Hello there!
I’m quite new to Camunda and have a question about how to do model back-off retry of a task. I will try to state the question as simple as possible.
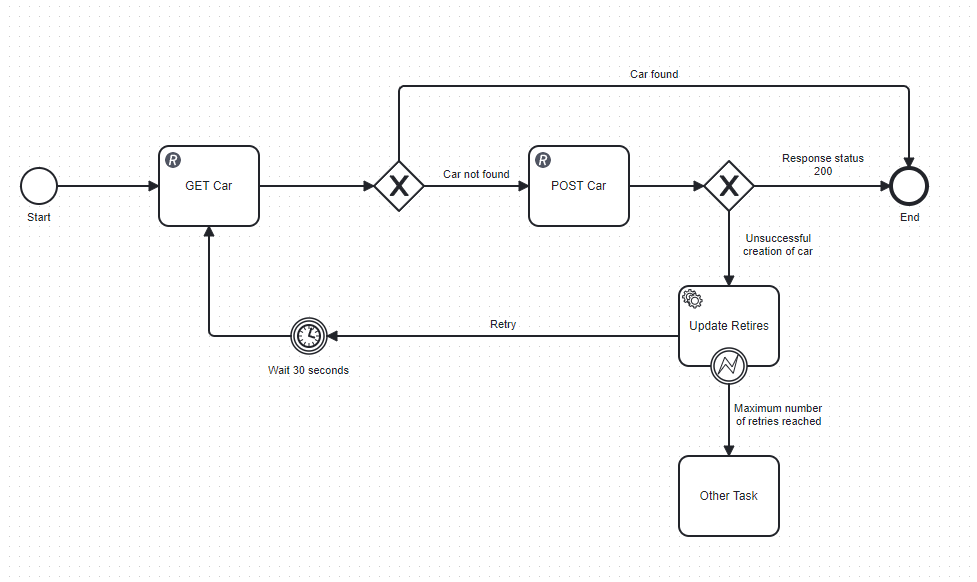
I have made a very simple example which should be self-explanatory.
The way I would like the back-off retry for a task would work is that if we don’t get a 200 response when doing POST car, then we want to wait 30 seconds and try the GET car again. The retry process should be done a maximum of 2 times.
Example SUCCESS:
- GET Car → No Car found
- POST Car → 200 status
- End
Example FAIL:
- “GET Car” → No Car found
- “POST Car” → 400 status
- “Update Retries” increments the retry counter from 0 to 1
- Wait 30 seconds
- “GET Car” → No Car found
- “POST Car” → 400 status
- “Update Retries” increments the retry counter from 1 to 2
- “GET Car” → No Car found
- “POST Car” → 400 status
- In “Update Retries” the number retires has reached already 2, so move on to “Other Task”
What I need help in understanding is the following:
- Where should I initialize the variable “numberOfRetries”? Should I add another task before “Get Car” where I initialize numberOfRetries=0, or is it a better way of doing it?
- How should the script (using FEEL expression) in the “Update Retries” look to increment the “numberOfRetries”? And how should the “Error Handling” of it look to make it trigger when “numberOfRetries” becomes larger than 2?
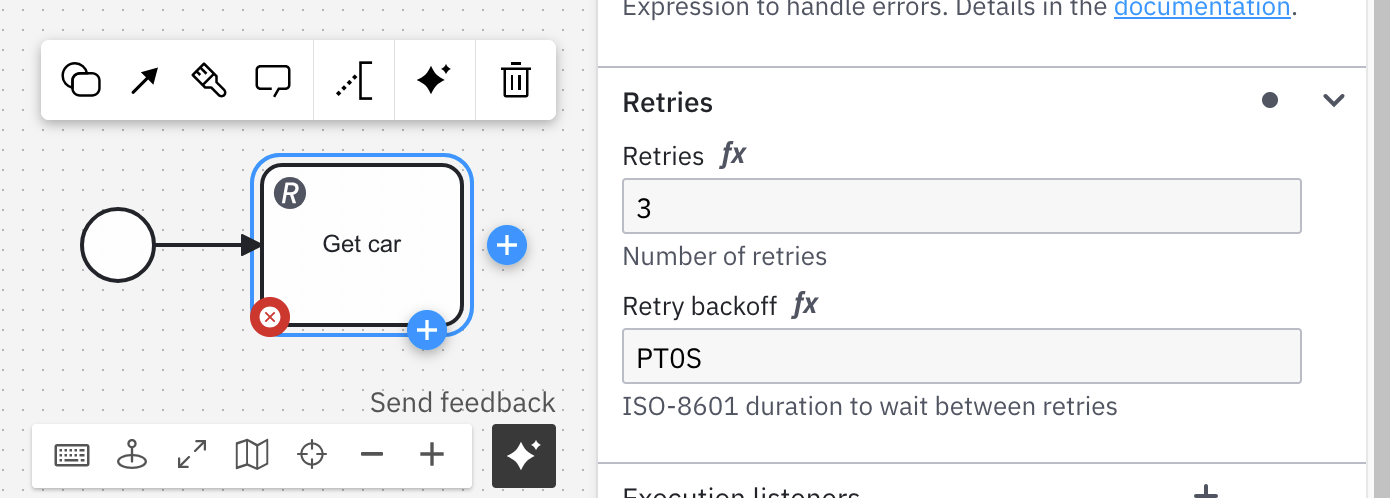
Hi @vorbrom, welcome to the forums! Retries are built in to the REST connector that you are using in that model:
You can read more about how it works here. You can set the number of retries using a variable or a hardcoded value. By default, there are 3 retries with no backoff period. In short, Camunda will decrement that value after each failed attempt; however, it will raise an incident if the retries fail, not continue on with the process.
