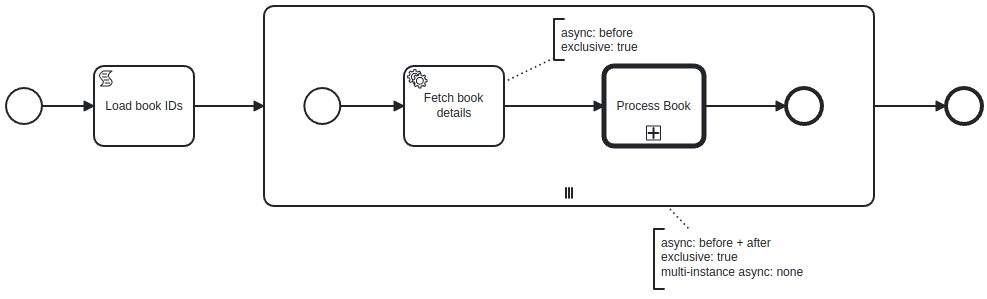
@MaximMonin @jonathan.lukas Thanx for the pointer to split it up into chunks.
However, after some testing the memory pressure issue stays (even at only 100 book IDs in a chunk) the same or got even worse (I have no real numbers since the camunda-bpm-run Docker image doesn’t contain tools like jmap or similar to get a head dump to analyze).
The tip for creating a separate transaction before the end event in the parallel sub-process did not help to avoid OptimisticLockingExceptions at all. Number of occurrences stay roughly the same here.
However, after configuring GC logging into a separate file, I saw a lot of “G1 Humongous Allocation”, which indicates to me that very large objects are being allocated very often, which I couldn’t make any clue about at first.
Then I thought about the loop itself and as I am not at all into the Camunda multi-instance implementation code base, I thought maybe it’s the big list of book ID’s (actually UUIDs), which I have stored as a serialized ArrayList variable.
In a new version, I integrated Redisson (using their Spring Boot Starter), offloaded the list itself and instead of using collection and elementVariable in the multi-instance, I just have my cardinality and load each book ID from Redis inside the sub-process using the loopCounter as the list index.
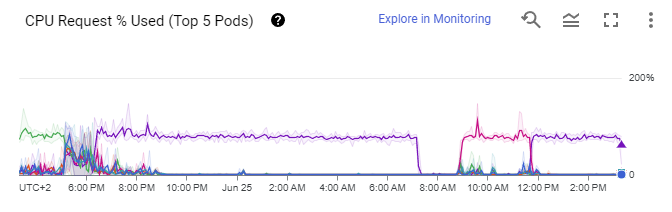
That alone brought pressure by GC down a lot. I am still running with sequential multi-instance for now, but after ~5000 iterations, there is barely any GC activity, only a normal evacuation pause every 7-8 seconds. CPU - of course - also went down a lot. The load on the PostgreSQL is now one of the bottlenecks.
Overall, performance of this approach is the fastest so far and the most consistent / predictable (sub-process executions / second).
I will re-try with parallel execution as well to see if this approach actually does anything to the OptimisticLockingExceptions, but I doubt it.
Nevertheless, I am already taking the following learnings here:
- Never loop over large lists (use an external fast data source to iterate over reliably)
- Inside a loop, restrict to absolutely necessary transaction boundaries and number of variables (if variables are necessary, remove them before the next transaction boundary/commit, so that they do not get persisted)