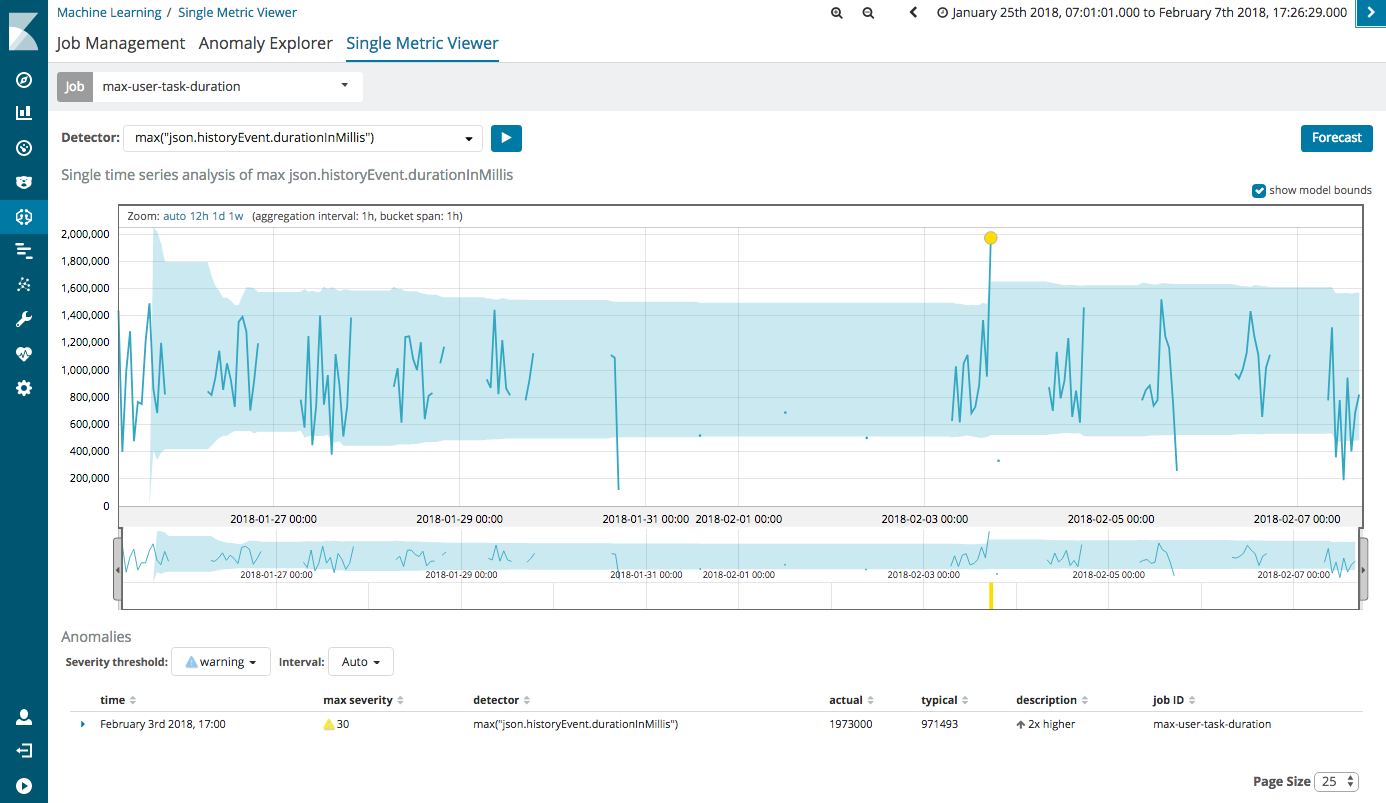
myjson.json
[
{"timestamp":"2018-01-15T00:10:38.795+0000","historyClass":"HistoricProcessInstanceEventEntity","historyEvent":{"id":"6","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"start","sequenceCounter":0,"durationInMillis":"-","startTime":"2018-01-15T00:10:38.783+0000","endTime":"-","businessKey":"-","startUserId":"-","superProcessInstanceId":"-","superCaseInstanceId":"-","deleteReason":"-","endActivityId":"-","startActivityId":"StartEvent_1","tenantId":"-","state":"ACTIVE","durationRaw":"-"}},
{"timestamp":"2018-01-15T00:10:38.854+0000","historyClass":"HistoricActivityInstanceEventEntity","historyEvent":{"id":"StartEvent_1:20","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"start","sequenceCounter":1,"durationInMillis":"-","startTime":"2018-01-15T00:10:38.854+0000","endTime":"-","activityId":"StartEvent_1","activityName":"Start","activityType":"startEvent","activityInstanceId":"StartEvent_1:20","activityInstanceState":0,"parentActivityInstanceId":"6","calledProcessInstanceId":"-","calledCaseInstanceId":"-","taskId":"-","taskAssignee":"-","tenantId":"-","assignee":"-","completeScope":false,"canceled":false,"durationRaw":"-"}},
{"timestamp":"2018-01-15T00:10:38.864+0000","historyClass":"HistoricVariableUpdateEventEntity","historyEvent":{"id":"21","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"create","sequenceCounter":1,"variable":{"type":"integer","value":55},"tenantId":"-","taskId":"-","timestamp":"2018-01-15T00:10:38.862+0000","activityInstanceId":"StartEvent_1:20","userOperationId":"-","variableName":"someNumber","variableInstanceId":"7","scopeActivityInstanceId":"6","revision":0}},
{"timestamp":"2018-01-15T00:10:38.885+0000","historyClass":"HistoricVariableUpdateEventEntity","historyEvent":{"id":"22","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"create","sequenceCounter":1,"variable":{"type":"string","value":"1234 Alpha"},"tenantId":"-","taskId":"-","timestamp":"2018-01-15T00:10:38.883+0000","activityInstanceId":"StartEvent_1:20","userOperationId":"-","variableName":"someText","variableInstanceId":"8","scopeActivityInstanceId":"6","revision":0}},
{"timestamp":"2018-01-15T00:10:38.886+0000","historyClass":"HistoricVariableUpdateEventEntity","historyEvent":{"id":"23","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"create","sequenceCounter":1,"variable":{"type":"short","value":31767},"tenantId":"-","taskId":"-","timestamp":"2018-01-15T00:10:38.886+0000","activityInstanceId":"StartEvent_1:20","userOperationId":"-","variableName":"someSort","variableInstanceId":"9","scopeActivityInstanceId":"6","revision":0}},
