definitions does not affect the passed process instances. They will still have no TTL date on their data.
This can be solved by setting a removal time on historic process instances using a batch:
Hy Enrico,
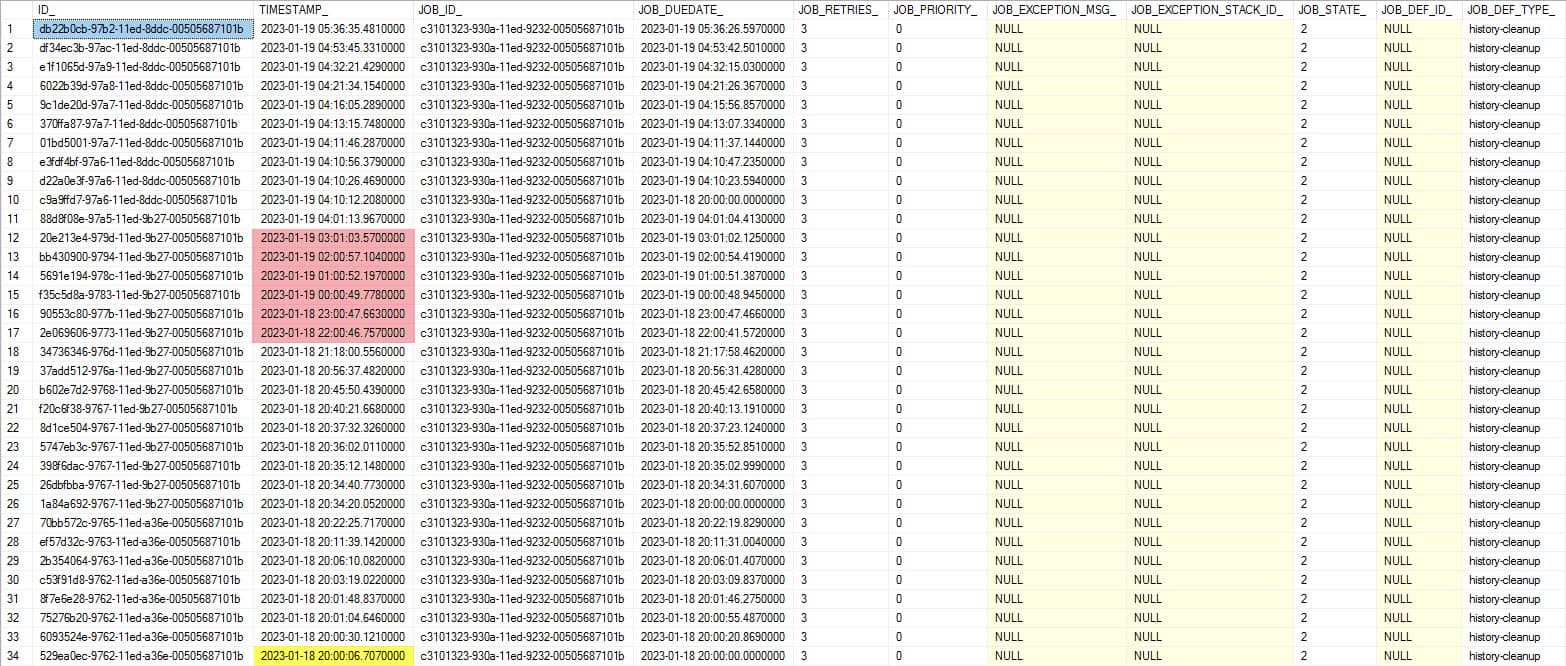
today I found at least one process-definition where the number of entires decreased compared to yesterday. But what’s still strange is, that I defined a clean-up window from 8PM to 6AM. But when I check the JOB_LOG-Table, I only have 34 entries for this night:
The first BULK-Deletes seems to be rather “fast” (about 30 seconds each) - but as you can see e.g. from 10PM to 2AM there are only 6 entries in the Log-Table.
Of course, during the night there are also some DB-Jobs running, but none of them has to do with Camunda (most of them do some ETL-Jobs).
Why do the BULK-Deletes take so long?
this will not affect passed process instances.
You would see this in the tables act_hi_* in the column removal_time_ or something similar.
To calculate a removal for each entry based on the History TTL, please use the endpoint provided above to configure a batch that calculates the removal time.
For more information about the history cleanup, please find this section in the docs:
There, it is explained how the cleanup works internally.
There are various reasons why a bulk delete can take long:
The DB is under high load
The cleaned up data volume is high (for example if the process instance refers to many bytearrays or the activity instances are a lot)
For now, you could track the duration of the cleanup jobs and check if you find special timeslots where they take long.
thank you very much, now I think I got it…
I only had these few CleanUp-Entries because the Removal_Time is only set for new process instances. For each instance that was already finished before I set the TTL on the definition, this had no effect at all.
I’ll try to set the Removal_Time for a few instances using the batch and then hopefully everything should work as expected.