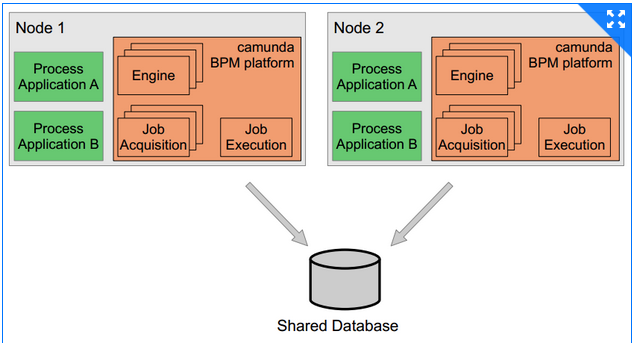
I’m intending to run a homogeneous cluster setup with multiple nodes running the embedded process engine that reference the same DB for my current use case. Can someone please explain how the embedded process engine and job executor mechanism works in this cluster? I want to ensure process instances aren’t duplicated. I will also have a long running process that will perform a check every day at 12:00am. I would like to understand how the job executor decides which node is responsible to perform this long running process as well.
With a shared DB configuration, the persisted job information’s (like user tasks, async jobs etc) for all the process applications will be stored in the shared database irrespective of the nodes. Whenever you start your container in a node, process applications deployed on that node will be registered in the Camunda instance in that node. Subsequently job executor will pick jobs one by one for the process applications deployed on that node , provided by you must set “jobExecutorDeploymentAware” to true.
Thanks for the answer prasadps and the link to additional information. One thing I still need clarification on was if there are multiple nodes with the same processes. For the example where I have that one task that gets executed daily at 12:00am and all my nodes have this one task, does one of the process engines in my nodes pick this task and perform the task?
This way the 12:00am task is guaranteed to execute once a day no matter how many nodes I have.
Hi - to clarify your understanding of the job executor, the DB maintains the set of jobs to be done with a due date. Each engine node polls the DB for the list of due jobs. An engine node will then attempt to lock a subset of this list of jobs using a DB transaction, hence only one node will actually lock the jobs and begin processing the jobs. Other nodes may get a DB exception and thus they will poll again for an updated list of due jobs.
Once a job is complete, the owning node will delete the job from the DB. The jobs are locked using a lease. Hence if a node fails and it has locked jobs, eventually those locks/leases will expire and thus the jobs become available for any other node to lock them and run them.
So in summary a DB transaction and pessimistic locking is used to guarantee single execution semantics. In addition the mechanism will self recover from node failure…