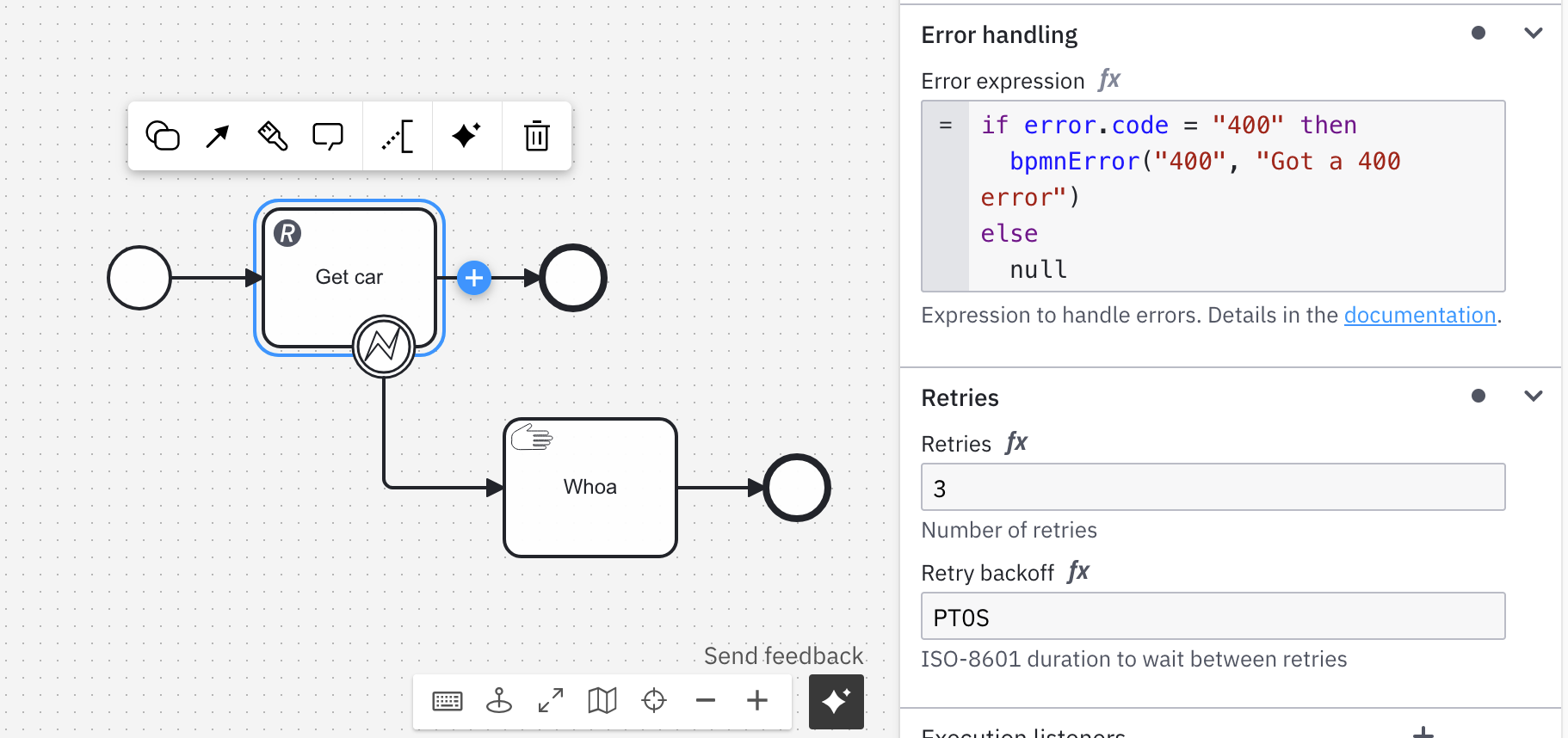
In order to achieve that, you need to combine the error expression with BPMN error handling. It’s always best to explicitly model these scenarios instead of hiding it behind implementation details.
I see, that is a nice feature. But I don’t see how to apply it to my case.
The thing with my case is that I will have multiple processes running at the same time.
So there is a chance that two processes at the same time do “Get Car”.
Both of them get “No car exists” so they both go to “Post Car”. One of the processes is first with doing “Post Car” and that is successful, but the second one process is unsuccessful as now the Car has already been created (the Car is unique so it cannot be created twice).
(OR there is a case where the “Post Car” simply fails for some reason, but we don’t know if this is because some other process has created a Car already OR if it is because the API failed for so unknown reason)
In this case we then need to go back to “Get Car”. Here we should have a value that we have tried everything 1 time already. So now we are doing everything all over again.
If “Get Car” is found we move on and everything is great.
But if we get that the car has not been created once again (maybe the API failed earlier for some unknown reason) then we will get to the “Post Car” again and then we want to see that we have been through the entire process already, so this time we will create an error if it does not work this second time.
Hi @vorbrom - correct, this only works inside of a single process instance, which is what your first post seemed to be about! Managing this between multiple running process instances is another matter entirely! The back-off/retries is only for that instance of that task.
I think reviewing some of the best practices documentation is a good first step here. The high level answer is idempotency. For instance, in the situation where two processes get “No car exists” then both try to create it, if your endpoint is idempotent than a duplicate car won’t be created. You just need to make sure an error isn’t returned to the process, or that the process otherwise handles it. (One way to handle it might be to have the API return HTTP 409 Conflict, and to handle that in the error expression. One advantage of this approach is you can easily see how many times this conflict has occurred in the process history.) If the next step is to fetch the car again, then both processes will loop back to fetch the car and proceed as normal.
In other words, it doesn’t matter to the process which instance created the car, and your application is designed with the understanding that race conditions like this may exist and is written to handle it gracefully.
Hope that helps!