With https://app.camunda.com/jira/browse/CAM-6369 now implemented in 7.6, has there been any plans to support similar functions for User Task Completion?
Hi @StephenOTT,
There are currently no such plans.
How would that feature look like, i.e. which variables should be returned? What use case would that solve?
Cheers,
Thorben
hey @thorben
I Imagined it would work similarly to the way Start Instance functions in 7.6 with withVariablesInReturn parameter == true.
The Use case i was exploring was a purely proof of concept using a sort of Function as a Service model. Where each process instance would be a sort of Function/aws lambda/openwhisk/GCcloud function. A build on this is if Use Tasks were also supported in the same manner. This sort of extends / defeats the purpose of single purpose functions, but was just prototyping the models.
Not related to the poc above, another use case that came to mind was the ability to have returned variables from the user task (until the next wait state), so actions could be take based on the execution of the user task without having to re-query the process instance. (basically I think much of the same logic for having variables returned as part of Start Instance
Hi @StephenOTT,
Thanks for expanding on that. The process as function use case (aka fully automated processes without wait states) is exactly what we intended the new API to be for. I don’t (yet) see the necessity to have this for user tasks as well. The technical argument of saving queries could be made for any API and any related database entities. We should try to keep the APIs focused in my opinion, so I wouldn’t do this for purely technical reasons.
Cheers,
Thorben
I figured as much ![]()
The break in the chain at the moment is the ability to generate a async task to be completed by the user/updated by the user and then return a result.
Using Start Instance as functions is great!, but we cannot (at least i dont see a way? ) to have a function that is user dependent/assigned.
If a Start Instance function was used to preform some logic and then ask the user to Upload a File (hence a user task), how would you model this without the construct of a BPMN user task?
Sure, then you need a user task. And yet I argue that this is different use case where an API returning the variables would not be as useful as it is in the fully automated case.
In the fully automated case, the entity that triggers the process is typically a system (e.g. another process invoking a web service that is implemented as a fully automated process). In that case, it is a classic request-response pattern where it makes sense to return variables as the response payload.
For user tasks, I don’t see this as much. I wouldn’t consider such a process a function anymore, as the caller (i.e. the entity that started the process) does not receive the instance’s results anymore. Returning the results to the user that completes their little part of the process does not appear useful to me. This would be like continuation as a function, but I just don’t see the use case for this. From a user’s perspective, completing the task is just that. It is not about completing a task and executing the following three service tasks that calculate a certain value. That is purely an implementation detail and depends on things that the user is unaware of, for example asynchronous continuations.
@thorben okay that is interesting! So would you describe the system then as a sort of Dual capable engine? Function as a Service (for fully automated processes) and your “continuation as a function”.
So I just through this together as a fictional example to make the story a little more real.

If we looked at the above process. A message is sent or we start the process from Start Instance to "Create a new User.
Assuming it is not a message/async and we were returning variables on Start Instance, I would expect/think i would return User metadata when the process reaches the Populate User Profile User Task. If we use the above process then after submission of the User Task I would likely not care so much about returning data, but if maybe wanted to process that form data into multiple sub-profiles, and then return the IDs of each sub-profiles as part of the User Task Completion Response.
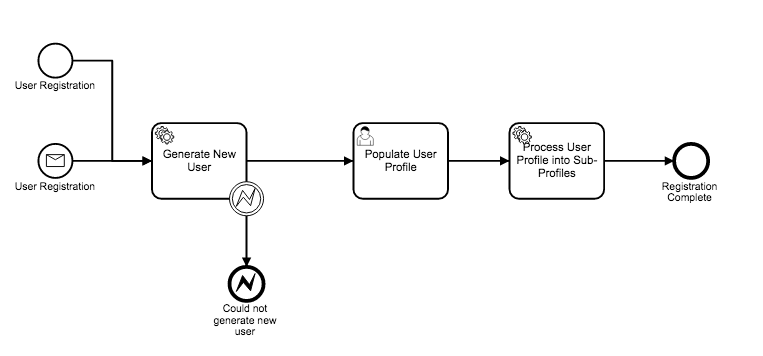
I am not arguing that it should be done this way or that this is a real or best practice. I am just trying to articulate a example where a User Task having a variable response could be valuable. @thorben if we go more strict and leave function as a service more about fully automated processes as you suggest. Do you see a model/pattern that would be used to still support “User Tasks” but in the Function as a Service context?
