Hi there,
I came across some special behaviour today concerning performance which I cannot explain to myself. Hopefully someone here can help me out.
My setup is a process which instantiates other process instances. I’ll call the first one the “starter process” (process A). The process instances started by the starter process are all of the same definition (process B).
Process A determines daily at a specified time for which business objects there is a process instance of type B to be started. The process engine is embedded in my existing application using Spring.
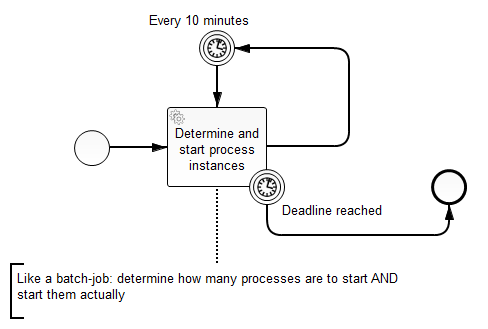
The process definition started by the starter process has the “asynchronous before” set to true in the start event so the transaction of the service task in process A is not affected by the execution of all the other process instances (started from the service task).
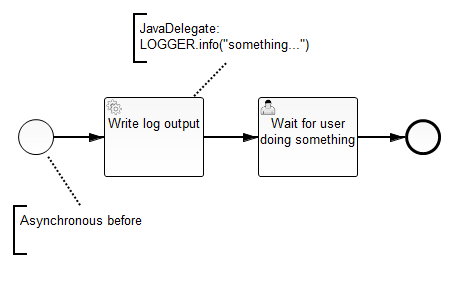
Now the strange thing I encountered (which is hopefully easily explainable):
When process A is started, its only service task is entered at first. As said - it determines a bunch of business objects. For each of them a process instance of type B is started using the Camunda runtimeService.startProcessInstanceByKey in Java. I’m doing tests with starting 500 process instances. The service task of the started process B does nothing more than writing a single line to the log file.
According to the log file I can see 100 lines per second.
Process A moves on to the intermediate timer event and waits some time. When the due date in process A is reached the token moves on again to the service task and a bunch of more (again 500) business objects are determined where a process instance is started for each.
Now the log file has an output of only 23 lines per second.
So the first run was four times faster than the second run and all of it’s successors.
Please help me - what is going on there under the hood, that makes such a difference. Or maybe you could help me to tweak some parameters to get rid of the problem.
In productive use there will be thousands of process instances being started in this manner and they will do lots more than just writing to the log file so the runtime problem is getting even more significant.
The started proccess instances of type B are from a long running type - e.g. 2 months at least.
Every help is really appreciated!
Cheers Chris
Hi again,
unfortunately there was no reply yet.
What can I do, to make people respond?
Is the problem explained so badly? Ist the solution so obvious? What more information is needed?
I try to create a unit test to make this issue repoducible.
Hi @TheFriedC Sorry for not looking into your problem earlier. Did you know that we also offer enterprise support with guaranteed response times based on SLAs?
Are all the instances of the second process completed when the service task in the first process is executed for the second time?
Hi Daniel,
thanks a lot!
The process instances are not completed. The token is waiting for the user-task to be completed.
I’ll remove the user task and let the process instances of process B being completed automatically. Let’s see if it makes the difference.
I do not think that that makes a difference. The critical question for me is whether all instances started in the first batch have successfully reached the usertask when the second batch is started?
Yes, they all have reached the usertask before the second batch is started.
Good. Are you familiar with the mechanics of the Job Executor? You could read up on that here: https://docs.camunda.org/manual/7.4/user-guide/process-engine/the-job-executor/
Thanks for pointing me into this direction - but honestly, I do not see the point.
Why is is there a difference if the token runs directly from the start event into the service task which starts all the other process instances OR if is is timer triggered?
The number of entries in the job table cannot be the problem because the difference is one single job (the timer).
The service task for starting the new instances creates the jobs to start the new process instances and is completed. Then the job executor takes these jobs and executes them (wow - this is what the name is standing for  )
)
In one case the execution is 4-5 times faster than in the other case but I cannot see why.
Hi,
One observation I will make is when you start process A, process A is running in a client thread and thus all job executor threads are available to execute Process B.
On the second iteration, your Process A instance is running in the context of a job executor thread and thus there will be one less job executor thread to run Process B instances. Hence if there were four threads configured in the job executor, you may get a 25% reduction in throughput.
Thus not necessarily a reason for what you are observing, but an example of some subtlety under the covers. Perhaps you could change the size of the job executor thread pool to see if it makes any difference…
regards
Rob
1 Like
Thanks Rob for your input.
