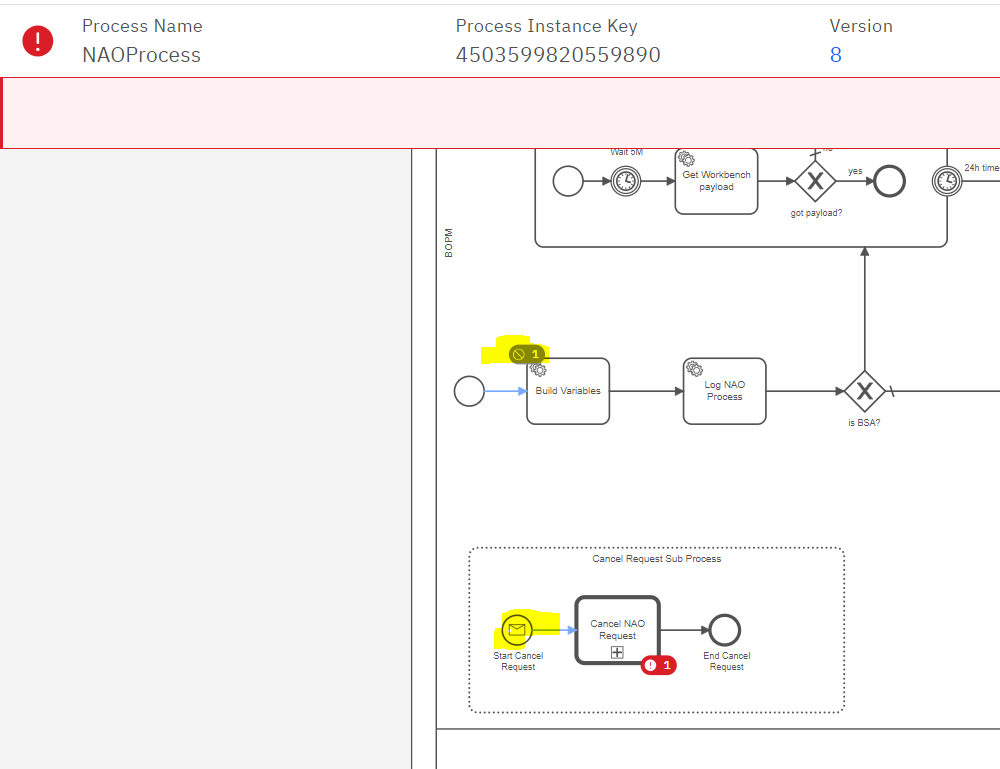
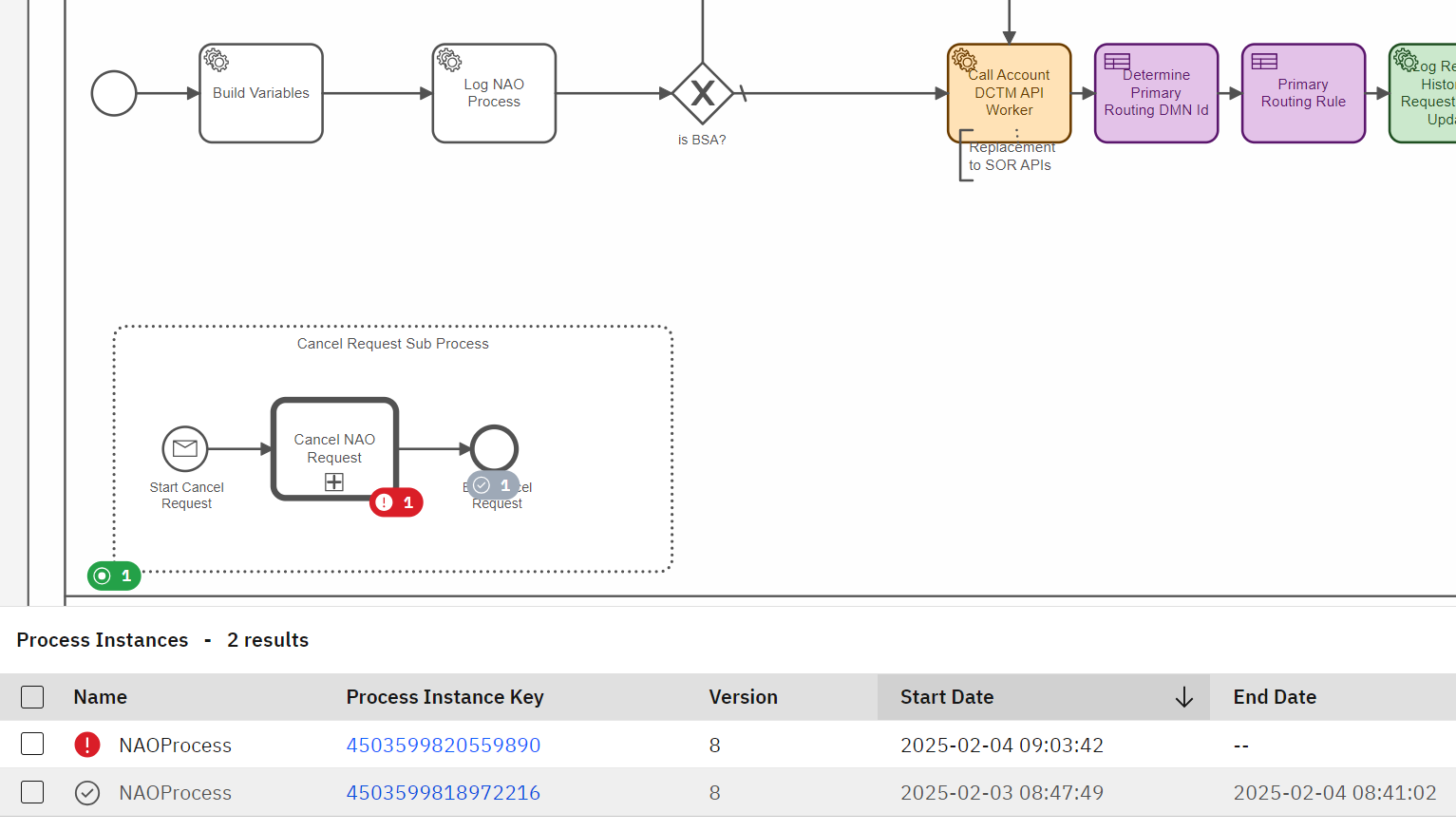
I have a process that after a number of worker tasks it gets to a Human task in which the user can “Cancel” the process instance. This sends a message to an event subprocess that effectively cancels the instance.