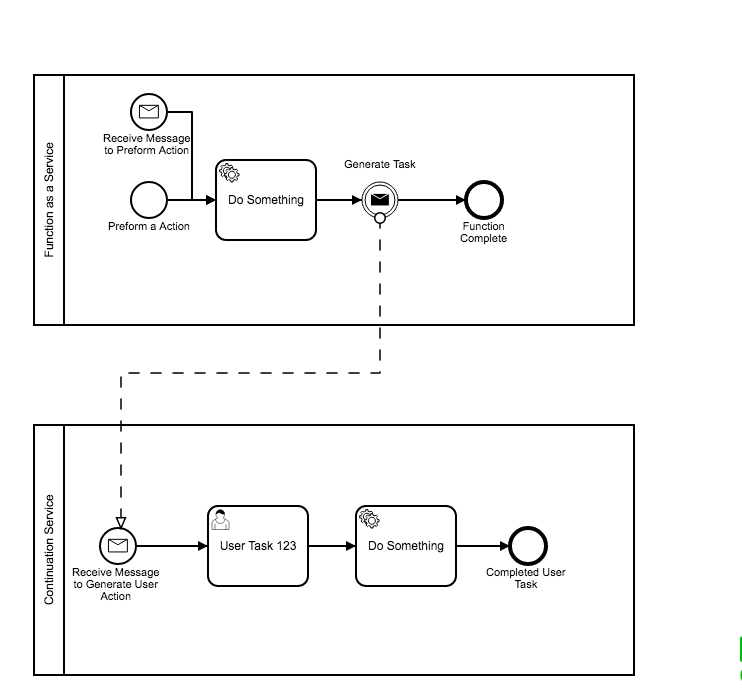
Hi Stephen,
could you get the desired behaviour by making two calls or wrapping the two calls in a helper functor? For example in a form task your javascript could submit to the task API then call the get Variables API. Would this achieve what you are after?
I do note that there is the potential for a race condition here, and that is you don’t want the process instance to end between calls…
regards
Rob
we could definitely do something like this ^
What I was exploring is using the engine as a “Function as a Service” engine. Start Instance with Variable return meets the basic needs. 7.6 provides this functions as Thorben mentions.
The “extra” is where in serverless patterns you would roll your own User Task “Engine” and build functions around persisting and managing the construct of a user task. because Camunda also provides this construct, I was looking for patterns where you could use both FaaS and the User Tasks together in a more seamless model.
This is a more broken up model where each pool could be equiv to a “Function”
But the “Continuation Service” is the special use case where there is a User Task which breaks the FaaS model of returning values.
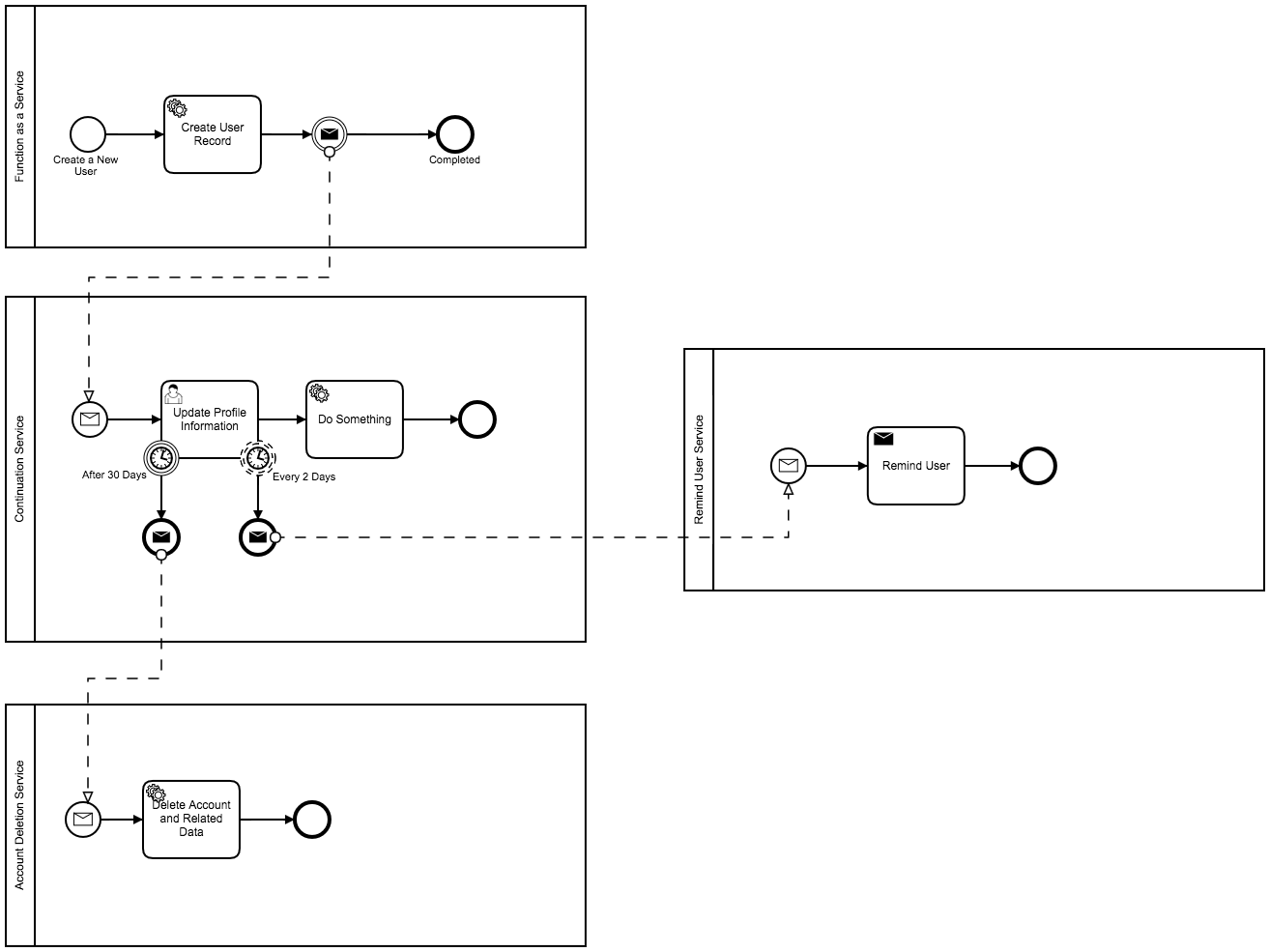
You could also build page flow with this, for example:
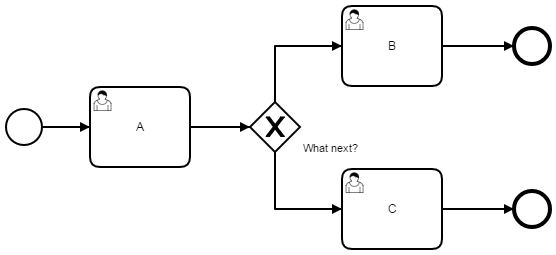
Let completion of task A return the ID of the next task and voila.
And yet I have problems understanding user task completion as a use case in a functional context. For fully automated processes, this makes sense. For user task completion, not so much. In a process-oriented context, completing a user task should be exactly this: A user signalling a completed task, providing some input. What happens next is not the concern of that user. Expecting return values based on the process model couples user tasks too much to process implementation and process engine behavior in my opinion.
