I am using the most recent version of the helm repo: GitHub - camunda/camunda-platform-helm: Camunda Platform 8 Self-Managed Helm charts
I am using kind for running Camund on a standalone k8s cluster according to this documentation:
Using this values for helm: https://github.com/camunda/camunda-platform-helm/blob/main/kind/camunda-platform-core-kind-values.yaml
Whatever I do - whatever - the camunda doesn’t start.
I have 32GB and 8 Cores (assigned to the kind docker container)
I have 2 worker nodes attached to kind
I tried different (random) version of the helm charts
Can someone please confirm that this is working? I don’t want to jump into debugging anything if I am not the only one who can’t fire this up
Thank you.
Hi @DerHarry , welcome to the forums! It should be working. I am going to give this a test as soon as I can! Can you share any additional information you have, such as any errors you see in the logs? Do you see the services running, or do they refuse to start at all? Or is the issue that they are started but you cannot connect to them?
Hello @nathan.loding Thx for your reply.
I followed everthing by the letter. If you open lens you well see pods are spaning but they will never get “green” (in other words - they will never go in the ready state. They are running - but not answering.
Willing to help.
Did you change any values, or use the camunda-platform-core-kind-values.yml exactly as you pulled it from that repository?
Sure. Als I told
Do you want a test project
Including a Makefile?
“make cluster”
@nathan.loding are you interessted in jumping in a 10min call with me?
Willing to schedule a meeting with you.
I have everything setup and can provide you with an insolated test project.
Hi @DerHarry - thanks for the offer, I may take you up on that. I will be doing a bit more testing with KIND early next week and will let you know my findings, and we can go from there!
I’ll poke you on LinkedIn an then you can decide about the when and the how.
I have a Makefile + some auxiliary tools to reproduce the issue.
Willing to help! Have a nice weekend.
H.
1 Like
Hello @nathan.loding ,
I can block my Friday evening (EU time) and we can have an investigation on this. Poke me here or on LinkedIn if you can find time.
Greetings.
1 Like
Hey @DerHarry - thanks for the patience. I did run into some issues getting everything working following that guide, and I’m working through troubleshooting them. While I continue that troubleshooting, I’m curious if you can share any of the following:
What pods aren’t starting? Or is it a bit random?
What warnings or errors do you see in the Kubernetes event stream? (kubectl get events --field-selector type!=Normal)
Hello Greetings,
I just found out that you updated this file - https://github.com/camunda/camunda-platform-helm/blob/163f8be90bde9803b484973410c16d605caaebdd/kind/camunda-platform-core-kind-values.yaml
It’s still not starting.
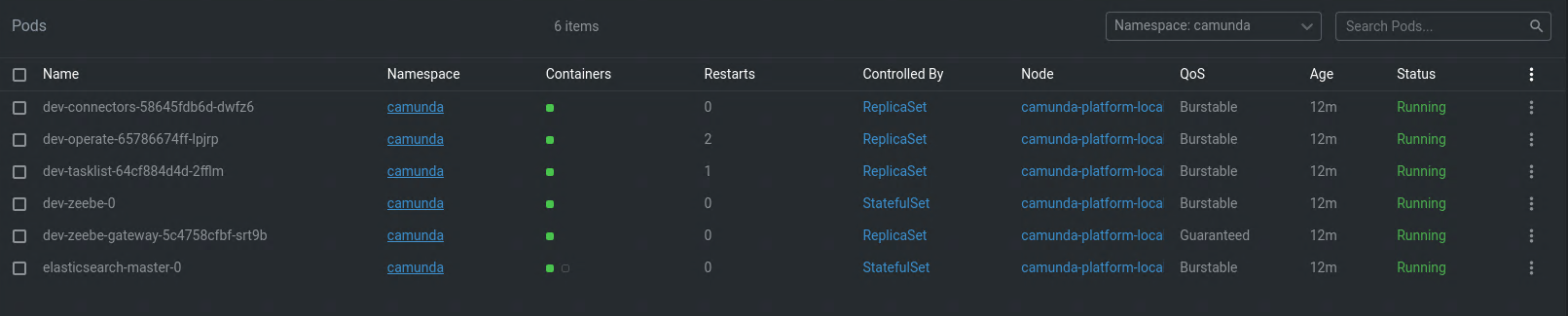
kubectl --namespace camunda get events --field-selector type!=Normal
LAST SEEN TYPE REASON OBJECT MESSAGE
9m22s Warning FailedScheduling pod/dev-connectors-58645fdb6d-dwfz6 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
9m22s Warning FailedScheduling pod/dev-operate-65786674ff-lpjrp 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
67s Warning Unhealthy pod/dev-operate-65786674ff-lpjrp Readiness probe failed: Get "http://10.244.0.3:8080/actuator/health/readiness": dial tcp 10.244.0.3:8080: connect: connection refused
40s Warning BackOff pod/dev-operate-65786674ff-lpjrp Back-off restarting failed container operate in pod dev-operate-65786674ff-lpjrp_camunda(4802fd73-0b19-4d10-9918-71338a1aafc4)
9m23s Warning FailedScheduling pod/dev-tasklist-64cf884d4d-2fflm 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
24s Warning Unhealthy pod/dev-tasklist-64cf884d4d-2fflm Readiness probe failed: Get "http://10.244.0.8:8080/actuator/health/readiness": dial tcp 10.244.0.8:8080: connect: connection refused
9m23s Warning FailedScheduling pod/dev-zeebe-0 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
9m23s Warning FailedScheduling pod/dev-zeebe-gateway-5c4758cfbf-srt9b 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
41s Warning Unhealthy pod/dev-zeebe-gateway-5c4758cfbf-srt9b Readiness probe failed: HTTP probe failed with statuscode: 503
9m23s Warning FailedScheduling pod/elasticsearch-master-0 0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling..
Greeting,
LOL and now … out of the blue … everything is green
I consider this solved - but super super super unstable
system
August 11, 2023, 9:26pm
14
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.