Hi I am currently busting my brain about a workflow and due to my lack of experience with bpmn I have no idea how to model it. Would be great if someone could support me.
As startup I tried to model it like this (Please note that this is just an unfinished model not usable yet) proof-of-concept.bpmn (14.7 KB)
What I want to achieve:
We got a service that accepts several clients that are able to send some data. If data is received the process is being started.
Each client is allowed to send several data objects in separate requests. So each http request contains one data-set (not many) and the client receives a (server-side) unique identifier for this data-set.
I now need to fetch and claim the three job instances referenced by the data-ids and follow the rest of the process with these 3 jobs merged into a single job.
Is this even possible? to claim 1 to n instances that will then be merged into a single job?
I haven’t used Camunda 8 that much, but I would give you an answer to that question how to do it in Camunda 7. I’m sure there is a way to translate it, probably by using the REST API of Operate.
The way I would do it is store a dataId variable on every process of the type and then perform a process instance GET request filtered by that variable name (dataId) and value (the actual id), maybe add a process definition key to the filter to make it mode specific if you want to use this variable on other process definitions.
Using the process instance information, it’s possible to get the job information (I believe this fits the message or user task type) and you can complete it via REST. Also, since you have the process information, you have all the data within the variables and you can combine it in a new call that starts a different process with all of it combined.
All these REST calls can be done either externally, or using a process that was triggered by the client using the URL you mentioned.
I think why you’re struggling is due to process-instance cardinality issues.
A workflow should always be dealing with the same number of items.
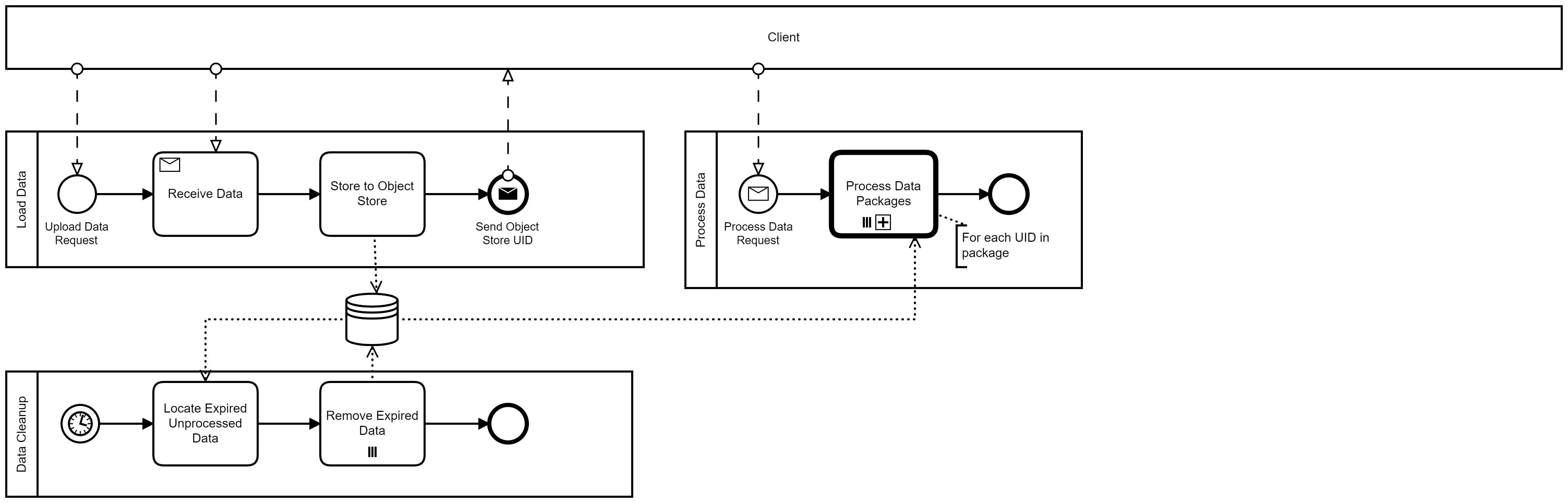
What actually starts your workflow once the client has finished uploading the various objects to your system? Point 3 seems to indicate that you’re getting a message that contains all the data-id values for a particular run. That then becomes the start of your process. This particular workflow then collects all these data objects from the underlying object store and begins to process them.
You seem to have a second process that receives a “Upload Data” request (Point 1) and on successfully storing the object to the object store, it returns a message back to the client containing the UID. (Point 2)
Since the main working process (Point 3) starts by getting a message that contains all the ID’s you can then use a multi-instance subprocess to work through each of the related data objects. Each subprocess is working with just one data object, so it becomes “Fetch ->Process”
There’s a big risk in this process design though… What happens if your black-box (Client) uploads a bunch of objects, but then never sends you the “Process all of these objects together” message?
Hey, you are right. Splitting it in two different processes will probably solve the issue. The other addressed issue is already thought of. We are just caching the data, so there will be a time limit to when the incoming data is being disposed of if not handled.
Thx for helping out here but I still have one problem here.
How do I get this working?
the client sends the data and then redirects the user with the browser to our application
How can I make sure that I process the data packages that the user just triggered are processed on the same application node? (Assuming that the application is horizontally scaled)
From what I grasped so far about camunda, it is a message based broker system pretty similiar to kafka. My current impression is that its not suited for synchronous user-process handling but rather only for asynchrounous process handling. Since we have users that directly need the answer of the processed data I am not quite sure if this is the correct way to go. But maybe I am just not getting the concept quite right.
That is related to the issue I identified… Your process as described has the client responsible to collating the datasets to be processed together.
Zeebe doesn’t actually do the work. It only coordinates the work to be done (eg. think similar to Zeebe is the project manager…) You can’t really be sure that all the work of processing the data sets happen on one node, but the individual workers will report back their results to Zeebe, who can then present the unified results to the client.
I was just writing a long complex answer but I think I finally got it.
I was simply thinking the wrong way.
I thought in order to handle user-events I would need to create a user-task within the workflowengine and claim these tasks if a user were going to access my application with a specific data-id but that is wrong.
I need to handle the request of the user directly in my application on have to send a success-message-event to the workflow-engine on completion or a failure-message-event.
You opened my eyes here. Thank you very much. I think I should be able to get it from here on