Hi All,
I have a pattern to share based on @Bernd’s recent talks re orchestration across distributed micro-services.
Problem Statement
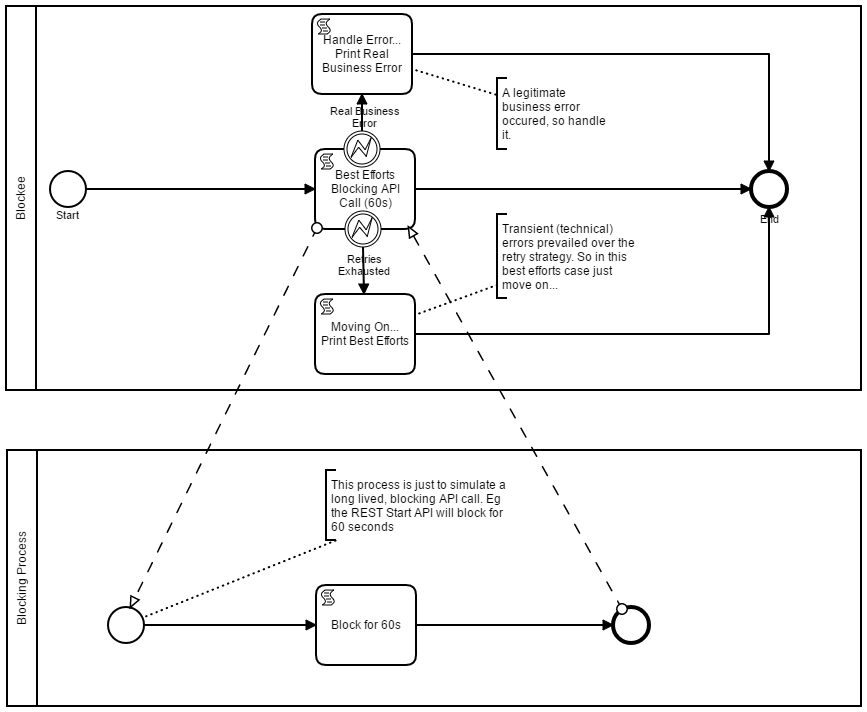
Sometimes we want to orchestrate across a remote service as a client of the service. But what happens if that service is down, and/or beyond our control? One option is to wait until the service resumes. Another option could be to continue without the service output. A real world example could be a gecoding validation service. If the service is down, but I already have a candidate location, then why wait, I could choose to take the business risk and continue with what I have been given.
Implementation
There have been numerous threads in the forum regarding the connector architecture. One of the challenges in the connector library, is its difficult to set the socket timeout. By default, it uses the Apache HTTP Client library which tends to wait ‘forever’. Hence the first part of this pattern makes explicit use of the http client in order to set sensible (more agressive) timeouts. Thus we can set an explicit timeout strategy.
// // Setup the request with custom timeout values. // def timeout = 10; def RequestConfig config = RequestConfig.custom() .setConnectTimeout(timeout * 1000) .setConnectionRequestTimeout(3 * timeout * 1000) .setSocketTimeout(6 * timeout * 1000).build(); def client = HttpClientBuilder.create().setDefaultRequestConfig(config).build();
Next we can work with the retry strategy. When these service tasks use an asynchronous continuation, we can set a retry strategy. I was inspired by Bernd’s code and followed his implementation. Essentially the code interrogates if its operating within the job executor. If it is, and its on the last try, then intercept the retry mechanism to route the process down a different path. The easiest way to do this is to throw a BPMN Error (see code snippet below). I’ve seen lots of attempts to use an interrupting timer to achieve this. My conclusion is don’t mix process constructs with thread execution constructs. A process timer should not be used for interrupting threads. Its intent is to interrupt at the process level.
//
// Check to see if we are in a job executor job context. If so and we are down to the last retry,
// then take control to catch any exception, and convert to a BPMN error
//
def jobExecutorContext = Context.getJobExecutorContext();
if (jobExecutorContext!=null && jobExecutorContext.getCurrentJob()!=null) {// // then this is called from a Job, so if on the last retry... // if (jobExecutorContext.getCurrentJob().getRetries()<=1) { // // attempt the task service, if it fails, then retry is exhausted so throw a BPMN Error... // try { doExecute(execution); } catch (BpmnError bpmnError) { // // Just rethrow the business BPMN Error // throw bpmnError; } catch (Exception ex) { // // Create a closed incident and raise a BPMN Error indicating out of retries... // def runtime = execution.getProcessEngineServices().getRuntimeService(); def incident = runtime.createIncident("FAILED FAST", execution.getId(),"Configuration Message",ex.getMessage()); runtime.resolveIncident(incident.getId()); throw new BpmnError("RETRIES_EXHAUSTED_ERROR"); } // // Otherwise the last try was successful, so just return to the engine to complete the task // return; }}
A reference implementation is provided in the attached model. To use, just deploy the model. There is a dependency on the Apache HTTP client library, so ensure the client library is installed in your application server. The blocking process is just to simulate a blocking API.
Summary
Use this pattern and techniques to more aggressively timeout on remote calls. If the call is best efforts, after the retry strategy has run, use this pattern to support best efforts and move on.
regards
Rob
BlockeeIII.bpmn (17.5 KB)
