Hello,
I’m putting together a demonstration workflow for my company. The aim is to find out what benefits using multi-instance tasks/subprocesses might bring us, as opposed to handling the one input → multiple outputs nature of some workflow steps entirely inside our microservices by returning multi-resource IDs as single messages from those steps, like we do currently.
I’ve been trying out different ways to map variables, aiming to minimize the amount of input/output parameter mappings, all the while trying to also minimize the changes needed to our zeebe client library, which can currently only return work results in the variable body, and some extra information in the variable headers.
During this process I noticed something that confused me, and seemingly contradicted the documentation, in particular that of Variables.
This is the sentence I’m confused about:
If no output mappings are defined then all job/message variables are merged into the workflow instance.
If I set up a workflow that looks like this
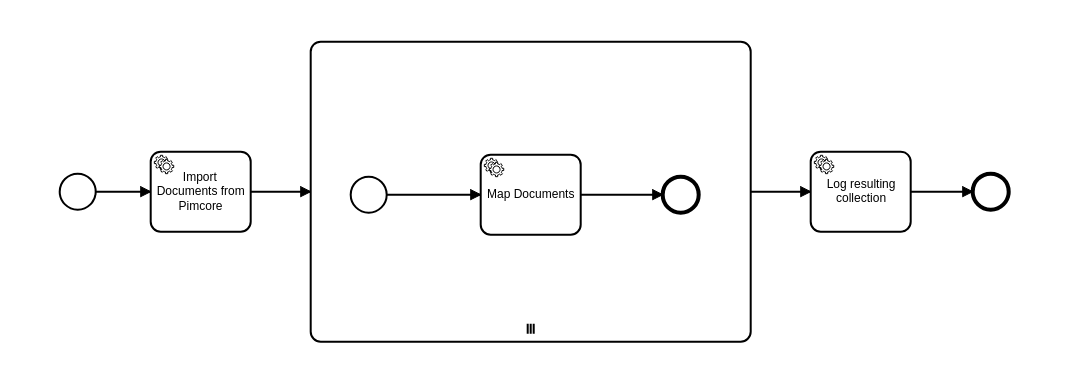
And map the variables as follows:
task preceding multi-instance subprocess:
output mapping: body -> items, headers -> headers
multi-instance subprocess:
input mapping:
input collection: items
input element: item
output collection: results
output element: body (I'm trying to save i/o mapping inside the SP)
output mapping: results -> results, headers -> headers
first task of SP (in our case the same as the last task):
input mapping: item -> body, headers -> headers
last task of SP:
output mapping: body -> body, headers -> headers
first task after SP
input mapping: results -> body, headers -> headers
With this setup, the workflow works as expected, and the microservice of the last task logs body as an array containing the collected work results, and headers as it was passed and modified through the workflow.
HOWEVER
After confirming the above as working I spotted a mapping that seemed redundant, in particular
last task of SP:
output mapping: body -> body, headers -> headers
So I removed this identity mapping. This broke the workflow, with the following effects
- The microservice of the last task (following the SP) logged
bodyas an array containing allnulls (resultsmapped tobodyby the last task input param mapping) - The Variables table of
zeebe-simple-monitorshowedbody : nullin the scope of the task inside the SP, once for each instance created in the SP headerdidn’t contain information from the SP either and would’ve been null as well if our client didn’t put in thebreadcrumbIdat every task
The sentence I quoted from the Variables doc leads me to believe that the identity mapping right before the subprocess end event shouldn’t be necessary, but it definitely is in this case. It also seemed to me that the following paragraph
In case of a sub process, the behavior is different. There are no job/message variables to be merged.
didn’t apply to my issue inside the subprocess, but was referring to the step out of the subprocess, i.e. the output parameter mapping one can edit when clicking on the SP.
It’d be great if someone could explain to me where the issue lies; either in my understanding of variable mappings, or between the behavior and the documentation. Thanks in advance!