Hi,
We have some trouble with zeebe (v8.6.9), and I haven’t found any way to manage this.
We have some worker that will execute some long tasks (like 20 minutes, but it could be several hours), in a dedicated kubernetes pod.
Sometimes, for internal reason, we have an out of memory during the execution of the task. The pod will restart, and because of this out of memory, we don’t have any way to send grpc command (including the autocomplete).
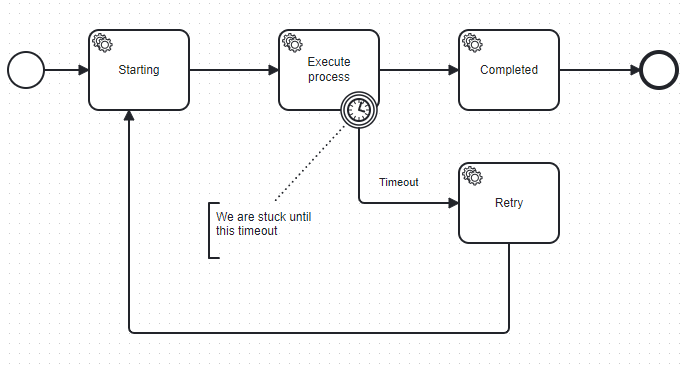
What’s append, is that from zeebe perspective, the worker is continuing to execute this task, and our workflow will be restarted only after a timeout, so after half an hour, or more for longer task. But for our users, it’s not possible to wait that long to have the workflow unblocked automatically.
Zeebe don’t have any way to knows that the worker is dead, and do automatically a retry on another worker ?
Because the worker will stop the polling, we seems that strange that we have our workflow is waiting for nothing like zeebe broker don’t know anything about this.
This is a simplification of our model that we use, and we will wait for the timeout to reexecute the task.
Hi @aroquemaurel - I think a combination of idempotency and timeout settings is the answer here (but would love to hear solutions from others too!).
The default timeout for a job worker is 5 minutes, and you can adjust as needed in your config. The timeout isn’t how long the job can run, but rather an instruction for Zeebe that says “After this much time, you can assign the job to another worker, something might be wrong here.” After the timeout, another job worker can connect and will be assigned the job.
As long as the workers are well-written and idempotent, they should be able to pick up the new job without causing further issues. This docs page goes into more detail:
Hi @aroquemaurel, a possible complimentary approach building on the advice of @nathan.loding is to have your long running service task worker periodically extend the job timeout using the gRPC UpdateJobTimeout command or if using the unified REST API there is a PATCH operation on job. This is something like a heartbeat or a lease extension.
Have your long running worker actively extend its “lease” on the job. If your pod dies through OOM then the lease is not extended and Camunda will make it available to another worker more quickly vs. if you had set a timeout to be the expected duration of the task.
This is not full proof of course (we are dealing with vagaries of thread scheduling in the Java example below) but if you set your heartbeat (extend lease) with an appropriate buffer of time less than the timeout then it should be reliable. If a heartbeat is missed then another worker picks up the job again and as long as it’s actions are idempotent everything is ok.
If you were using Java with the Zebee annotations, maybe something like this …
e.g.
Expected duration of task = ~30 mins
TIMEOUT_MS = 60000 (60 seconds)
HEARTBEAT_INTERVAL_MS = 45000 (45 seconds)
Your worker “checks in” with Camunda every 45 seconds to say “extend my timeout again to 60 seconds from now”
public LongRunningWorker(ZeebeClient zeebeClient) {
this.zeebeClient = zeebeClient;
}
@JobWorker(type = "long-running-task", timeout = TIMEOUT_MS)
public void handleLongRunningJob(ActivatedJob job) {
// thread safe way to share long running task completion status
AtomicBoolean isCompleted = new AtomicBoolean(false);
long jobKey = job.getKey();
// Start a separate thread for periodic timeout extension
Thread heartbeatTimeoutExtender = new Thread(() -> {
while (!isCompleted.get()) {
try {
Thread.sleep(HEARTBEAT_INTERVAL_MS);
extendJobTimeout(jobKey, TIMEOUT_M);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
});
heartbeatTimeoutExtender.start();
// long-running stuff here
isCompleted.set(true); // Signal to the extender that the job is complete
completeJob(jobKey);
}
Caveat - code was written by ChatGPT and I haven’t compiled it, let alone executed it, but it illustrates the concept.
Hello @nathan.loding and @herrier,
I have understood that worker should be idempotent – it’s the case – but in our application because it’s some pure computation that could take some time, it’s difficulte to manage this timeout value.
I like the way described by @herrier, with this solution I will be able to have the right timeout duration for zeebe, without waiting too long in case of trouble.
I will implement this heartbeat, it should do the work.