Hi,
Consider the scenario where there is:
- A clustered setup (multiple nodes, shared database)
- There is a multi-instance call activity, that calls a sub-process in parallel, N times.
When the multi-instance call activity executes, it creates N rows in the job table.
In my experiments, all N rows initially get locked by ONE of the nodes in the cluster (N rows in the ACT_RU_JOB table with the same LOCK_OWNER_).
I think this is because each node’s job acquisition thread is querying at a different times, and one “wins” and beats the others to the N rows. Either that or there is some optimization going on that hints to the same node that’s running the process instance with the call activity, to immediately grab the sub-process start jobs.
Either way, the launching of the sub-processes does not get distributed across the nodes, but only goes to a single node.
I would like to hear if it’s possible to distribute these sub-process starts across the fleet of worker nodes.
NOTE: the start event of each sub-process has an async-before. This is so that the fact that it started can be tracked in the database.
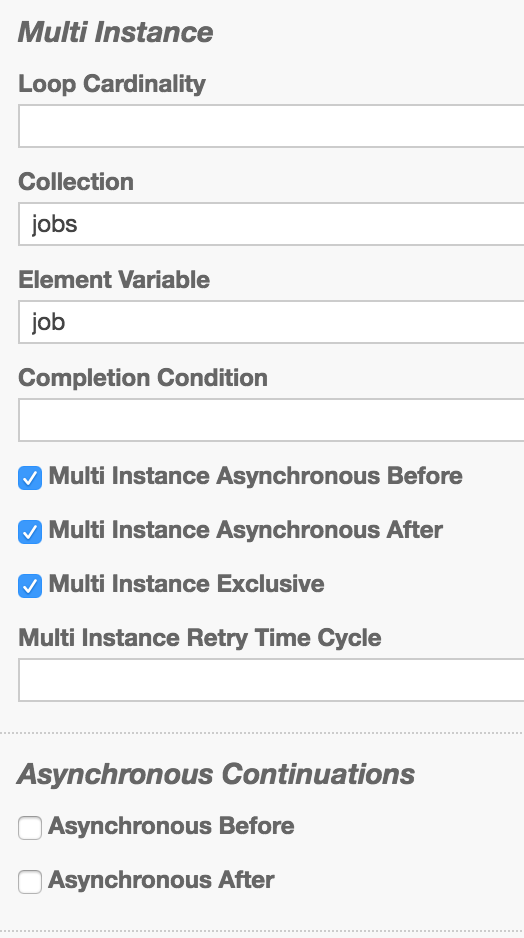
My call activity has these settings
:
Thanks,
Galen
Hi Galen,
it’s possible to distribute the jobs to different nodes. However, you can’t force the behavior. On every node, the job executor acquires new jobs at a different time. And, there is an optimization that hints the job executor when a new job is created (on this node).
You can adjust the job acquisition in the process engine configuration.
Also, please have a look at the docs about exclusive jobs which controls the concurrent job execution.
Can you tell more about your use case?
Why do you need to distribute the execution?
Best regards,
Philipp
1 Like
Hi Philipp,
Consider the case where there is one parent process that want to farm out a lot of (similar) work in parallel to different machines. For example, an insurance company that wants to re-process 1000 applications. If the re-processing of an application is CPU, memory, or time intensive, then it makes sense to distribute this work to multiple machines.
Or perhaps you have a system that needs to process 1000 things, where each thing takes 10 seconds, in a total of 10 seconds. In this case, if each machine has 10 threads available, then you would run on 100 machines at the same time.
It seems that currently the optimization puts all 1000 jobs on the same machine as the parent process.
I do understand that once the max pool configuration thread count is exceeded, it will force other nodes to pick up the jobs, but in my case this is inefficient because all of my processes have an async-before on the start event. This means that the only way I can force them to distribute is to introduce an artificial sleep as the first step in the process. This sleep forces it into N active threads, and when N exceeds the maxPool count, only then does it distribute to other nodes.
So lets say I have machine A and machine B. It goes something like this:
- A runs parent process
- A executes multi-instance call activity (1000 parallel jobs)
- Optimization hints to A to message the start of 1000 jobs on A
- A starts 1000 rows, immediately going right back to the database 1000 times.
- Optimization re-hints to A to pick up more jobs immediately
- A gets N threads into an active state (where N is defined in the process engine configuration)
- Now, the rest of the jobs start to get picked up by B at B’s next acquisition time
NOTE: We require async-before on all process definition start events, so that every process start is audited / recorded in the database.
Thanks,
Galen
Hi Galen,
thank’s for the insides. Maybe we can optimize your process a bit. Can you disable the multi-instance async before of the call activity? In this case, the engine can create all jobs at once and hopefully distribute the jobs better.
Can you also share your process engine configuration?
Beside that, you may also interested in the custom-batch community extension. See the related blog post.
Best regards,
Philipp
Hi Galen,
I would have thought the external task pattern [1] would be ideal for your use case…
regards
Rob
[1] https://docs.camunda.org/manual/7.8/user-guide/process-engine/external-tasks/#the-external-task-pattern
Hi Rob,
I want to spin up many things (e.g. 1000 things). The external pattern would work to distribute the load out, but I would still need a multi-instance external task in this case. My point was that the multi-instance would still route everything to one node at first. Then, yes, it would distribute to external workers. But I wanted a way to distribute the tasks to multiple job-executors, even before the external task gets reached in the process instance.
Also, I wanted to not have to spin up extra processes on extra machines. I just wanted distributed processes to happen on my clustered nodes (normal job executors).
I haven’t had a chance to try out Philipp’s suggestion of disabling the multi-instance, but I will try that soon.
Thanks,
Galen