The maxPoolSize of my job executor is already configured for 50 threads. I cannot explain the reduction of 75% in throughput.
What I thought about is that proces A is running in a loop. So the timer triggers and the execution ends up waiting at the timer again.
I did a little change in my test setup and removed the loop to see how the behaviour changes if there is only one timer.
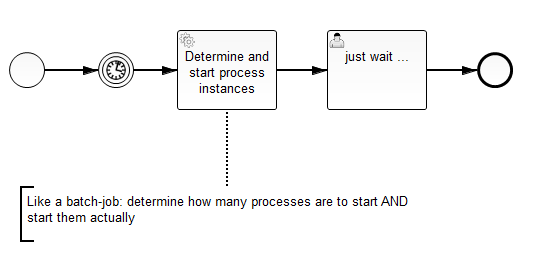
It speeds up the execution of the process B instances and nearly doubles the throughput to approx. 40 instances per second.
Nevertheless I still cannot understand why this limits the throughput so drastically.
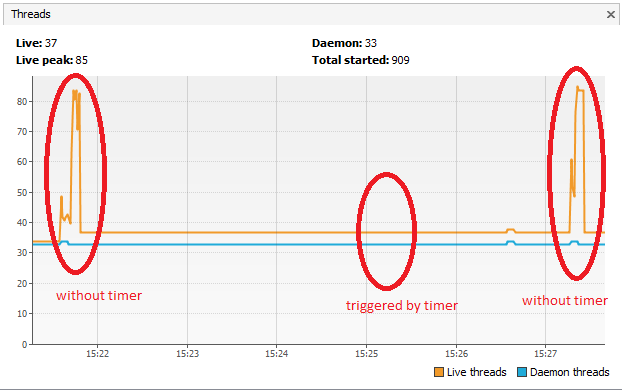
I made a new discovery (at least it is new to me):
When the process instances of type B are created timer triggered - there are no new threads created. It seems they all use the same single(?) thread.
At the start of process A when the servicetask is entered directly the full amount of configured threads for the jobexecutor is created.
The camunda user guide (see link in post of DanielMeyer above) says:
…using an asynchronous continuation, you can distribute the work to this thread pool
I configured the service task of process A with both - asynch before and asynch after but this does not change the behaviour. This try was out of some desperation because I think that the “asynch before” on the start event of the process B should already do the trick.
So now my question:
How do I configure my process(es) that the full job executor pool is used for my started process instances?
Hi perhaps a job executor parameter to look at is the number of jobs fetched per iteration (maxJobsPerAcquisition). If this was say set to 3, then your throughput will be limited to 3 jobs per DB select. If your service tasks run faster than the DB select, then you will never see more than three threads in use.
In my experience, a smaller number is good for large clusters, a larger number is better for single nodes…
regrds
Rob
Hi Rob,
thanks again for your reply.
If I do get it right - tweaking the maxJobsPerAcquisition would increase the amount of jobs handled per thread. Yes - this would increase the throughput to a specific point.
But my real problem is, that the thread pool is not used in its entire capacity when coming from a triggered timer. I would expect the JobExecutor to create new threads when the currently used thread has reached its max job number.
A logical consequence for me would be - the lower the value of maxJobsPerAcquisition is - the more threads are used.
Hi,
Not quite. As I understand the jobexecutor (on Tomcat), there is a single job aquisition thread. Its role is to poll the job table for jobs to be done. Hence the sequence is;
wakeup->select and lock maxJobs from jobs where ready> Hand job IDs to threadpool queue->Loop.
Hence you cant process tasks faster than this serial acquisition loop. Now the database select is expensive relative to CPU compute. Hence fetching 3 jobs at a time could introduce significant latency into the job acquisition cycle as opposed to fetching 30 jobs at a time. However remember than fetching jobs faster than the thread pool can process them is wasting resource as the job acquisition thread will block if the threadpool is full. Hence you may need to find a sweet spot…
regards
Rob
Thanks Rob to clarify that.
I still cannot solve my problem with this knowledge. I use Tomcat too. Did configure a higher number for maxJobsPerAcquisition - does not affect the use of threads in my testcase when coming from the timer event.
But despite of all this the main question is still left:
What is the difference between coming from a process start event (full use of the configured job executor pool) and coming from a timer triggered event (no use of the pool)?
UPDATE:
I found out that the “async before” AND the “exclusive” (default to true in camunda) property were set on the start event of process B.
When “exclusive” is unchecked, the whole thread pool is used (when coming from a timer event).
I thought the async continuation would split the process B instances from the process A instance anyway. But somehow the process B jobs are still bound to the timer job of process A and executed sequentially.
Any hints on that one?
 )
)