{"timestamp":"2018-01-15T00:10:38.887+0000","historyClass":"HistoricVariableUpdateEventEntity","historyEvent":{"id":"24","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"create","sequenceCounter":1,"variable":{"type":"null","value":"-"},"tenantId":"-","taskId":"-","timestamp":"2018-01-15T00:10:38.886+0000","activityInstanceId":"StartEvent_1:20","userOperationId":"-","variableName":"someNull","variableInstanceId":"10","scopeActivityInstanceId":"6","revision":0}},
{"timestamp":"2018-01-15T00:10:38.888+0000","historyClass":"HistoricVariableUpdateEventEntity","historyEvent":{"id":"26","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"create","sequenceCounter":1,"variable":{"type":"serializable; java.lang.Byte","value":"rO0ABXNyAA5qYXZhLmxhbmcuQnl0ZZxOYITuUPUcAgABQgAFdmFsdWV4cgAQamF2YS5sYW5nLk51bWJlcoaslR0LlOCLAgAAeHAC"},"tenantId":"-","taskId":"-","timestamp":"2018-01-15T00:10:38.887+0000","activityInstanceId":"StartEvent_1:20","userOperationId":"-","variableName":"someByte","variableInstanceId":"12","scopeActivityInstanceId":"6","revision":0}},
{"timestamp":"2018-01-15T00:10:38.889+0000","historyClass":"HistoricVariableUpdateEventEntity","historyEvent":{"id":"28","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"create","sequenceCounter":1,"variable":{"type":"date","value":"2018-01-15T00:10:38.634+0000"},"tenantId":"-","taskId":"-","timestamp":"2018-01-15T00:10:38.889+0000","activityInstanceId":"StartEvent_1:20","userOperationId":"-","variableName":"someDate","variableInstanceId":"13","scopeActivityInstanceId":"6","revision":0}},
{"timestamp":"2018-01-15T00:10:38.890+0000","historyClass":"HistoricVariableUpdateEventEntity","historyEvent":{"id":"29","processInstanceId":"6","executionId":"6","processDefinitionId":"historyGeneration:1:3","processDefinitionKey":"historyGeneration","processDefinitionName":"-","processDefinitionVersion":"-","caseInstanceId":"-","caseExecutionId":"-","caseDefinitionId":"-","caseDefinitionKey":"-","caseDefinitionName":"-","eventType":"create","sequenceCounter":1,"variable":{"type":"boolean","value":true},"tenantId":"-","taskId":"-","timestamp":"2018-01-15T00:10:38.890+0000","activityInstanceId":"StartEvent_1:20","userOperationId":"-","variableName":"someBooleanT","variableInstanceId":"14","scopeActivityInstanceId":"6","revision":0}},
This file has been truncated. show original