Hello everyone!
As I have been hearing more and more chatter recently about the use of Camunda in microservice models, I wanted to share some tooling that we have been working on that was built for using many (dozens, hundreds, thousands +++) of Camunda instances/engines and clusters of engines.
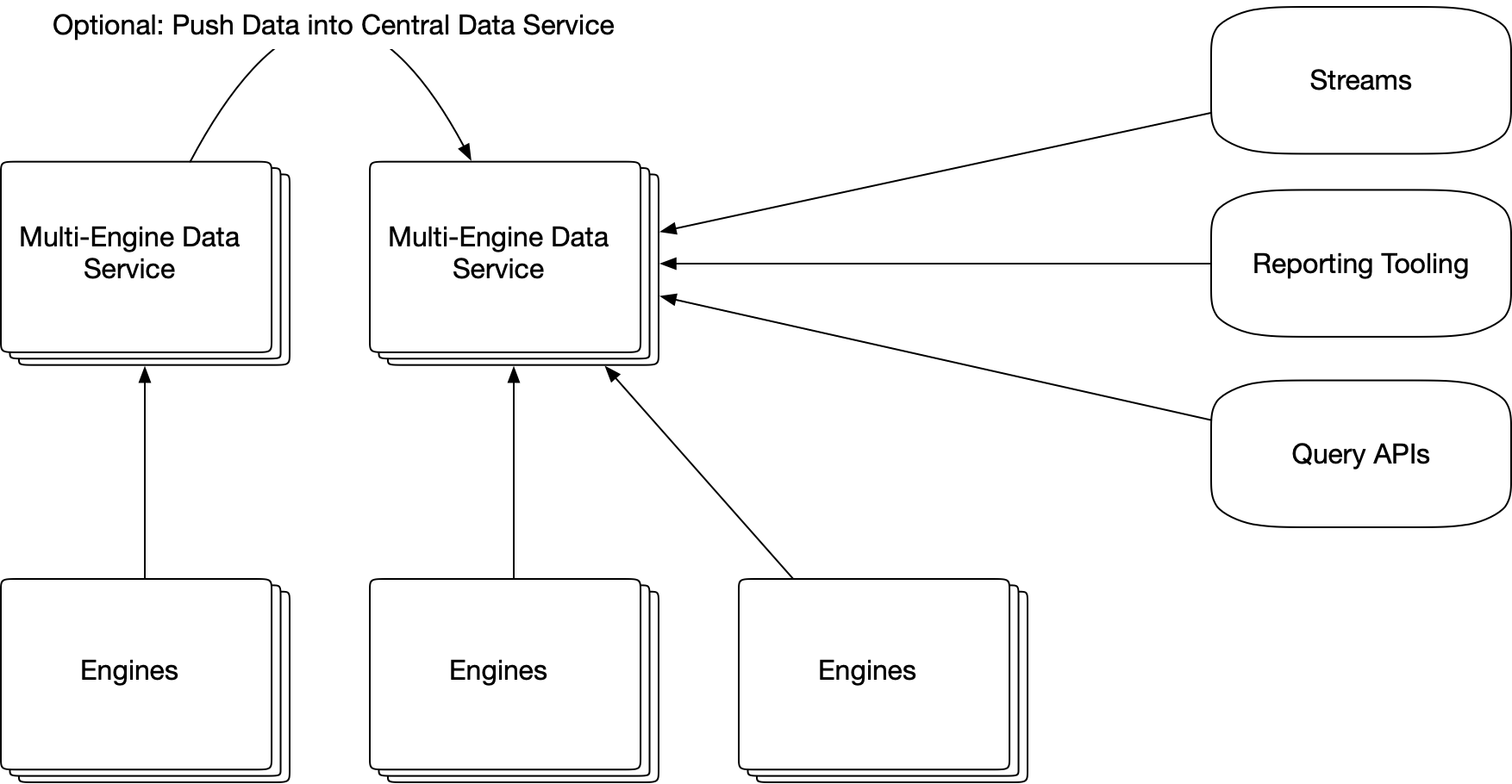
It could be used for a single engine, a cluster, or many different microservices that are built with a camunda engine.
We have been calling it the “Multi-Engine Data Service”, where it provides a custom history back end for the engine and is fully integrated into the camunda transaction system.
some of the features:
-
Works with Camunda Run, Spring Boot, and other core camunda distributions.
-
For developers building custom APIs, it provides modernized “DTOs” for all history events.
-
In additional to all history events, Deployments, Deployment Resources, Process Definitions, Decision Decisions, and Decision Requirement Definitions are all sent to the service. (Process Definitions are additionally parsed into JSON, so you can natively query for history data based on BPMN configurations in the XML: Example: “Find all activity instances where the activity instance has a Start Event Listener that executes Javascript and contains […this…] snippet of code”).
-
All history gets tagged with the engine, cluster, transaction id, etc. The purpose of the design is to support distributed history that can be collected into a single queryable source (including realtime)
-
The history data supports complex join scenarios and nested data structures with all history events. So you can easily ask for data such as: "Give me all process instances that have JSON variables with the property price between 1$ and 100$, and return process variables, activity instances, and incidents for each process instance).
-
JSON variables and other complex Variables are stored in queryable structures rather than camunda’s byte arrays: therefore you can query Spin/JSON variables in their JSON formats.
-
Robust security filtering is provided as part of the History Service, so you can create complex security policy rules for data access that were not previously possible in Camunda’s History Services. (nested AND and OR queries, Identity Links logic, JSON variable data, Other Java Object data (such as custom business objects used during a process instance, etc). All of this allows you to create security filtering rules that is executed at the DB level and is agnostic to Camunda’s users, roles, groups, etc.
-
The history data gets stored in MongoDB so you can take advantage of all of the Aggregation Framework capabilities and Change Streams.
-
You can connect your tools such as Grafana, Tableau, PowerBi, etc directly to the data and query in realtime.
-
Highly flexible Data Importer used transfer of data from existing Camunda instances into the data service. This allows you to create highly customized import queries from your existing camunda engines and import into the new service.
–
The overall goal of the build was to create the following capabilities:
- Disconnect from the SQL structures enforced by the engine
- Enable complex business queries in native formats that all support realtime querying
- Provide a camunda-agnostic data query filtering and optional security layers that can enforce the very common complex security rules that the built-in Camunda Authorization system cannot support.
- Bring together data from any engine regardless of location and use.
- Support non-persistent engine scenarios such as single execution engine life cycles (CLI executions, etc).
- Connect existing organizational report tooling to these realtime datasources: Grafana, Tableau, PowerBi, Metabase.
–
So we are looking for some testers from groups that have larger sets of deployments. Looking to expand the usage and grow its abilities.
If you are interested please let me know!

 Maybe you could start with a simple readme that explains the user side of things to have something to link to?
Maybe you could start with a simple readme that explains the user side of things to have something to link to?