However, when a new process instance starts with the same id as the correlation id for the message event that triggers the event subprocess, the process flows to the Cancellation subprocess. Why could this be happening?
Hi @pedro.arroyo - correlation keys should really be unique across all process instances. The correlation key is how the engine identifies which process to send the message to.
A subscription is opened when a process instance awaits a message;
When a message is published and the message name and correlation key match to a subscription, the message is correlated to the corresponding process instance.
When a subscription is opened, it polls the buffer for a proper message. If a proper message exists, it is correlated to the corresponding process instance. In case multiple messages match to the subscription, the first published message is correlated (like a FIFO queue).
The buffering of a message is disabled when its TTL is set to zero.
We are not setting TTL, so it defaults to zero. Once the original process instance flows through the event subprocess, the message is consumed (or not?). So when a new instance of the process is created, therefore a subscription is created, why would it be activated if there was no message sent or buffered?
The completed one is the original instance that got cancelled correctly, the one in incident is the one that flowed incorrectly to the event subprocess as shown in my orignal post.
@pedro.arroyo - can you elaborate on how step #2 is happening? You say you’re canceling the process, what API call are you making to cancel it? Is it possible you are both canceling the process instanceandpublishing a message, and it creates an accidental race condition?
@nathan.loding the cancellation is implemented by throwing an event to the instance so that the event subprocess interrupts the instance into the sub process and completes the instance. So the Cancellation is a business term implemented the way I just described:
The code is this:
try (ZeebeClient client = clientBuilder.build()) {
client.newPublishMessageCommand()
.messageName(messageName)
.correlationKey(correlationKey).variables(messagePayload).send().join();
log.info("Successfully Published message to Zeebe for Message: {} with CorrelationKey {}", messageName, correlationKey);
} catch (Exception e) {
log.error("Error in Publishing message to Zeebe for Message: {} with CorrelationKey {}", messageName, correlationKey, e.getMessage());
throw new Exception ("Error in Publishing message to Zeebe for Message :"+messageName +" with CorrelationKey "+correlationKey + e);
}
how quickly after you start the new process instance does the subprocess get triggered? Is it immediate/very quickly, or does the process run for a short time first?
do you have multiple versions of the process being use, or only the latest?
how many instances of the process are running at any given time?
@nathan.loding - thank you for your time looking into this
fairly quick, if you see in the image of the opening post, the flow moved to the event subprocess when it was on the first activity (system task). There’s another instance that got to the second task before being interrupted.
yes, we have 8 versions, but only two have active instances, and only the latest has the addition of the Cancel event subprocess
7,223 as of today for this particular business process
Can you build a minimal replication that demonstrates the issue?
If others can test (and replicate) the workflow on their own instances of C8, then they are more likely to be able to assist.
Sometimes when building the minimal replication, the poster discovers what it is that is causing the issue…
@pedro.arroyo - I agree with @GotnOGuts here - I think trying to create a minimal reproduction of the issue would be very helpful. I did some very limited testing this morning and could not replicate the issue. It almost sounds like two messages are being published, even though that seems unlikely with how you’ve described your code. I’ve also asked the engineer team if there’s a convenient way to view what messages are buffered in Zeebe.
Hi @nathan.loding,
Unfortunately we are unable to reproduce this in a different environment. As Camunda customers we have access to Enterprise Support and the Support Engineer was also unable to repro.
If the docs are right, then this is a bug, but again, we’re on 8.3 with plans to move to 8.5 on the first half of the year. The fix would be to make sure that the correlation id is unique, and we’re going with that, but I’m concerned about this behavior.
Thank you all for chiming in, really appreciate the input of the community
Hey @pedro.arroyo - I agree, it’s a bit concerning, but it’s really hard to figure out what is going on without being able to reproduce it. If it is a bug, it seems like an edge case that is dependent on several other conditions (because it can’t be replicated outside your process/environment), and those conditions can be really difficult to identify. If you find some more info, definitely let me know!