I think that specific sentence is a “powerful”/good statement. So if we expand on that philosophy, then Processes can be created that are Automated/System and/or User oriented, but “next action” and “outcome of current action”, is not returned for User Tasks.
When i think of user tasks in a functional context, I think of a User Task as an action completed by a user, BUT the outcome has a effect on the system that is interacting with the user.
I think the user task could be viewed as a construct in the Functional landscape as something used for Persisting a Task to be completed by a user? As in: It is not really a functional tool. But We can already generate similar functionality with things like BPMN errors. Consider:

The Functional pool could be used as sort of form validator + data submission into a DB.
The User Task is about creating a persistent User Task that will be completed in the “future”. But the the Submission error could be validated and the BPMN error could stop the submission. But on successful submission, we don’t get the values/variables that would exist when the token reaches “Provide Success Response”.
@thorben I 100% see your point and philosophy about the what happens after the User Task submission is not the concern of the user. The pattern i am working out, is, in my scenario above: If we use a function pattern to process a Form Submission, then a user task submission is very similar, except for the User Task is a persistent “Task”.
Edit: and of course there are other variations of the above model such as calling the Function pool after the submission of the user task.
Page flow i have always had a issue with because of the complexities of “going backwards” in the flow (task lifecycle, sequence flows, skipping, re-evaluating previous submissions, etc).
Ha! Dec 1, AWS release:
funny correlation