What type of Camunda implementation are you using?
In some situations, such as sending message correlations, OptimisticLocking does not generate retries, as it is a concurrency exception, which occurs when 2 or more concurrent update attempts occur on the same entity.
Make sure through logs that the retries generated are due to the optimisticLocking error…
But if optimistic locking is being generated in a service task or script task, I suggest that an ExceptionHandler be created for handling, directly handling the OptimisticLockingException.
With this you can define the appropriate behavior, you can even give a “throw new bpmnError”, to transfer the responsibility for the treatment to the flow in Camunda and there you can make the magic happen using the error event! hehehehehe!
I have service tasks that are running in multi-instance. I see it mentioned in the logs that the error is because of optimistic locking.
Regarding Exception Handler I have the following questions :
Can you give an example for how to do this? I have not done this for camunda.
Ideally in the exception handler I would like to skip retry of the task. How to do that in this case?
Is it safe to skip the retry? Is there some corrupted state that would result in the engine ifI do that?
Regarding throwing BPMN error :
This is definitely simpler. But its not clear to me where I can catch it. This is the stack trace :
at org.camunda.bpm.engine.impl.db.EnginePersistenceLogger.concurrentUpdateDbEntityException(EnginePersistenceLogger.java:125)
at org.camunda.bpm.engine.impl.db.entitymanager.DbEntityManager.handleOptimisticLockingException(DbEntityManager.java:323)
at org.camunda.bpm.engine.impl.db.entitymanager.DbEntityManager.flushDbOperationManager(DbEntityManager.java:295)
at org.camunda.bpm.engine.impl.db.entitymanager.DbEntityManager.flush(DbEntityManager.java:278)
at org.camunda.bpm.engine.impl.interceptor.CommandContext.flushSessions(CommandContext.java:247)
at org.camunda.bpm.engine.impl.interceptor.CommandContext.close(CommandContext.java:176)
at org.camunda.bpm.engine.impl.interceptor.CommandContextInterceptor.execute(CommandContextInterceptor.java:113)
at org.camunda.bpm.engine.impl.interceptor.ProcessApplicationContextInterceptor.execute(ProcessApplicationContextInterceptor.java:66)
Another thing that can be done to help avoid optimisticLockingExeption… is to mark it as “Asynchronous Before” and “Exclusive” in your task, this will greatly minimize the probability of this type of exception.
Is this multi-instance you are running a single task or a call-activity?
What type of multi-instance are you using, parallel or sequential?
If it is parallel, try changing it to sequential and see if optimistic locking continues to exist even when async before with sequential multi-instance.
If the error still persists, I may need to take a closer look at how this activity is being carried out to try to help you.
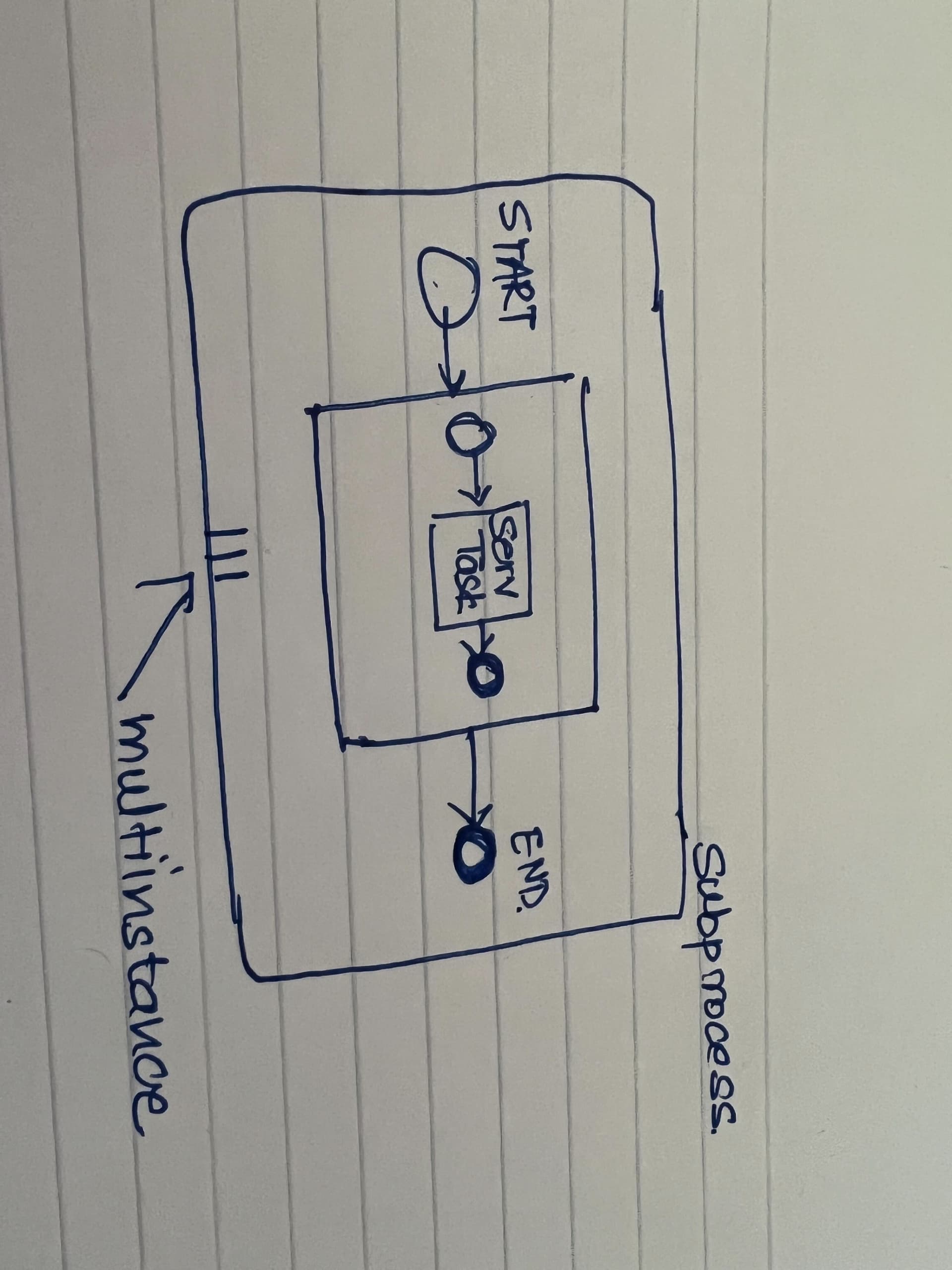
The second subprocess is added here because the service task internally are actually a bunch of service tasks which need to be retried atomically if they fail.
(1) ----> The outer subprocess has async before, async after and exclusive.
(2) ----> The inner subprocess does not have anything set
(3) ----> The service task has async before and async after.
I cannot set exclusive on 2 or 3 because it disables the multi-instance function and they execute serially.
Now whenever I run this, I get the optimistic locking exception 100% of the time for atleast once of the multi-instance activities once the service task completes.
This task is time sensitive, so even though it could be made idempotent, I don’t want to repeat when optimistic locking happens. Its they same reason why I cannot change it to sequential. It is time sensitive.
Can you please advice on what can be done to avoid optimistic locking and handle it when it happens?
Hi William,
okay, I cannot share my file as is but can create a example that matches. Unfortunately, I don’t know if I will be able to reproduce the error in the sample file. As I mentioned I cannot make it sequential because it is a time sensitive process and needs to finish in parallel for my solution to be viable.
I understand, if you could give us a file with a similar model to what you have, containing a similar variable update scheme, etc… just changing the confidential values, that would be great!