The topic speaks for itself. As I can see on forum, there is a statement ‘DB is always assumed to be centralized’ - is it still true?
Is it possible to use something like Citus with Camunda?
Are there any other ways to organize sharding?
Thanks in advance!
Hi,
Heres a link to Zalando who use a sharding approach with impressive results…
regards
Rob
@Webcyberrob, thanks for your reply!
Unfortunately, provided information is too high-level… Do they run multiple camunda instances? Does each instance run N process engines each linked to its own shard? How do they handle autoscaling in this case?
Thanks.
Hi,
I believe an architecture they used was something like eight DB instances with say four engine nodes per DB instance. One pair was clustered for web requests, the other pair for job executor processing.
Given they had eight shards, to route to the correct shard, take something like the email address of the order and hash it down to a number from 0…7. Hence this determines which to route to.
They may have configured all eight engines on each node, as that means any node could handle any request, but Im not 100% clear if they did or didnt do this.
The above is my understanding of their architecture from a few years ago (it may have changed) and I gleaned this from presentation snippets (so I could get a few parts wrong)…
Perhaps an @zalando rep in the forum may comment with more authority…
regards
Rob
1 Like
Are you talking about scheme like this?
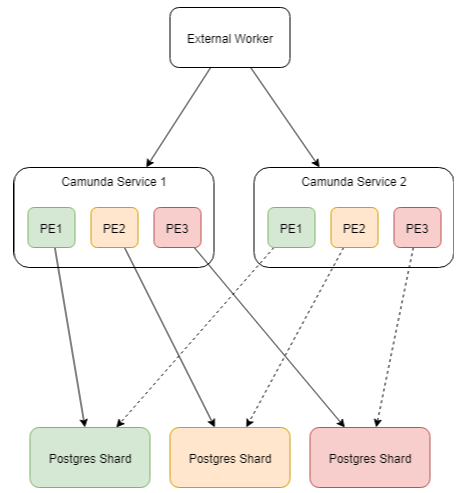
So each time I want to add new shard, I need to change Camunda configuration, add new PE and redeploy all instances… Can work with fixed number of shards, but we need solution which can scale automatically.
Hi,
Yes thats essentially the architecture patter I was referring to. In terms of auto scale, you can horizontally scale out the engine nodes. Auto-sharding the DB tier is a little more challenging. However you can vertically scale the DB tier.
Thus as a hybrid, can you start with a fixed number of shards and combine horizontal autoscale and vertical scale when required on DB tier? AWS PaaS make this approach possible…
regards
Rob
Hi,
Heres another interesting architecture approach based on AWS PaaS…
Set the number of shards to be fixed, eg 8
Use Elastic Bean Stalk to auto scale engine nodes up and down based on load
Use Serverless Aurora to autoscale the DB tier up and down.
So in summary, set the number of shards to be a reasonable. fixed size envelope. Use autoscale within shards to help optimise resource usage. (Note Aurora is not an officially supported Camunda tech).
regards
Rob
1 Like
Ok, that looks interesting. Thank you for your help!
We we also consider an option of scaling [camunda instance + db shard] pair though it looks a little bit more complex.
Hi,
BTW - are you aware of Zeebe? This zeebe content may be of future interest…
regards
Rob
Yes, I monitor Zeebe blog, but it is still beta, which is no-go for us.
Going back to the original question: yes! Camunda BPM completely depends on an ACID-complaint database backend to do its work properly. As such, the term “centralized” only applies to the guarantee of ACID-compliance, not necessarily in the sense of “single” instance.
The correct answer (most gain with minimal efforts) for you depends on what your major concern is. If it is performance, then citus might be worth a look (it should not require any change in Camunda queries and provides the same ACID guarantees) but it can backfire with queries that go across the shard you are selecting initially (joins, sub-selects, …).
Also it depends if you are concerned about read or write performance or scalability of both and whether you have history active or not (which can have a huge impact in both, read and write).
To tackle the degrading performance with growing history alone (level: AUDIT) I have recently used the timescale extension for PostgreSQL to auto-manage partitioning of the history tables (although I think there is a serious database mis-conception with the byte-arrays, which are not historic at all). This has lead to a dramatic improvement for the majority of queries and helped to maintain a near-constant performance (except for anything requiring byte-arrays) even with a year of history data. We usually had ~5000 pretty complex process instances per day (peaks up to ~30000) with many polling loops, a lot of variables per instance (10 - 50) with many updates.
All where using a single PostgreSQL node on SSD with PGPool-II + PostgreSQL async replication for HA and automatic failover/failback/recovery.
While the setup that Zalando has created is much more scalable, it might be overkill for your use-case.
@Webcyberrob i looked into Zeebe, which internally uses camunda. So what is the advantage over camunda by using zeebe?
Will Zeebe also opensource which can support bpmn, dmn & cmmn standards?
Hi @aravindhrs, my name is Mike, and I’m on the Zeebe team at Camunda. I can try to answer some of your questions.
• One thing to note is that Zeebe does not use Camunda internally, and Zeebe is being built from scratch as a new, separate workflow engine. Because of some of the differences in how Zeebe vs. Camunda BPM are built, Zeebe might be a good fit for you if you’re concerned with throughput and scalability. Specifically, Zeebe doesn’t rely on a relational database (or any database) for storing workflow state, which makes it possible to scale horizontally to high throughput without a DB acting as a bottleneck.
• We talk a bit about how we handle workflow state in the Zeebe docs - this entry might be a good place to start, and the blog post that @Webcyberrob mentioned also covers this topic in depth.
• Same as Camunda, Zeebe executes BPMN 2.0 workflow models. However, as of right now, Zeebe supports fewer symbols than Camunda BPM. This docs entry shows exactly what symbols are currently supported by Zeebe. We’ll continue to add more symbols in the future as we get feedback from users about which symbols are most important for key Zeebe use cases.
• Zeebe also supports DMN - there are a couple of DMN workers available under “Workers” on the Awesome Zeebe page: https://awesome.zeebe.io. Note that you’d use a service task in your Zeebe model, then you could simply build an external service based one of these DMN workers to work on the task (keeping in line with the principle of decoupled services).
• We don’t have any plans to support CMMN in Zeebe.
• And lastly, Zeebe is also open source. Most of Zeebe uses the Apache 2.0 license. If you have any Zeebe questions at any point, we’d love to hear from you on the Zeebe forum! https://forum.zeebe.io/
I hope that helps, and please let me know if I can clarify.
Best,
Mike
4 Likes
Can someone share more details on how to shard database used in camunda?
have gone through zalando slides above but information is very less