Hi,
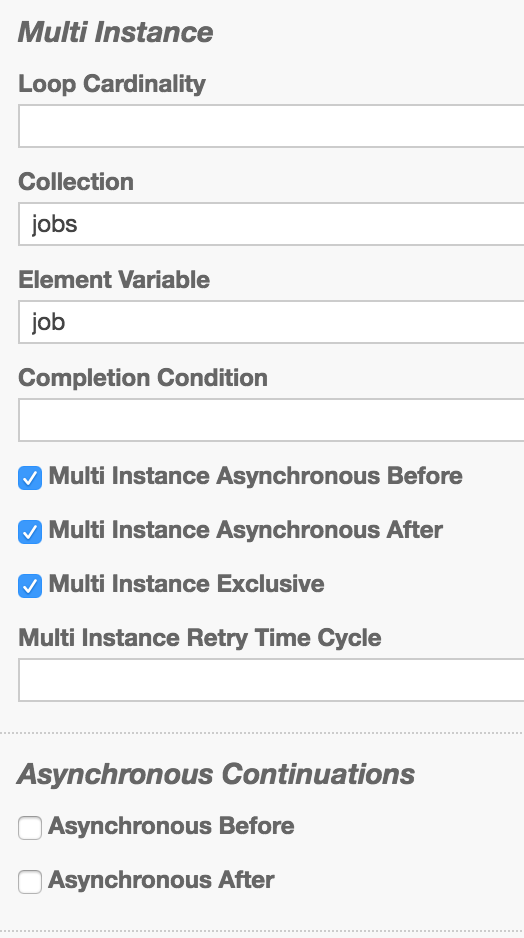
I’m seeing a situation where I have a multi instance call activity that calls a sub-process 500 times (iterating over a collection as input). The sub-process executes fine pretty quickly. So far everything is good.
Then, the parent process takes about 2 or 3 minutes to finish running.
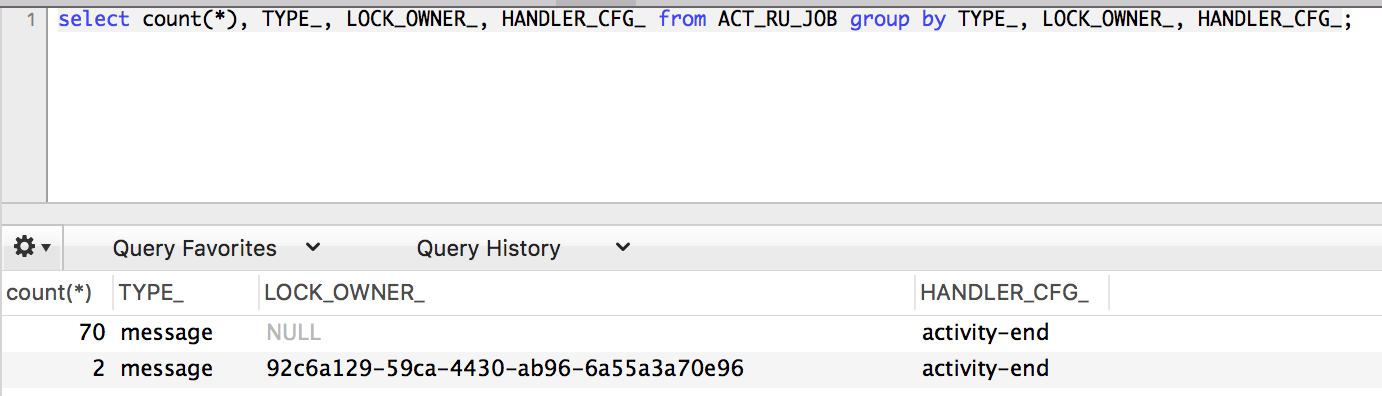
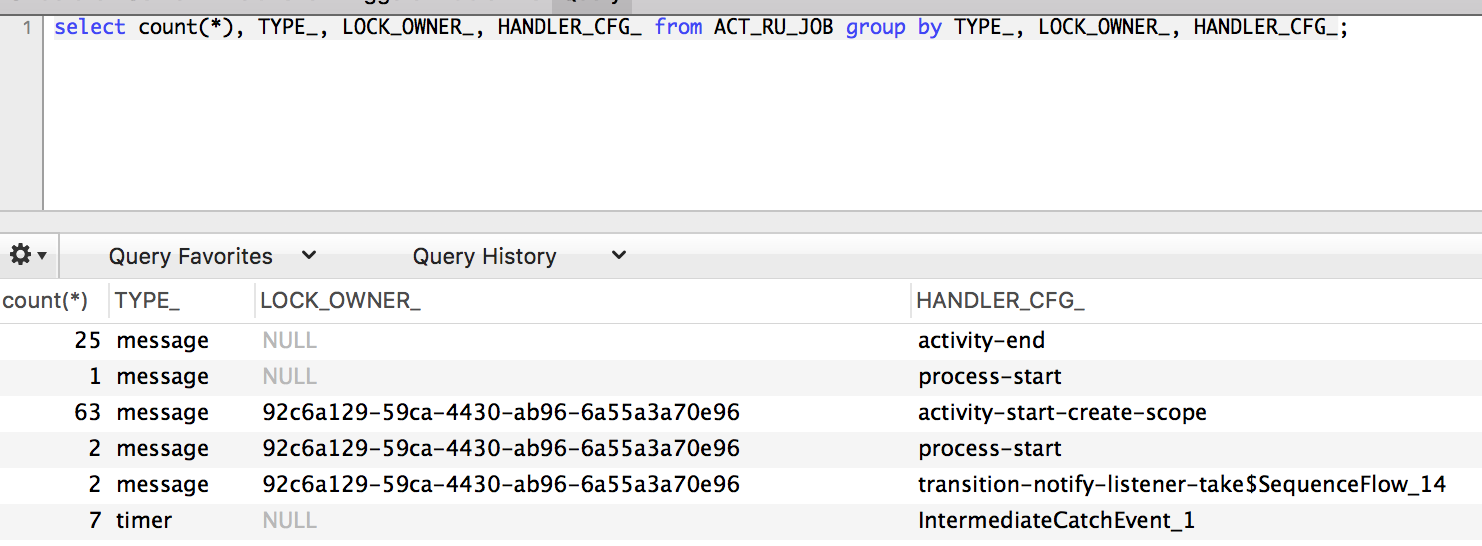
If I look at the ACT_RU_JOB table, I see one to three (but no more than three) rows that have an LOCK_OWNER_ set. If I keep requerying this table, I see the number of rows jump around (1, 2, or 3 rows). It appears to be iterating over and finishing up all 500 sub processes, but only up to three at a time. The TYPE_ column says “message”, and it appears to be ending each of the multi instance sub-processes. It appears to be setting variables like “nrOfCompletedInstances” as it progresses.
It doesn’t appear to be a bottleneck in the database, because I don’t see any long-running updates/queries. Something just seems to be taking a long time in the “cleanup” phase of the multi instance call activity.
Do you have any ideas what might be happening, and what I can do?
Thanks!
Galen